A technical report on Composer 2

We posted to the arXiv a technical report on the training of Composer 2, our coding model for agentic software engineering. The report covers the full training process, from continued pretraining on an open base model, Kimi K2.5, through large-scale reinforcement learning, with a focus on closely emulating the real Cursor environment.
Continued pretraining and RL
Composer 2 is trained in two phases: continued pretraining on a data mix that emphasizes code to deepen the base model's coding knowledge, followed by large-scale reinforcement learning to improve end-to-end agent performance. We find that reducing pretraining loss improves downstream RL performance, with better base knowledge reliably translating into a better agent.
Composer 2 RL training occurs in realistic Cursor sessions with the same tools and harness the deployed model uses, applied to a problem distribution that reflects the full range of what developers ask Composer to do. We find that RL training improves both average and best-of-K performance, suggesting the model is learning new solution paths rather than just concentrating on known ones.
Real-world evaluation with CursorBench
A core challenge in building coding models is that public benchmarks often don't reflect the work developers actually do. Tasks are over-specified, solutions are narrow, and the codebases are small.
We built CursorBench from real coding sessions by our engineering team. It includes tasks where the prompt is terse and ambiguous, and solutions require hundreds of lines of changes across many files. We use CursorBench throughout training and evaluation to keep the model aligned with real problems.
Performance
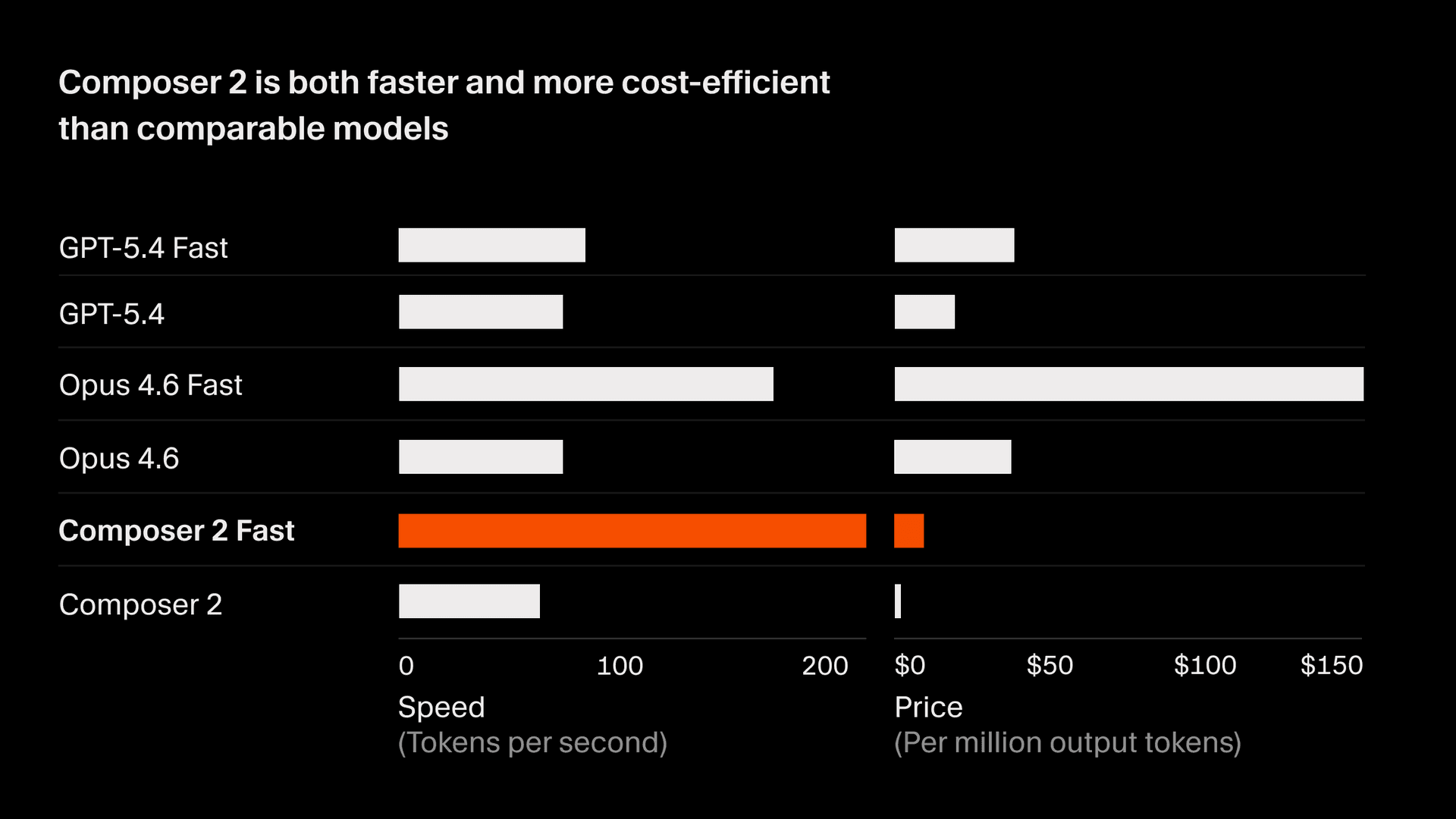
On CursorBench, Composer 2 scores 61.3, a 37% improvement over Composer 1.5 and competitive with the strongest frontier models. On public benchmarks, Composer 2 scores 73.7 on SWE-bench Multilingual and 61.7 on Terminal-Bench. It achieves this at significantly lower inference cost than comparable models, giving it a Pareto-optimal tradeoff between accuracy and cost for interactive developer workflows.



Infrastructure
Training Composer 2 required substantial infrastructure development with custom low-precision kernels for efficient MoE training on Blackwell GPUs, a fully asynchronous RL pipeline spanning multiple regions, and Anyrun, our internal compute platform for running hundreds of thousands of sandboxed coding environments. The report covers the full stack, including our approach to weight synchronization, fault tolerance, and environment fidelity.
The report has much more detail on all of this, including ablations on the training recipe, our approach to agent behavior shaping, and the design of our evaluation suite.
Thank you to the teams behind Kimi K2.5, Ray, ThunderKittens, PyTorch, and the broader open-source community. We'd also like to thank Fireworks and Colfax for their collaboration and partnership.
Read the full technical report here.