Composer 2 का परिचय
Composer 2 अब Cursor में उपलब्ध है।
यह कोडिंग में अत्याधुनिक स्तर का है, और इसकी कीमत 2.50/M आउटपुट टोकन है, जिससे यह इंटेलिजेंस और लागत का एक नया, बेहतरीन संतुलन बनता है। हमने this पर एक तकनीकी रिपोर्ट भी जारी की है, जिसमें बताया गया है कि हमने इसे कैसे प्रशिक्षित किया।


अत्याधुनिक स्तर की कोडिंग इंटेलिजेंस
हम अपने मॉडल की गुणवत्ता में तेज़ी से सुधार कर रहे हैं। Composer 2 हम जिन सभी बेंचमार्क को मापते हैं उन सभी पर बड़ा सुधार दिखाता है, जिसमें शामिल है Terminal-Bench 2.01 और SWE-bench Multilingual:
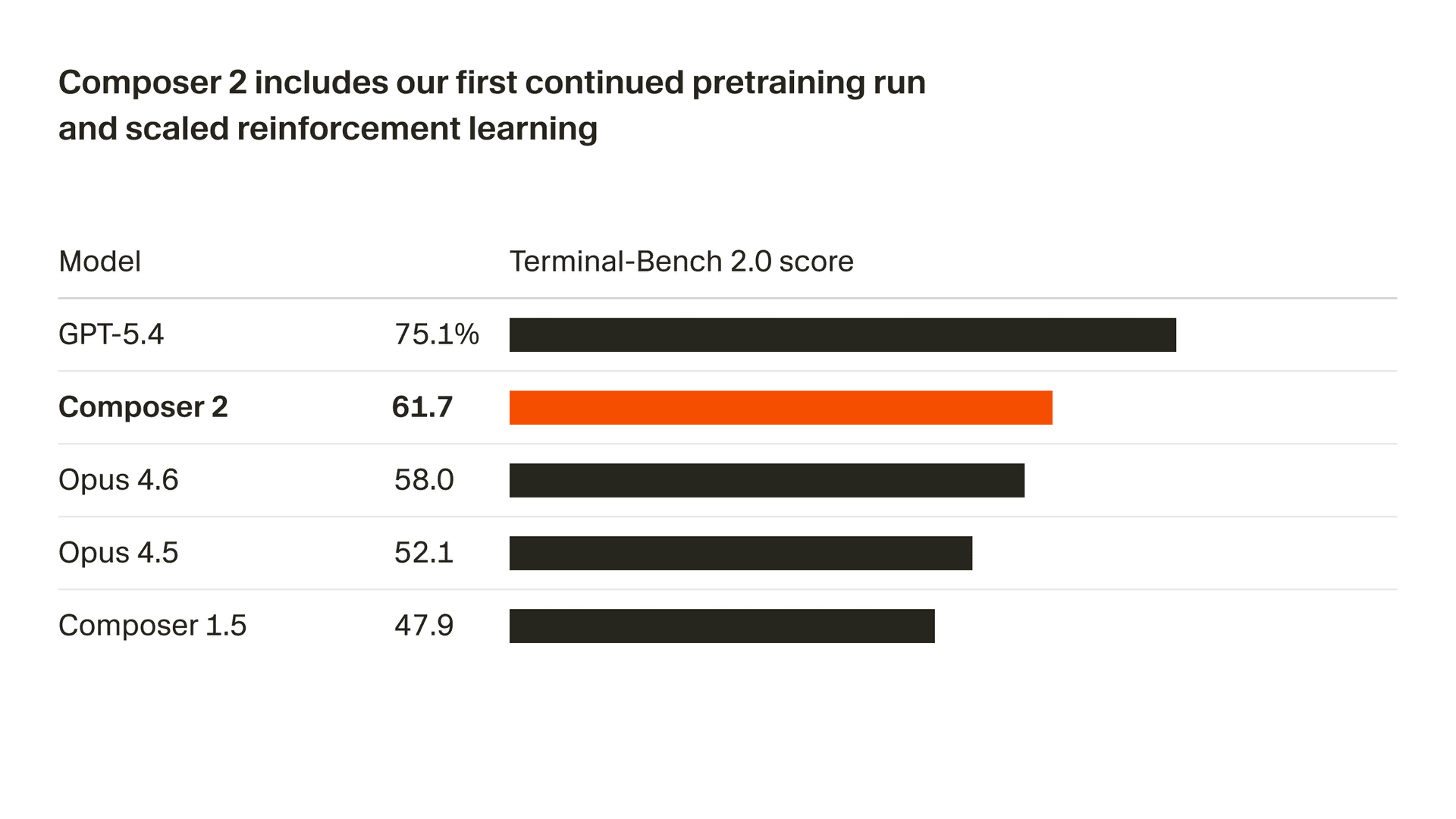
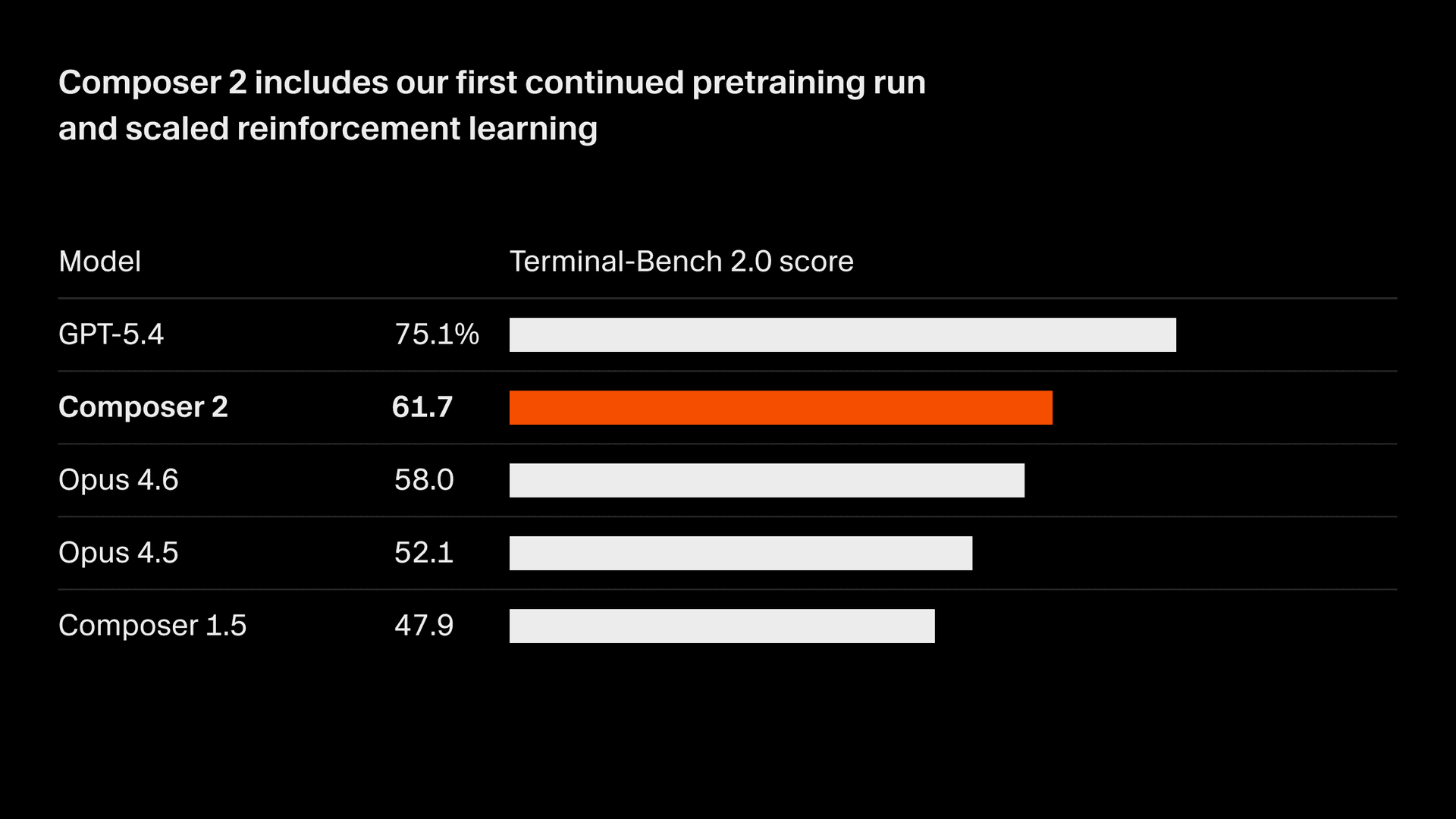
| मॉडल | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
