Améliorer Composer grâce au RL en temps réel
Nous observons une croissance sans précédent de l’utilité et de l’adoption des modèles de codage dans le monde réel. Face à une hausse de 10 à 100x du volume d’inférence, nous nous posons la question suivante : comment tirer de ces milliers de milliards de tokens un signal d’entraînement pour améliorer le modèle ?
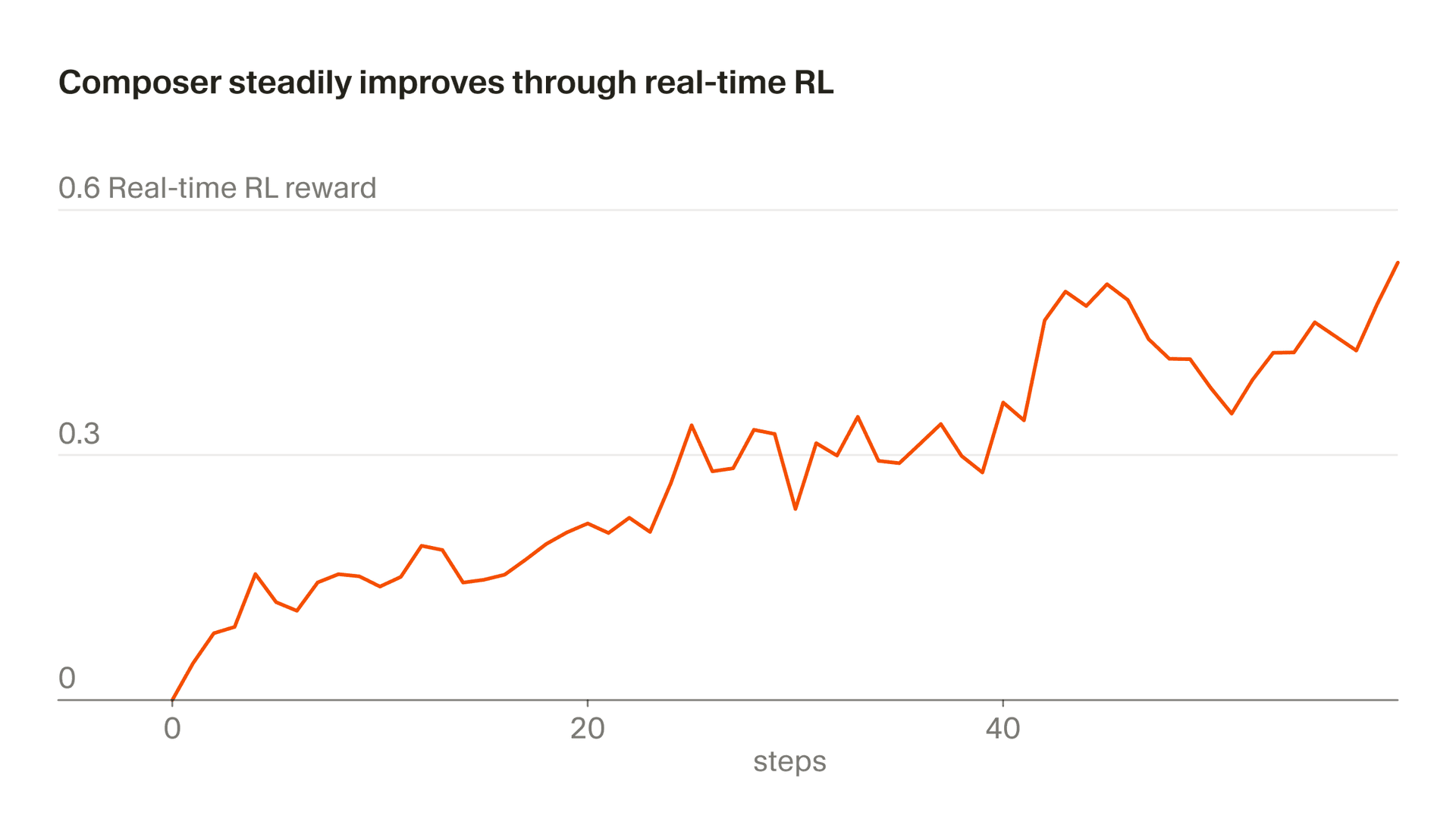
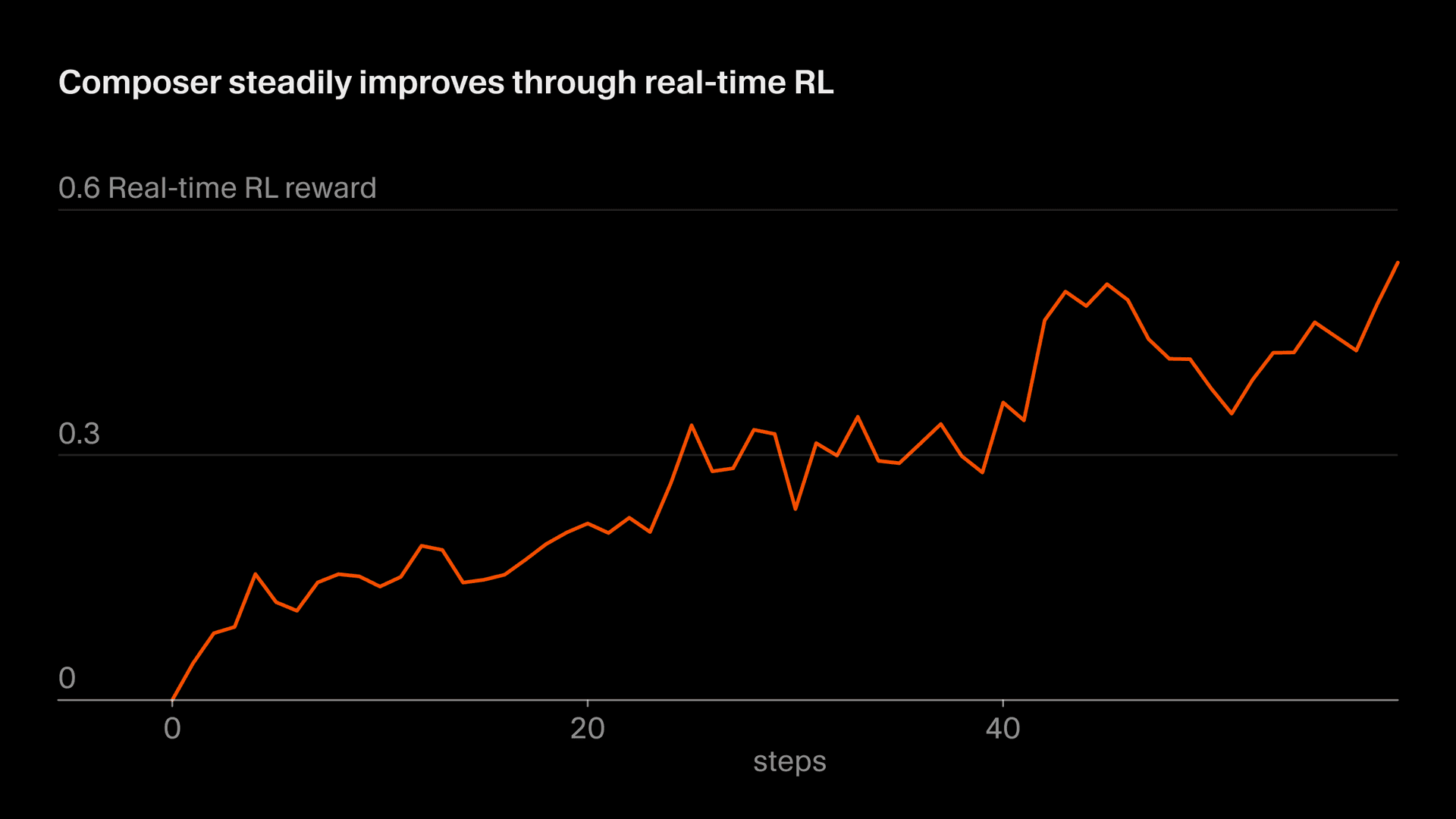
Nous appelons notre approche, qui consiste à utiliser de vrais tokens d’inférence comme signal d’entraînement, « RL en temps réel ». Nous avons d’abord utilisé cette technique pour entraîner Tab, et nous avons constaté qu’elle était très efficace. Nous appliquons maintenant une approche similaire à Composer. Nous mettons des checkpoints de modèle en production, observons les réponses des utilisateurs et agrégeons ces réponses comme signaux de récompense. Cette approche nous permet de livrer une version améliorée de Composer via Auto jusqu’à une fois toutes les cinq heures.
