Training Composer for longer horizons
We train Composer for long-horizon tasks through a reinforcement learning process called self-summarization. By making self-summarization part of Composer's training, we can get training signal from trajectories much longer than the model's max context window. This translates into Composer being able to learn to work on challenging coding tasks requiring hundreds of actions.
The limits of compaction techniques
In CursorBench, our internal benchmark suite, we observe that better performance on challenging real-world coding tasks is directly correlated with more thinking and codebase exploration. As users work with agents to take on harder and more ambitious tasks, we expect the returns on thinking and exploration to increase further.
A primary challenge, though, is that agent trajectories are expanding faster than the context length of models. Many agent harnesses attempt to get around this by using compaction as an intermediate step in the agent's workflow. When an agent hits its context limit, the harness transforms the context to a shorter length and continues the agent's generation where it left off.
In practice, compaction is typically handled by the harness in one of two ways: either in text space through a prompted summarization model, or through a sliding context window where the model drops older context. Researchers have also begun to explore compaction methods in latent space, where the model remembers context as vectors rather than text, although currently these approaches are much slower than text-based methods.
These approaches to compaction share the downside that they can cause the model to forget critical information from the context, reducing its efficacy as it advances through long-running tasks.
Self-summarization as a trained behavior
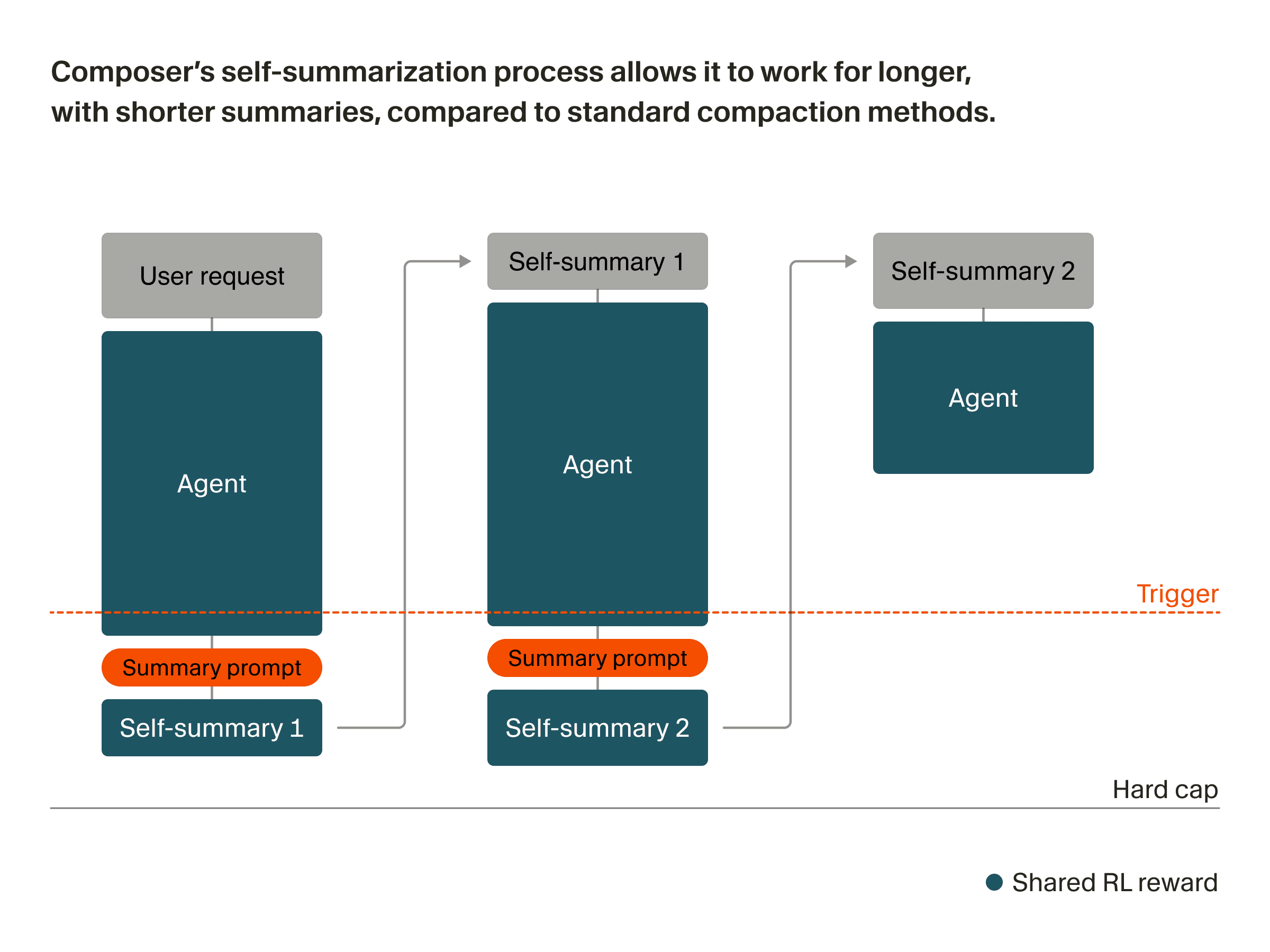
Composer is a specialized model designed for agentic coding and trained through reinforcement learning in the Cursor agent harness. This enables it to be trained with compaction-in-the-loop, improving its ability to determine the most critical information to summarize and preserve.
