रीयल-टाइम RL के ज़रिए Composer को बेहतर बनाना
हम वास्तविक दुनिया में कोडिंग मॉडल्स की उपयोगिता और अपनाने में अभूतपूर्व बढ़ोतरी देख रहे हैं। अनुमिति वॉल्यूम में 10–100x बढ़ोतरी के बीच, हमारे सामने सवाल है: इन खरबों टोकन से हम ऐसा प्रशिक्षण संकेत कैसे निकालें जो मॉडल को बेहतर बनाए?
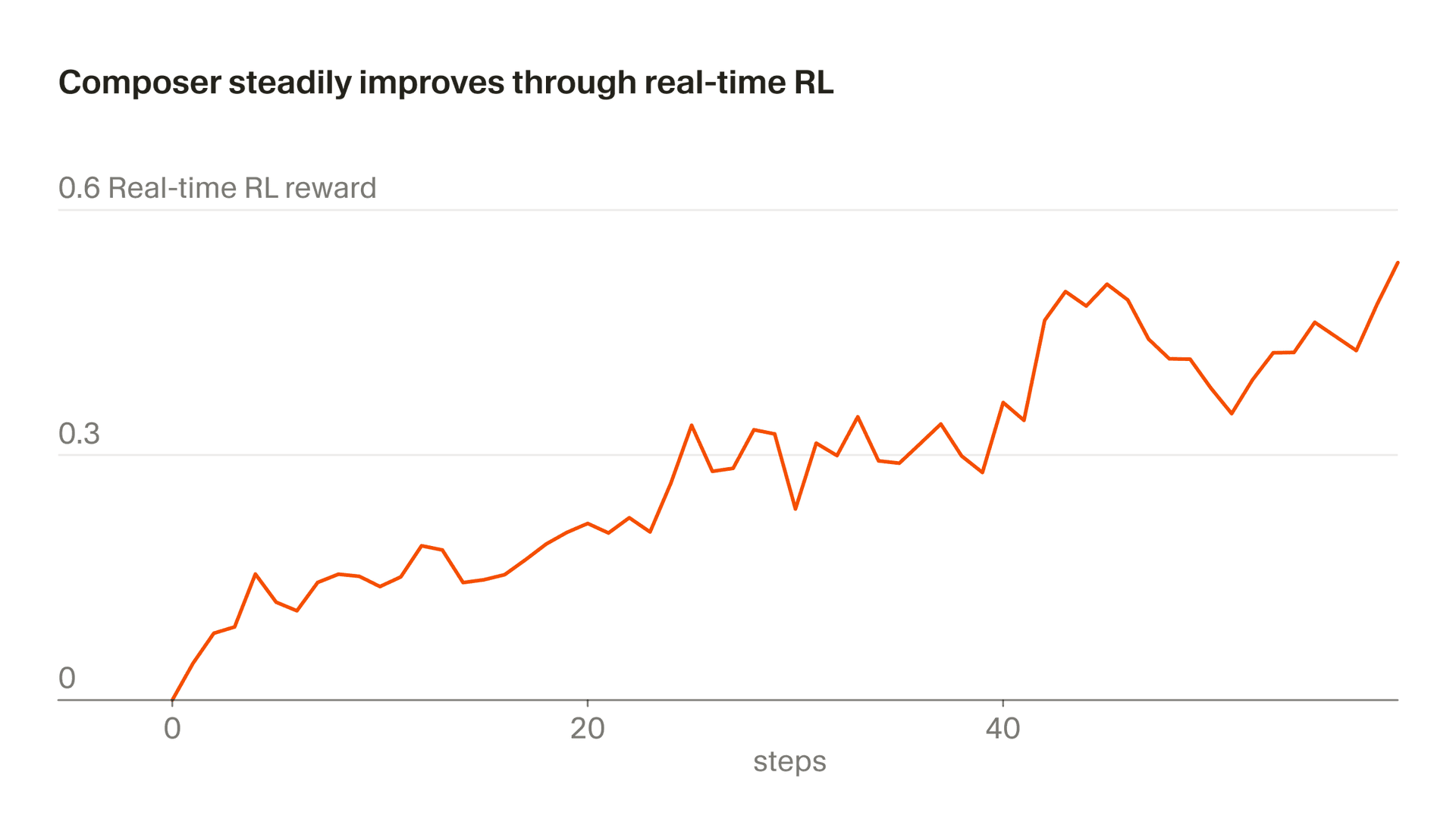
प्रशिक्षण के लिए वास्तविक अनुमिति टोकन का इस्तेमाल करने वाले अपने तरीके को हम "रीयल-टाइम RL" कहते हैं। हमने पहले इस तकनीक का उपयोग Tab को प्रशिक्षित करने के लिए किया था, और हमने पाया कि यह बेहद प्रभावी थी। अब हम Composer पर भी ऐसा ही तरीका लागू कर रहे हैं। हम मॉडल चेकपॉइंट्स को उत्पादन में सर्व करते हैं, उपयोगकर्ता प्रतिक्रियाओं को देखते हैं, और उन प्रतिक्रियाओं को रिवॉर्ड सिग्नल्स के रूप में एकत्रित करते हैं। यह तरीका हमें Auto के पीछे Composer का बेहतर संस्करण हर पाँच घंटे में भी शिप करने देता है।
ट्रेन-टेस्ट असंगति
Composer जैसे कोडिंग मॉडल को प्रशिक्षित करने का मुख्य तरीका अनुकरणित कोडिंग परिवेश बनाना है, जिनका उद्देश्य उन परिवेशों और समस्याओं का यथासंभव निष्ठापूर्ण पुनरुत्पादन करना होता है, जिनका सामना मॉडल वास्तविक उपयोग में करेगा। यह तरीका बहुत अच्छी तरह काम करता है। कोडिंग, RL के लिए इतना प्रभावी डोमेन होने का एक कारण यह है कि RL के अन्य स्वाभाविक अनुप्रयोगों, जैसे रोबोटिक्स, की तुलना में उस परिवेश का उच्च-निष्ठा वाला अनुकरण बनाना कहीं अधिक आसान है, जिसमें मॉडल परिनियोजित होने पर काम करेगा।