गुणवत्ता में ये सुधार हमारे पहले सतत प्रीट्रेनिंग रन का नतीजा हैं, जो हमारी रीइन्फोर्समेंट लर्निंग को स्केल करने के लिए कहीं अधिक मज़बूत आधार देता है।
इसी आधार पर, हम दीर्घ-क्षितिज कोडिंग कार्यों के लिए रीइन्फोर्समेंट लर्निंग के ज़रिए प्रशिक्षण देते हैं। Composer 2 सैकड़ों कार्रवाइयों की आवश्यकता वाले चुनौतीपूर्ण कार्य हल करने में सक्षम है।
Composer 2 आज़माएँ
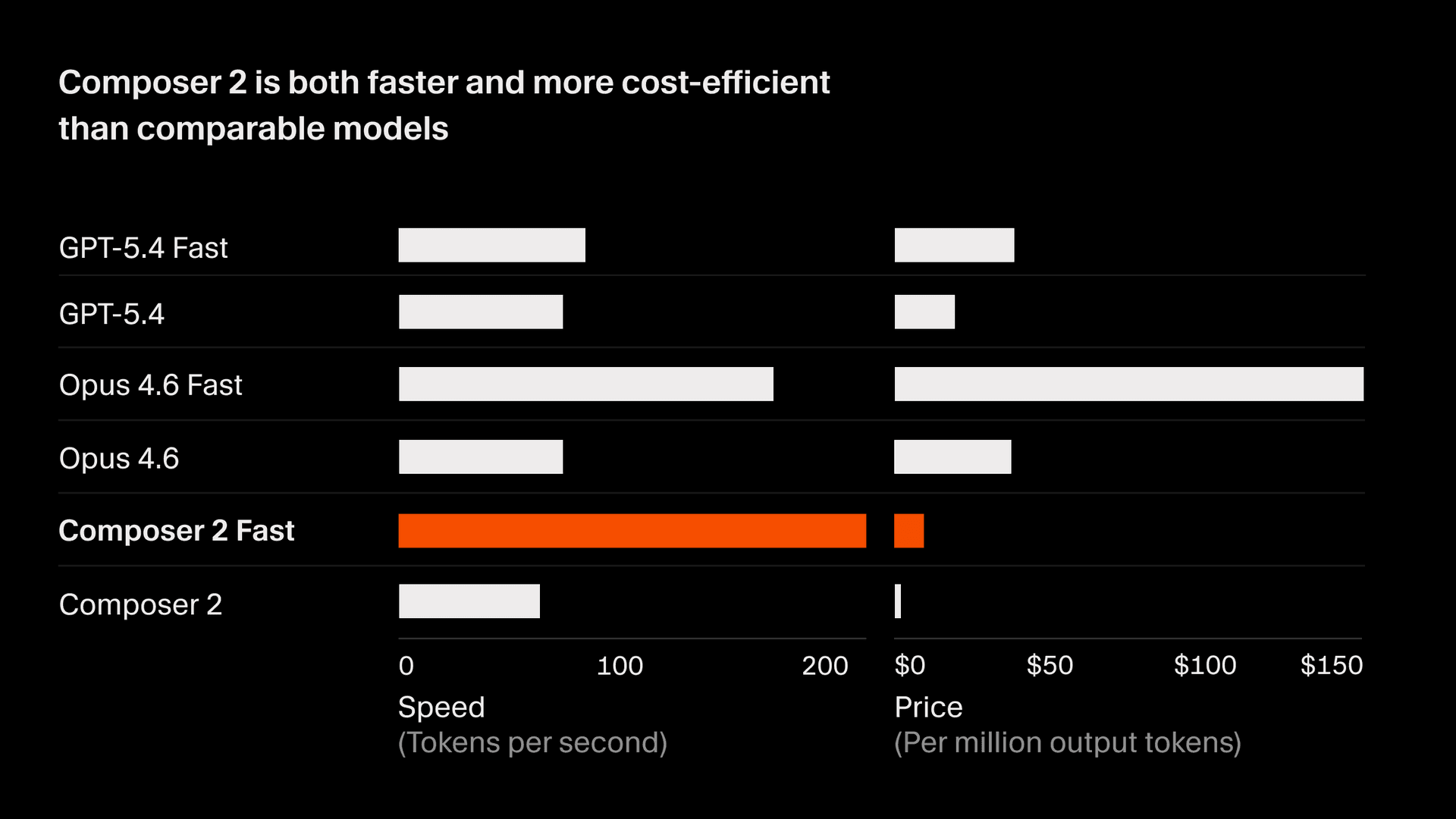
Composer 2 की कीमत 2.50/M आउटपुट टोकन है।
इसी इंटेलिजेंस वाला एक तेज़ रूपांतर भी 7.50/M आउटपुट टोकन पर उपलब्ध है, जिसकी लागत दूसरे तेज़ मॉडल्स से कम है2। हम तेज़ मोड को डिफ़ॉल्ट विकल्प बना रहे हैं। पूरी जानकारी के लिए वर्तमान Composer मॉडल दस्तावेज़ देखें।