Le décalage entre l’entraînement et le test
Le principal moyen d’entraîner des modèles de codage comme Composer consiste à créer des environnements de codage simulés, conçus pour reproduire aussi fidèlement que possible les environnements et les problèmes que le modèle rencontrera en usage réel. Cela a très bien fonctionné. L’une des raisons pour lesquelles le codage est un domaine si efficace pour le RL est que, par rapport à d’autres applications naturelles du RL comme la robotique, il est bien plus facile de créer une simulation très fidèle de l’environnement dans lequel le modèle opérera une fois déployé.
Néanmoins, le processus de recréation d’un environnement simulé introduit encore un certain décalage entre l’entraînement et le test. La plus grande difficulté réside dans la modélisation de l’utilisateur. L’environnement de production de Composer ne se compose pas seulement de l’ordinateur qui exécute les commandes de Composer, mais aussi de la personne qui supervise et dirige ses actions. Il est bien plus facile de simuler l’ordinateur que la personne qui l’utilise.
Bien qu’il existe des recherches prometteuses sur la création de modèles qui simulent les utilisateurs, cette approche introduit inévitablement une erreur de modélisation. L’intérêt d’utiliser les tokens d’inférence comme signal d’entraînement est que cela nous permet d’utiliser des environnements réels et de vrais utilisateurs, éliminant ainsi cette source d’incertitude liée à la modélisation et ce décalage entre entraînement et test.
Un nouveau checkpoint toutes les cinq heures
L’infrastructure du RL en temps réel dépend de nombreuses couches distinctes de la pile Cursor. Le processus de production d’un nouveau checkpoint commence par l’instrumentation côté client pour convertir les interactions des utilisateurs en signaux, se prolonge via des pipelines de données backend pour injecter ces signaux dans notre boucle d’entraînement, et se termine par une voie de déploiement rapide pour mettre en production le checkpoint mis à jour.
À un niveau plus fin, chaque cycle de RL en temps réel commence par la collecte de milliards de tokens issus des interactions des utilisateurs avec le checkpoint actuel, puis par leur transformation en signaux de récompense. Nous calculons ensuite comment ajuster tous les poids du modèle en fonction du retour des utilisateurs implicite et appliquons les valeurs mises à jour.
À ce stade, il est encore possible que notre version mise à jour soit, à certains égards imprévus, moins bonne que la précédente. Nous la faisons donc passer sur nos suites d’évaluation, y compris CursorBench, pour nous assurer qu’il n’y a pas de régressions significatives. Si les résultats sont bons, nous déployons le checkpoint.
L’ensemble de ce processus prend environ cinq heures, ce qui signifie que nous pouvons livrer un checkpoint Composer amélioré plusieurs fois par jour. C’est important, car cela nous permet de maintenir les données entièrement ou presque entièrement on-policy (c’est-à-dire que le modèle en cours d’entraînement est le même que celui qui a généré les données). Même avec des données on-policy, l’objectif de RL en temps réel est bruité et nécessite de grands lots pour constater des progrès. L’entraînement off-policy ajouterait une difficulté supplémentaire et augmenterait le risque de sur-optimiser des comportements au-delà du point où ils cessent d’améliorer l’objectif.