As Composer works through a task, it approaches a fixed context-length trigger, where it pauses to summarize its own context before continuing. More precisely, the self-summarization process works like this:
-
Composer generates from a prompt until a fixed token-length trigger is reached.
-
We insert a synthetic query asking the model to summarize the current context.
-
The model is given scratch space to think about the best summary and then generates a condensed context.
-
Composer loops back to step 1 with the condensed context, which includes the summary plus conversation state (plan state, remaining tasks, number of prior summarizations, etc).
To enable Composer to do this well at inference time, we incorporate the same summarization procedure into training. Each training rollout can involve multiple generations chained together by summaries, rather than a single prompt–response pair. This means the self-summaries themselves are part of what gets rewarded.
From a technical perspective, this does not require significant changes to training. We use the final reward for all tokens produced by the model in the chain. This upweights both the agent responses in good trajectories, and also the self-summarizations that made them work. At the same time, poor summaries that lost critical information are downweighted. As Composer trains, it learns to use this self-summary process to build longer context. For hard examples, it often self-summarizes multiple times.
Token-efficient compaction
To test self-summarization, we compare it with a highly tuned prompt-based compaction baseline. We study the problem on a set of hard software engineering tasks while varying the compaction trigger.
In the baseline compaction approach, the summarization prompt is thousands of tokens and includes nearly a dozen carefully worded sections describing the content that should be preserved in summary. The output compacted context is also on average more than 5,000 tokens and contains many structured sections describing critical information from the context.
In contrast, since Composer is trained to self-summarize, it requires a very short prompt which contains not much more content than, "Please summarize the conversation". The summaries it outputs are on average only around 1,000 tokens since it learns contextually to decide on the high-value information to retain.
We test Composer in two context-constrained test environments to measure the impact of self-summary, one with an 80k token trigger and another with a 40k trigger (meaning more frequent summaries). In both scenarios, self-summary produces significantly better results on CursorBench with much more token-efficient compactions. Self-summary consistently reduces the error from compaction by 50%, even compared to the targeted baseline approach, while using one-fifth of the tokens and reusing the KV cache (the stored intermediate computations from prior tokens).


Solving hard problems
The larger promise of compaction is to allow models to one-shot hard problems that require long reasoning chains. In our current training of Composer 2, we often see this happen. As a case study, we consider a problem from Terminal-Bench 2.0 known as make-doom-for-mips. The problem is as concise as it is challenging:
I have provided /app/doomgeneric/, the source code to doom. I've also wrote a special doomgeneric_img.c that I want you to use which will write each drawn frame to /tmp/frame.bmp. I've finally provided vm.js that will expect a file called doomgeneric_mips and will run it. Please figure out the rest…
While easy enough to describe, this problem is challenging enough that several powerful models are unable to get it correct in the official reported numbers.
When testing an early research checkpoint of Composer, we found that it was able to solve this problem correctly. The solution required engineering and testing a significant amount of code, as well as exploring some alternative implementations. Here's an image rendered in the course of solving the problem:

All in all, Composer worked for 170 turns to find an exact solution, along the way creating self-summaries in a compact, human-readable and structured form. It self-summarized more than 100,000 tokens down to the 1,000 it believed would most help it solve the problem:
## Conversation summary
### User goal
Build a MIPS little-endian ELF named doomgeneric_mips so `node vm.js` can run it: stdout should work, and frames should be written to `/tmp/frame.bmp` using the provided doomgeneric_img.c (and doomgeneric sources under `/app/doomgeneric/`).
### What was implemented
1. Freestanding libc for the JS VM (`/app/mips_freestanding/`)
- The VM implements Linux-style open flags but syscall numbers are not real MIPS Linux (0=read, 1=write, 2=open, 3=close, 8=lseek, 201=time, 38=rename, 39=mkdir). Normal mipsel-linux-gnu-gcc + glibc would use 4003+ style numbers and would not work.