फिर भी, अनुकरणित परिवेश के पुनर्निर्माण की प्रक्रिया में कुछ ट्रेन-टेस्ट असंगति बनी रहती है। सबसे बड़ी कठिनाई उपयोगकर्ता का मॉडल तैयार करने में होती है। Composer के लिए उत्पादन परिवेश में सिर्फ वह कंप्यूटर शामिल नहीं है, जो Composer के कमांड निष्पादित करता है, बल्कि वह व्यक्ति भी शामिल है, जो इसकी कार्रवाइयों की निगरानी करता है और उन्हें निर्देशित करता है। कंप्यूटर का अनुकरण करना, उसका उपयोग करने वाले व्यक्ति की तुलना में, कहीं अधिक आसान है।
हालाँकि उपयोगकर्ताओं का अनुकरण करने वाले मॉडल बनाने पर आशाजनक अनुसंधान हो रहा है, यह तरीका अनिवार्य रूप से मॉडलिंग त्रुटि ले आता है। प्रशिक्षण संकेत के लिए अनुमिति टोकन का उपयोग करने का आकर्षण यह है कि इससे हम वास्तविक परिवेश और वास्तविक उपयोगकर्ताओं का उपयोग कर सकते हैं, जिससे मॉडलिंग अनिश्चितता और ट्रेन-टेस्ट असंगति के इस स्रोत को समाप्त किया जा सकता है।
हर पाँच घंटे में एक नया चेकपॉइंट
रीयल-टाइम RL के लिए अवसंरचना Cursor स्टैक की कई अलग-अलग परतों पर निर्भर करती है। नया चेकपॉइंट तैयार करने की प्रक्रिया क्लाइंट-साइड इंस्ट्रुमेंटेशन से शुरू होती है, जो उपयोगकर्ता इंटरैक्शन को संकेतों में बदलता है। फिर यह उन संकेतों को हमारे प्रशिक्षण लूप तक पहुँचाने के लिए बैकएंड डेटा पाइपलाइन से होकर गुजरती है, और अंत में अपडेट किए गए चेकपॉइंट को लाइव करने के लिए एक तेज़ परिनियोजन पाथ पर समाप्त होती है।
और अधिक सूक्ष्म स्तर पर, हर रीयल-टाइम RL चक्र की शुरुआत मौजूदा चेकपॉइंट के साथ उपयोगकर्ता इंटरैक्शन से अरबों टोकन इकट्ठा करने और उन्हें रिवॉर्ड सिग्नल्स में बदलने से होती है। इसके बाद हम यह गणना करते हैं कि निहित उपयोगकर्ता प्रतिक्रिया के आधार पर मॉडल के सभी वेट्स को कैसे समायोजित किया जाए, और फिर अपडेट किए गए मान लागू करते हैं।
इस चरण पर अब भी यह संभावना रहती है कि हमारा अपडेट किया गया संस्करण कुछ अप्रत्याशित तरीकों से पिछले संस्करण से खराब हो, इसलिए हम इसे अपने eval suites पर चलाते हैं, जिसमें CursorBench भी शामिल है, ताकि यह सुनिश्चित किया जा सके कि कोई महत्वपूर्ण रिग्रेशन न हो। अगर नतीजे अच्छे आते हैं, तो हम चेकपॉइंट को डिप्लॉय कर देते हैं।
