Présentation de Composer 2
Composer 2 est désormais disponible sur Cursor.
Il offre des performances à l’état de l’art en codage et est facturé à 2.50/M en token de sortie, ce qui en fait une nouvelle combinaison optimale d’intelligence et de coût. Nous avons également publié un rapport technique sur la manière dont nous l’avons entraîné.


Une intelligence de codage à l’état de l’art
Nous améliorons rapidement la qualité de notre modèle. Composer 2 apporte d’importantes améliorations sur tous les benchmarks que nous suivons, y compris Terminal-Bench 2.01 et SWE-bench multilingue :
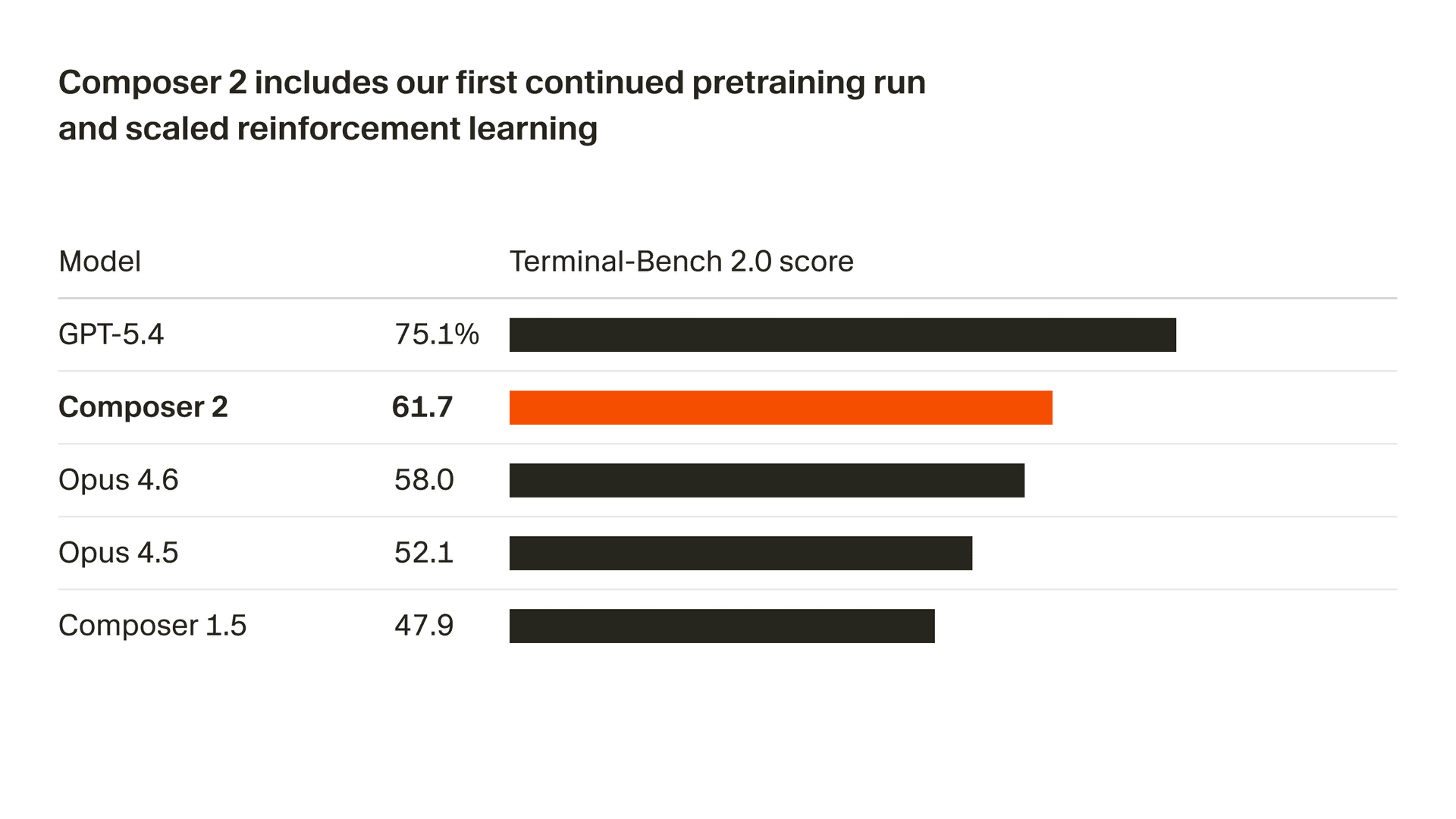
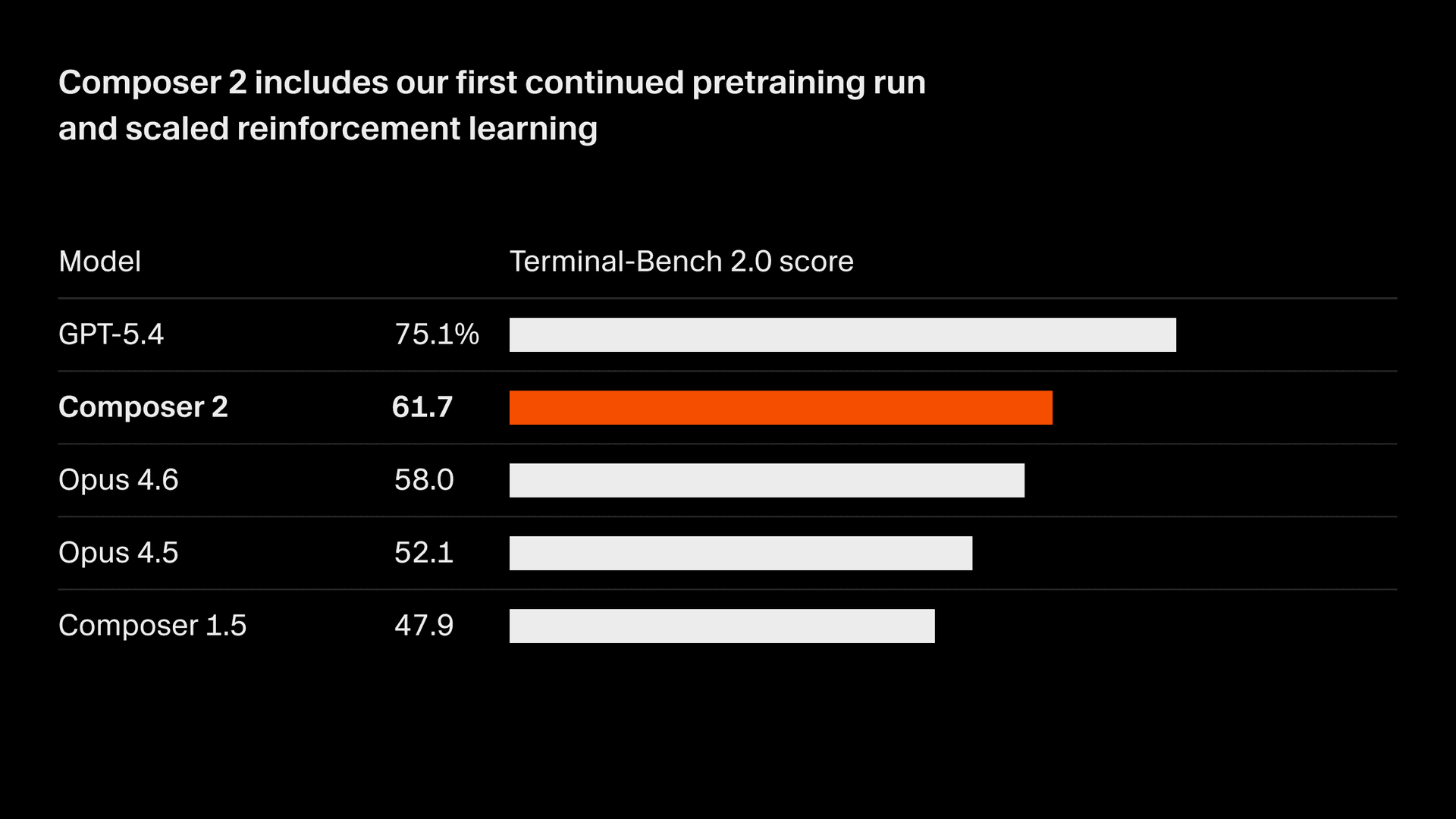
| Modèle | CursorBench | Terminal-Bench 2.0 | SWE-bench multilingue |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Ces gains de qualité proviennent de notre premier run de préentraînement continu, qui fournit une base bien plus solide pour faire évoluer notre apprentissage par renforcement.
À partir de cette base, nous entraînons le modèle sur des tâches de codage à long horizon grâce à l’apprentissage par renforcement. Composer 2 est capable de résoudre des tâches difficiles nécessitant des centaines d’actions.
