Increased usage for agents
We've raised limits for Auto and Composer 1.5 for all individual plans.
There are now two usage pools:
- First-party models pool: At launch, we included significantly more usage for Auto and Composer 1.5.
- API: We charge the API price of the model (unchanged with this update).
Composer 1.5 now has 3x the usage limit of Composer 1. For a limited time (through February 16), we're increasing that limit to 6x more.
From autocomplete to agents
Over the past few months, we've seen a major shift toward coding with agents.
Developers are asking Cursor to make ambitious changes across their entire codebase. We want Cursor to support daily agentic coding, and we recognize that developers have different priorities.
Some are comfortable always paying for the newest models, while others are looking for the right balance between speed, intelligence, and affordability. By introducing two usage pools and increasing limits for first-party models, we're supporting both approaches.
A new model for agentic coding
Training our own models like Composer-1.5 allows us to include significantly more usage in a sustainable way.
We have found Composer 1.5 to be a highly capable model, scoring above Sonnet 4.5 on Terminal-Bench 2.0, but below the best frontier models.1


We expect to continue finding ways to offer increasingly intelligent and cost-effective models, alongside the latest frontier models.
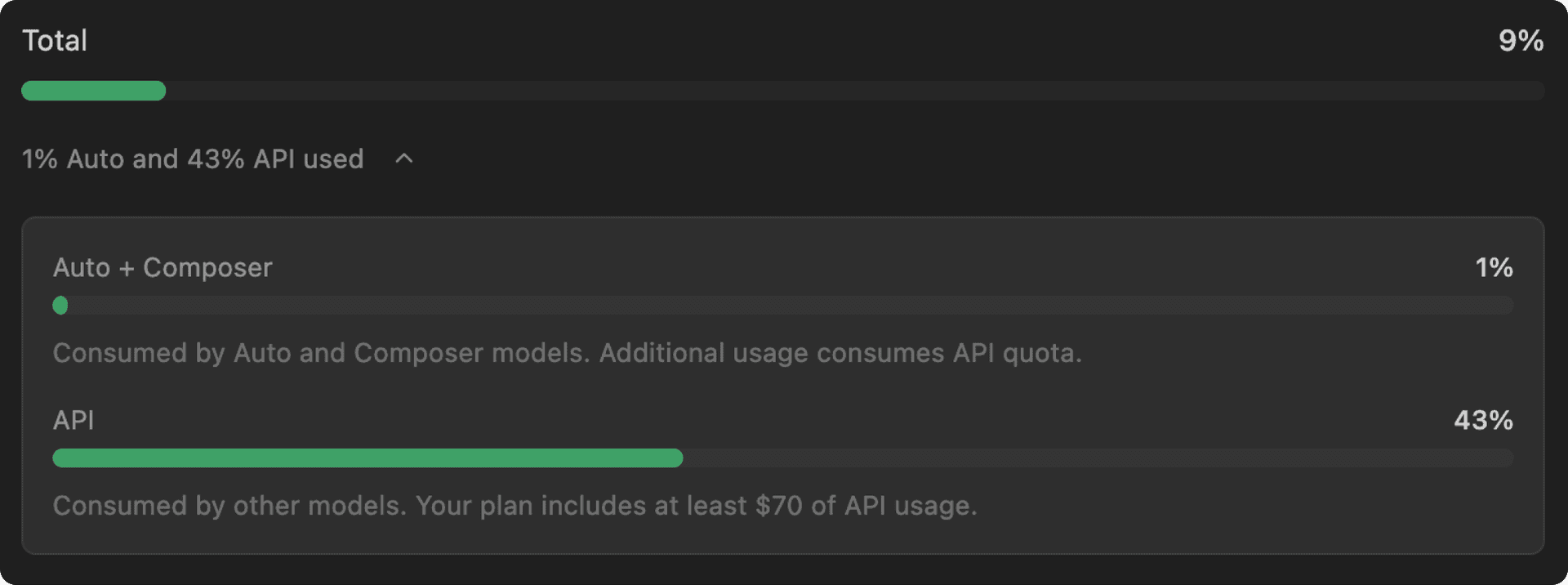
Improved usage visibility
To further improve usage visibility, we’ve added a new page in the editor where you can monitor your limits with two different usage pools:
- First-party models pool: At launch, we included significantly more usage when Auto or
composer-1.5was selected. - API: Individual plans include at least $20 of usage each month (more on higher tiers) with the option to pay for additional usage as needed. These usage limits have not changed with this update.

Try our latest model
We encourage you to try Composer 1.5 with our updated usage limits.
Both usage pools reset with your monthly usage cycle. These limits are now live for all individual plans (Pro, Pro Plus, and Ultra).
- Terminal-Bench 2.0 is an agent evaluation benchmark for terminal use maintained by the Laude Institute. Anthropic model scores use the Claude Code harness and OpenAI model scores use the Simple Codex harness. Our Cursor score was computed using the official Harbor evaluation framework (the designated harness for Terminal-Bench 2.0) with default benchmark settings. We ran 2 iterations per model-agent pair and report the average. More details on the benchmark can be found at the official Terminal Bench website. For other models besides Composer 1.5, we took the max score between the official leaderboard score and the score recorded running in our infrastructure. ↩