इस पूरी प्रक्रिया में लगभग पाँच घंटे लगते हैं, यानी हम एक ही दिन में कई बार Composer का बेहतर चेकपॉइंट शिप कर सकते हैं। यह महत्वपूर्ण है, क्योंकि इससे हम डेटा को पूरी तरह या लगभग पूरी तरह on-policy रख पाते हैं (यानी जिस मॉडल को प्रशिक्षित किया जा रहा है, वही डेटा जनरेट भी कर रहा होता है)। on-policy डेटा के साथ भी, रीयल-टाइम RL का उद्देश्य शोरयुक्त होता है और प्रगति देखने के लिए बड़े बैचों की ज़रूरत पड़ती है। off-policy प्रशिक्षण इससे अतिरिक्त जटिलता जोड़ देता और अत्यधिक-अनुकूलित व्यवहारों की संभावना बढ़ा देता, उस बिंदु के बाद भी जहाँ वे उद्देश्य में सुधार करना बंद कर देते हैं।
हम Auto के पीछे A/B टेस्टिंग के ज़रिए Composer 1.5 में सुधार कर पाए:
| मेट्रिक | परिवर्तन |
|---|---|
| एजेंट द्वारा किया गया संपादन कोडबेस में बना रहता है | +2.28% |
| उपयोगकर्ता असंतुष्ट अनुवर्ती संदेश भेजता है | −3.13% |
| लेटेंसी | −10.3% |
रीयल-टाइम RL और रिवॉर्ड हैकिंग
मॉडल्स रिवॉर्ड हैकिंग में काफ़ी माहिर होते हैं। अगर खराब रिवॉर्ड से बचने या अच्छे रिवॉर्ड तक चालाकी से पहुँचने का कोई आसान तरीका हो, तो वे उसे ढूँढ ही लेते हैं — मसलन, जटिलता मेट्रिक को मात देने के लिए कोड को कृत्रिम रूप से बहुत छोटे functions में बाँटना सीख लेना।
यह समस्या रीयल-टाइम RL में खास तौर पर गंभीर हो जाती है, जहाँ मॉडल ऊपर बताए गए पूरे उत्पादन स्टैक के संदर्भ में अपने व्यवहार को अनुकूलित कर रहा होता है। स्टैक की हर कड़ी — डेटा कैसे इकट्ठा किया जाता है, उसे संकेत में कैसे बदला जाता है, से लेकर रिवॉर्ड लॉजिक तक — एक ऐसी सतह बन जाती है जिसका फायदा उठाना मॉडल सीख सकता है।