- `my_libc.c` + `vm_syscall.h`: those syscalls, plus minimal `malloc`/`free`/`realloc`, `stdio` (`fopen`/`fread`/`fwrite`/…), strings, `printf` subset, `qsort`, `sin`/`atan`/`fabs`, `strdup`, `abs`, `system` stub, etc.
2. `doomgeneric_img.c` (under `/app/doomgeneric/doomgeneric/`)
- Uses `my_stdlib.h`.
- `DG_DrawFrame`: writes every frame to `/tmp/frame.bmp` (32-bit BMP).
- `main`: safe `argc`/`argv` (fallback argv if null), then `doomgeneric_Create` → infinite `doomgeneric_Tick()` loop (same pattern as other doomgeneric front ends).
3. Build — `/app/doomgeneric/doomgeneric/Makefile.mips`
- `mipsel-linux-gnu-gcc`, `-fno-pic -mno-abicalls`, `-static -nostdlib`, `-Wl,-e,main`, link `libgcc`.
- PIC was required to avoid: entry at `main` with `$t9` unset broke GP-relative GOT; non-PIC fixed that.
- Objects: full doom list with `doomgeneric_img.o` instead of xlib; no `deh_str.o` (header-only).
- `i_system.c`: `DEFAULT_RAM` / `MIN_RAM` overridable via `-D`; build used `-DDEFAULT_RAM=4 -DMIN_RAM=4` to shrink zone for the VM.
- Output: `/app/doomgeneric_mips`. Do not strip — VM resolves `main` from `.symtab`.
4. `vm.js` changes (important for the other assistant)
- OOM: plain `{}` memory exploded V8 when doom touched many words.
- `runElf`: now allocates `Uint32Array` low RAM (96MB from `0x400000`) + stack (~8MB from `0x7f800000`), loads `.text`/`.data`/`.rodata` into low buffer, returns `{ lowMem, stkMem, memLowBase, …, entry_point }` instead of a giant `memory` object.
- `MIPSVM`: `memGetWord` / `memSetWord` route through those buffers; sparse `this.memory` effectively dropped for stores (OOM fix); `memGetWord` OOB → 0 (can hide bugs).
- All `lw`/`sw`/byte helpers and `runProgram` instruction fetch use `memGetWord`/`memSetWord`. End of script wires `vm._lowMem` etc. from `runElf`.
### Errors / fixes (short)
- Wrong syscalls → custom libc + VM syscall numbers.
- Link errors → added `strdup`, `strstr`, `abs`, `putchar`, `puts`, `atof`, `system`, `remove`/`rename`; removed nonexistent `deh_str.o`.
- Immediate crash at entry → `-fno-pic -mno-abicalls`.
- Node OOM → ArrayBuffer-backed VM memory; removed unbounded `this.memory` writes.
- `r_segs.c`: `SHRT_MAX` → added to `limits.h`.
### What’s still broken / to do for the next assistant
- `/tmp/frame.bmp` never appeared in tests: run ends with `Program terminated at PC=0x400151`, `Executed 626581578` instructions. `0x400150` is the `abort` symbol (tight branch-to-self). So something eventually jumps into `abort`, not a clean game loop drawing frames.
- 4MB zone (`DEFAULT_RAM=4`) may be too small for real IWAD play → `Z_Malloc` / OOM-style failures or other undefined behavior; worth trying `DEFAULT_RAM=6`, larger `HEAP_SIZE` in `my_libc.c` (was reduced to 14MB), and ensuring `memGetWord` OOB doesn’t mask real faults.
- Concrete next steps: find who calls `abort` (e.g. trap, libgcc path, failed alloc); fix I_Error path on non-Win (currently may call `ZenityErrorBox` / odd paths); confirm `doomgeneric_Create` → `D_DoomMain` → … → `doomgeneric_Tick`/`D_Display` → `DG_DrawFrame`; verify `fopen("/tmp/frame.bmp","wb")` + `SYS_close` flush in VM; rerun until `/tmp/frame.bmp` exists and stdout looks sane.
### Paths
- ELF: `/app/doomgeneric_mips`
- Build: `/app/doomgeneric/doomgeneric/Makefile.mips`
- Front end: `/app/doomgeneric/doomgeneric/doomgeneric_img.c`
- Libc: `/app/mips_freestanding/my_libc.c`, `/app/mips_freestanding/include/*`
- VM: `/app/vm.js` (patched memory model)
- IWAD used locally: `/app/doom1.wad` (for testing)Toward a long-horizon future
By folding compaction into the training loop, Composer learns an explicit mechanism for efficiently carrying critical information forward, and becomes more capable at challenging tasks. Our work on self-summarization is a step toward our broader goal of training Composer over even longer, more complex processes such as multi-agent coordination. We continue to see better model training as improving the scope and intelligence of these agentic systems.
We'll also be sharing more about the next version of Composer shortly.