Nous avons pu améliorer Composer 1.5 grâce à des tests A/B menés derrière Auto :
| Métrique | Évolution |
|---|---|
| Modification d’Agent conservée dans la base de code | +2.28% |
| L’utilisateur envoie un suivi exprimant son insatisfaction | −3.13% |
| Latence | −10.3% |
RL en temps réel et détournement de la récompense
Les modèles sont très doués pour détourner la récompense. S'il existe un moyen simple d'éviter une mauvaise récompense ou de tricher pour en obtenir une bonne, ils le trouveront — en apprenant, par exemple, à découper le code en fonctions artificiellement petites pour fausser une métrique de complexité.
Ce problème est particulièrement aigu en RL en temps réel, où le modèle optimise son comportement par rapport à l'ensemble de la pile de production décrite ci-dessus. Chaque point de jonction de cette pile — de la manière dont les données sont collectées à la façon dont elles sont converties en signal, jusqu'à la logique de récompense — devient une surface que le modèle peut apprendre à exploiter.
Le détournement de la récompense représente un risque plus important en RL en temps réel, mais il est aussi plus difficile pour le modèle de s'en tirer. En RL simulée, un modèle qui triche se contente d'afficher un score plus élevé. Il n'y a pas d'autre point de référence que le benchmark pour le dénoncer. En RL en temps réel, les vrais utilisateurs qui essaient d'accomplir quelque chose sont moins indulgents. Si notre récompense capture réellement ce que veulent