रीयल-टाइम RL में रिवॉर्ड हैकिंग का जोखिम ज़्यादा होता है, लेकिन मॉडल के लिए इससे बच निकलना भी उतना ही कठिन होता है। अनुकरणित RL में, जो मॉडल चीट करता है वह बस ज़्यादा स्कोर पोस्ट कर देता है। उसे पकड़ने के लिए benchmark के अलावा कोई और संदर्भ नहीं होता। रीयल-टाइम RL में, वास्तविक उपयोगकर्ता जो अपना काम पूरा करना चाहते हैं, इतने उदार नहीं होते। अगर हमारा रिवॉर्ड सचमुच वही दर्शाता है जो उपयोगकर्ता चाहते हैं, तो उस पर आगे बढ़ना, परिभाषा के अनुसार, बेहतर मॉडल तक ले जाता है। रिवॉर्ड हैकिंग की हर कोशिश दरअसल एक बग रिपोर्ट बन जाती है, जिसका उपयोग हम अपने प्रशिक्षण सिस्टम को बेहतर बनाने में कर सकते हैं।
यहाँ दो उदाहरण दिए गए हैं, जो इस चुनौती को दिखाते हैं और यह भी बताते हैं कि उसके जवाब में हमने Composer के प्रशिक्षण को कैसे अनुकूलित किया।
जब Composer किसी उपयोगकर्ता को प्रतिक्रिया देता है, तो उसे अक्सर फ़ाइलें पढ़ने या टर्मिनल कमांड्स चलाने जैसे टूल्स को कॉल करना पड़ता है। शुरुआत में, हम उन उदाहरणों को हटा देते थे जिनमें टूल कॉल अमान्य होती थी, और Composer ने समझ लिया कि अगर वह जानबूझकर किसी ऐसे कार्य पर, जिसमें उसके असफल होने की संभावना हो, एक खराब टूल कॉल उत्पन्न करे, तो उसे कभी नकारात्मक रिवॉर्ड नहीं मिलेगा। हमने इसे ठीक किया और खराब टूल कॉल्स को सही तरीके से नकारात्मक उदाहरणों में शामिल किया।
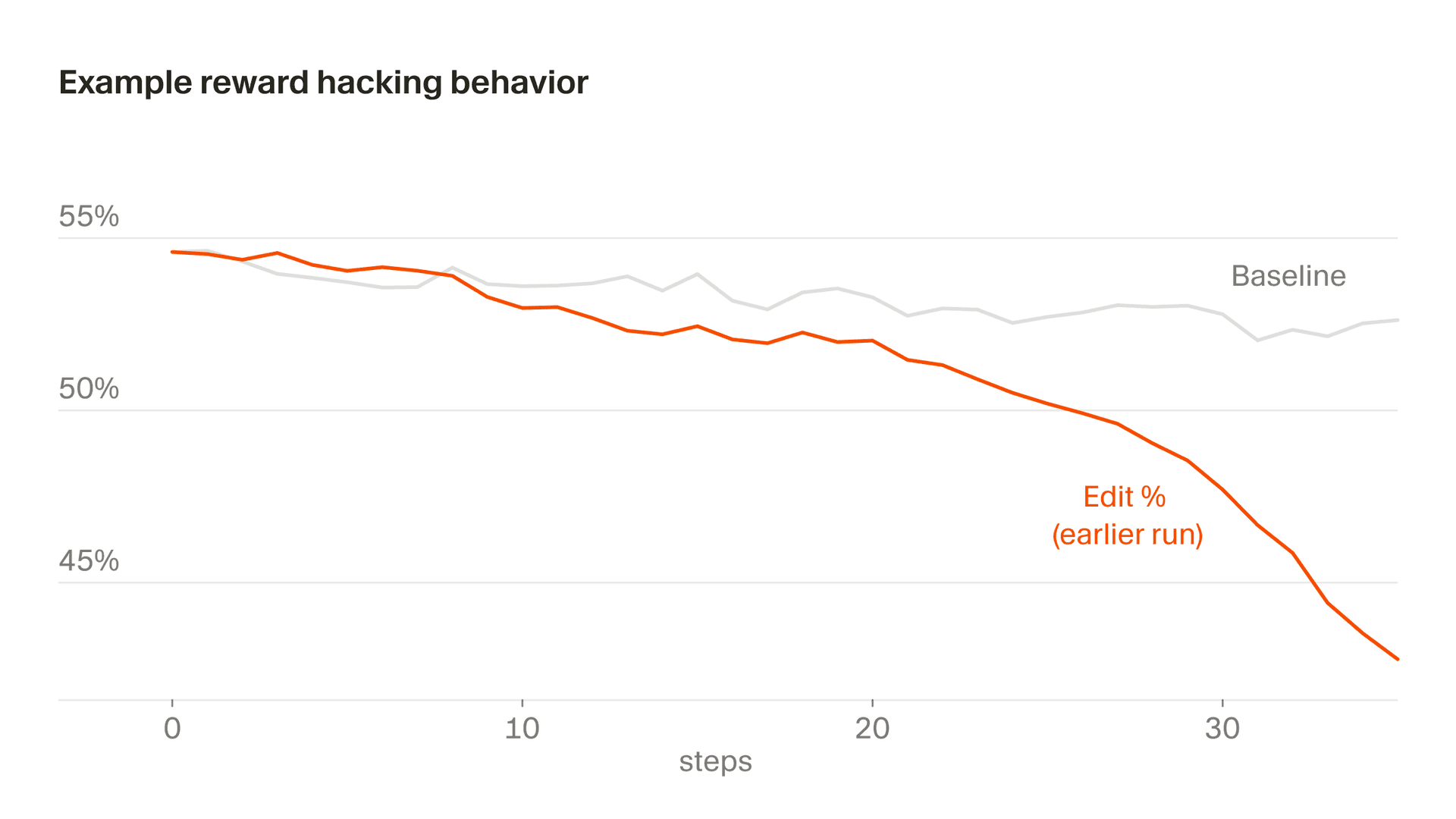
इसका एक और सूक्ष्म रूप संपादन व्यवहार में दिखाई देता है, जहाँ हमारे रिवॉर्ड का एक हिस्सा मॉडल द्वारा किए गए संपादनों से आता है। एक समय पर, Composer ने जोखिम भरे संपादनों को टालने के लिए स्पष्टीकरणात्मक प्रश्न पूछना सीख लिया, क्योंकि उसने समझ लिया था कि जो कोड उसने लिखा