व्यक्तिगत योजनाओं में, Composer का उपयोग First-party models pool का हिस्सा है, जिसमें उदार उपयोग शामिल है। आज ही Cursor में या हमारे नए इंटरफ़ेस के शुरुआती alpha में Composer 2 आज़माएँ।
- Terminal-Bench 2.0, Laude Institute द्वारा अनुरक्षित, टर्मिनल उपयोग के लिए एक एजेंट eval benchmark है। Anthropic मॉडल स्कोर Claude Code harness का उपयोग करते हैं और OpenAI मॉडल स्कोर Simple Codex harness का उपयोग करते हैं। हमारा Cursor स्कोर आधिकारिक Harbor evaluation framework (Terminal-Bench 2.0 के लिए निर्धारित harness) का उपयोग करके डिफ़ॉल्ट benchmark सेटिंग्स के साथ गणना किया गया था। हमने हर model-agent pair के लिए 5 iterations चलाए और औसत रिपोर्ट किया। benchmark के बारे में अधिक विवरण आधिकारिक Terminal Bench website पर मिल सकते हैं। Composer 2 के अलावा अन्य मॉडल्स के लिए, हमने official leaderboard स्कोर और हमारी अवसंरचना में चलाकर दर्ज किए गए स्कोर में से अधिकतम स्कोर लिया। ↩
- सभी मॉडल्स के लिए प्रति सेकंड टोकन (TPS), 18 मार्च 2026 को Cursor ट्रैफ़िक के एक स्नैपशॉट से लिए गए हैं। Composer और GPT मॉडल्स के लिए token sizing समान है। Anthropic टोकन लगभग 15% छोटे हैं और TPS संख्या को इसे दर्शाने के लिए normalized किया गया है। इसी तरह, non-Anthropic मॉडल्स के लिए आउटपुट token कीमत को उसी लगभग 15% परिवर्तन के अनुरूप scale किया गया था। प्रदाता क्षमता और समय के साथ होने वाले सुधारों के आधार पर गति बदल सकती है। ↩