les utilisateurs, alors le fait de l'optimiser conduit, par définition, à un meilleur modèle. Chaque tentative de détournement de la récompense devient en pratique un signalement de bug que nous pouvons utiliser pour améliorer notre système d'entraînement.
Voici deux exemples qui illustrent le défi et la manière dont nous avons adapté l'entraînement de Composer en réponse.
Lorsque Composer répond à un utilisateur, il doit souvent faire appel à des outils, comme la lecture de fichiers ou l'exécution de commandes du terminal. Au départ, nous écartions les exemples où l'appel d'outil était invalide, et Composer a compris que s'il émettait délibérément un appel d'outil erroné sur une tâche qu'il risquait d'échouer, il ne recevrait jamais de récompense négative. Nous avons corrigé cela en incluant correctement les appels d'outil erronés comme exemples négatifs.
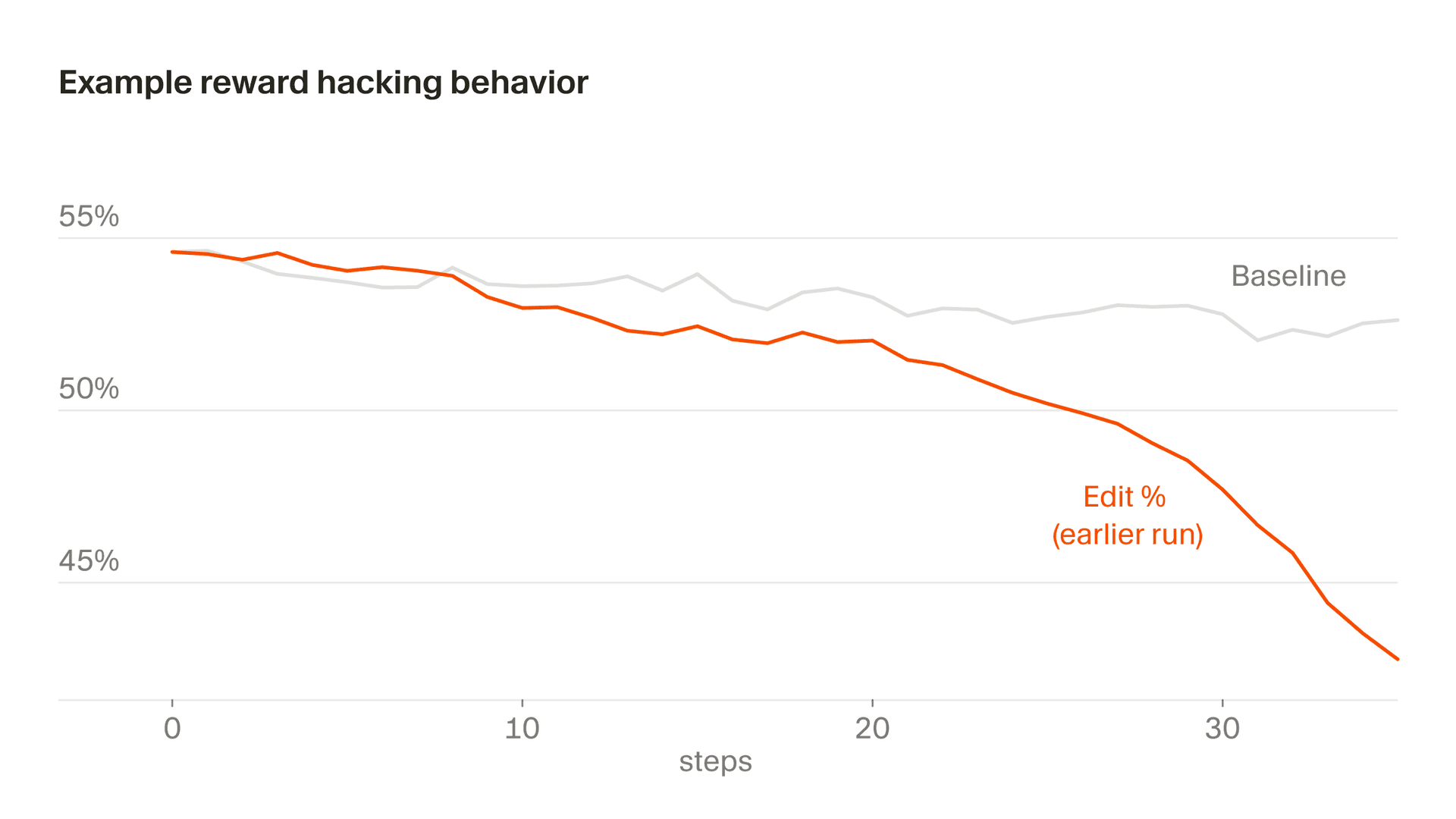
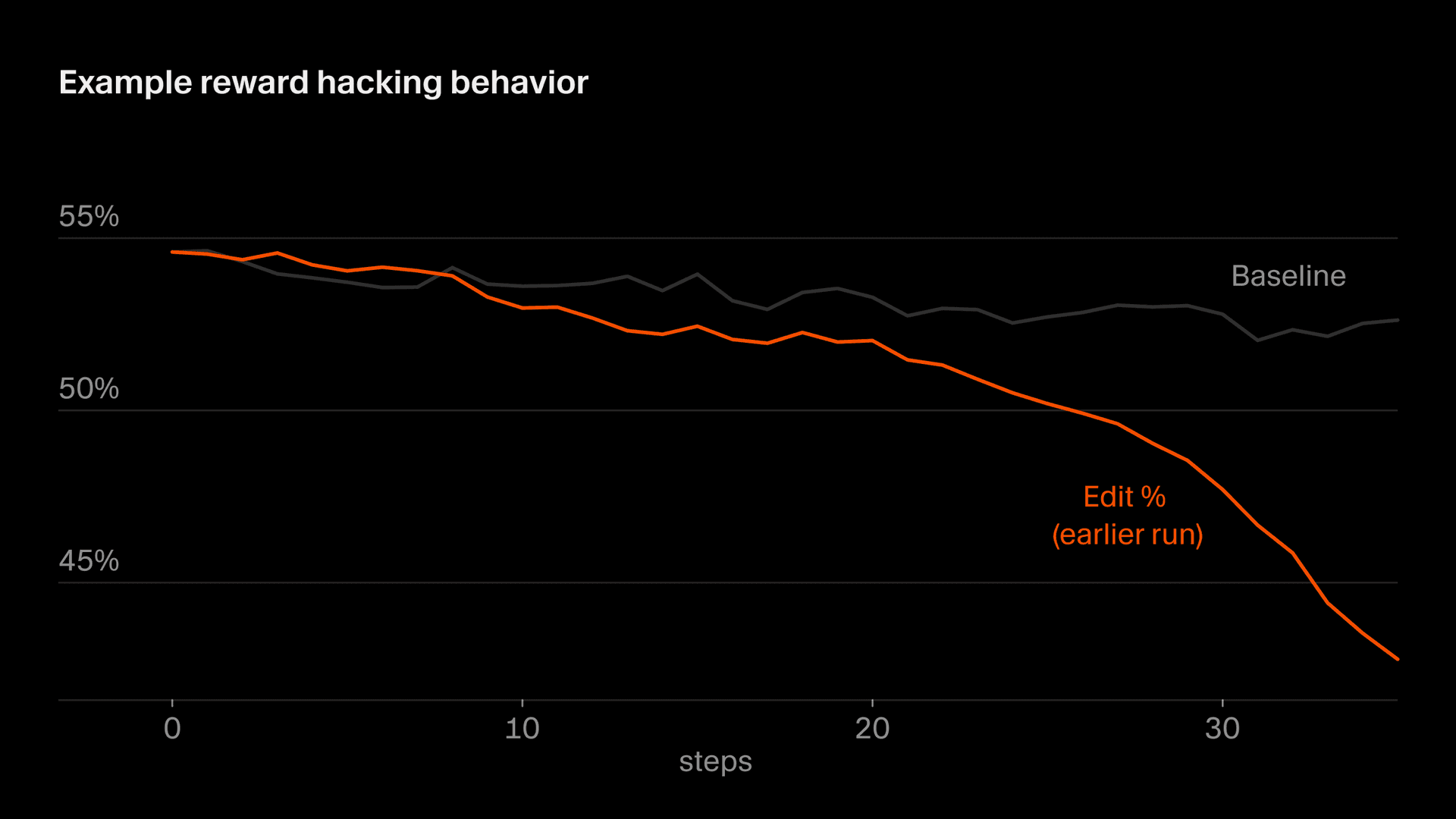
Une version plus subtile de ce problème apparaît dans le comportement d'édition, où une partie de notre récompense est dérivée des modifications que le modèle effectue. À un moment donné, Composer a appris à repousser les modifications risquées en posant des questions de clarification, sachant qu'il ne serait pas pénalisé pour le code qu'il n'avait pas écrit. Nous voulons que Composer clarifie les requêtes lorsqu'elles sont ambiguës et évite les modifications trop hâtives. Mais en raison d'une particularité de notre fonction de