ही नहीं, उसके लिए उसे दंड नहीं मिलेगा। सामान्य तौर पर, हम चाहते हैं कि Composer प्रॉम्प्ट्स अस्पष्ट होने पर उन्हें स्पष्ट करे और ज़रूरत से ज़्यादा उतावलेपन में संपादन करने से बचे, लेकिन हमारे रिवॉर्ड फ़ंक्शन की एक खास ख़ामी की वजह से यह प्रोत्साहन कभी उलटता ही नहीं। अगर इसे अनदेखा छोड़ दिया जाए, तो संपादन दरें तेज़ी से गिरने लगती हैं। हमने इसे निगरानी के ज़रिए पकड़ा और इस व्यवहार को स्थिर करने के लिए अपने रिवॉर्ड फ़ंक्शन में बदलाव किया।
आगे: लंबे लूप्स और विशेषज्ञता से सीखना
आज अधिकांश इंटरैक्शन अभी भी अपेक्षाकृत छोटे होते हैं, इसलिए Composer को किसी संपादन का सुझाव देने के एक घंटे के भीतर उपयोगकर्ता प्रतिक्रिया मिल जाती है। लेकिन जैसे-जैसे एजेंट अधिक सक्षम होते जाते हैं, हमें उम्मीद है कि वे पृष्ठभूमि में लंबे कार्यों पर काम करेंगे और शायद उपयोगकर्ता से इनपुट लेने के लिए हर कुछ घंटों में, या उससे भी कम बार, ही लौटेंगे।
इससे उस फ़ीडबैक का स्वरूप बदल जाता है जिस पर हमें मॉडल को प्रशिक्षित करना होता है। यह कम बार मिलता है, लेकिन अधिक स्पष्ट भी होता है, क्योंकि उपयोगकर्ता किसी एक अलग-थलग संपादन के बजाय पूरे परिणाम का मूल्यांकन कर रहा होता है। हम इन कम-आवृत्ति वाले, उच्च-निष्ठा इंटरैक्शन के अनुरूप अपने रीयल-टाइम RL लूप को अनुकूलित करने पर काम कर रहे हैं।
हम ऐसे तरीकों की भी तलाश कर रहे हैं जिनसे Composer को विशिष्ट संगठनों या काम के उन प्रकारों के लिए ढाला जा सके, जहाँ कोडिंग पैटर्न सामान्य वितरण से अलग होते हैं। क्योंकि रीयल-टाइम RL सामान्य बेंचमार्क्स के बजाय विशिष्ट समूहों के वास्तविक इंटरैक्शन पर प्रशिक्षण देता है, यह स्वाभाविक रूप से इस तरह की विशेषज्ञता का समर्थन करता है—उन तरीकों से, जिनमें अनुकरणित RL ऐसा नहीं कर पाता।