Découvrez Composer 2
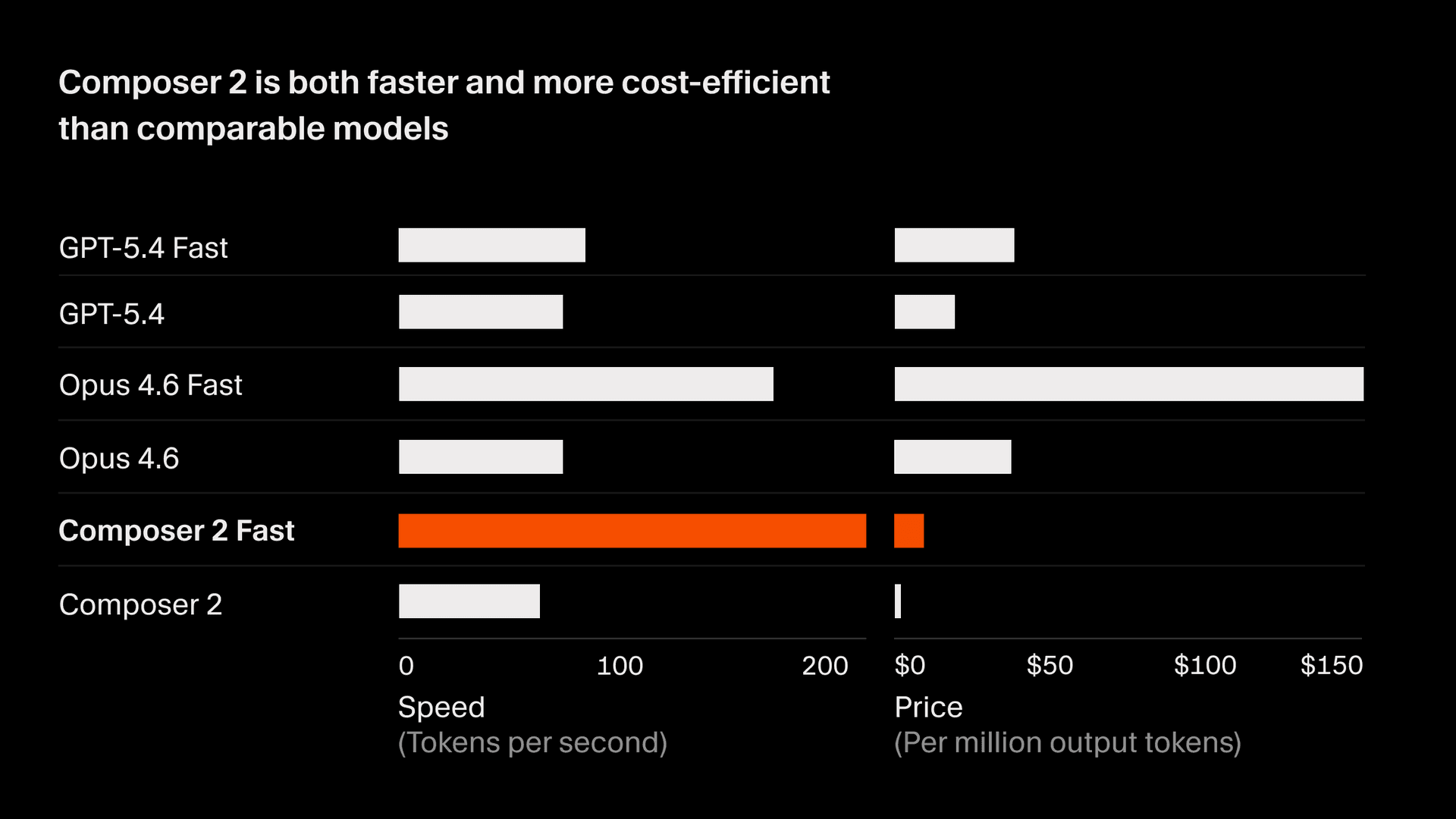
Composer 2 est facturé 2.50/M en tokens de sortie.
Il existe aussi une variante plus rapide avec la même intelligence à 7.50/M en tokens de sortie, dont le prix est inférieur à celui des autres modèles rapides2. Nous faisons de cette variante rapide l’option par défaut. Voir la documentation actuelle du modèle Composer pour tous les détails.

Avec les forfaits individuels, l’utilisation de Composer fait partie du pool des modèles first-party, avec une utilisation généreuse incluse. Découvrez Composer 2 dès aujourd’hui dans Cursor ou dans la version alpha précoce de notre nouvelle interface.
- Terminal-Bench 2.0 est un benchmark d’évaluation d’agents pour l’utilisation du terminal, maintenu par le Laude Institute. Les scores des modèles Anthropic utilisent le harness Claude Code et les scores des modèles OpenAI utilisent le harness Simple Codex. Notre score Cursor a été calculé à l’aide du framework d’évaluation Harbor officiel (le harness désigné pour Terminal-Bench 2.0) avec les paramètres par défaut du benchmark. Nous avons exécuté 5 itérations par paire modèle-agent et reportons la moyenne. Vous trouverez plus de détails sur le benchmark sur le site officiel de Terminal Bench. Pour les modèles autres que Composer 2, nous avons retenu le score le plus élevé entre le score du classement officiel et le score enregistré lors de l’exécution dans notre infrastructure. ↩
- Les tokens par seconde (TPS) de tous les modèles proviennent d’un instantané du trafic de Cursor du 18 mars 2026. Le dimensionnement des tokens pour Composer et les modèles GPT est similaire. Les tokens Anthropic sont ~15 % plus petits et le nombre de TPS est normalisé pour en tenir compte. De même, le prix des tokens de sortie pour les modèles non-Anthropic a été ajusté pour correspondre à cette même variation d’environ 15 %. La vitesse peut varier en fonction de la capacité du fournisseur et des améliorations au fil du temps. ↩