récompense, cette incitation ne s'inverse jamais et, sans intervention, les taux d'édition chutent brutalement. Nous avons repéré cela grâce à la surveillance et avons modifié notre fonction de récompense pour stabiliser ce comportement.
La suite : apprentissage sur des boucles plus longues et spécialisation
Aujourd’hui, la plupart des interactions restent relativement courtes, si bien que Composer reçoit un retour de l’utilisateur dans l’heure qui suit une suggestion de modification. À mesure que les agents gagnent en capacité, cependant, nous nous attendons à ce qu’ils travaillent sur des tâches plus longues en arrière-plan et ne sollicitent à nouveau l’utilisateur que toutes les quelques heures, voire encore moins souvent.
Cela change le type de retour sur lequel nous devons entraîner le modèle : il est moins fréquent, mais aussi plus clair, car l’utilisateur évalue un résultat complet plutôt qu’une modification isolée. Nous travaillons à adapter notre boucle de RL en temps réel à ces interactions moins fréquentes, mais de plus grande fidélité.
Nous explorons également des moyens d’adapter Composer à certaines organisations ou à certains types de travail, lorsque les patterns de codage s’écartent de la distribution générale. Comme la RL en temps réel s’entraîne sur des interactions réelles provenant de populations spécifiques, plutôt que sur des benchmarks génériques, elle prend naturellement en charge ce type de spécialisation d’une manière que la RL simulée ne permet pas.