Un rapport technique sur Composer 2

Nous avons publié sur arXiv un rapport technique sur l’entraînement de Composer 2, notre modèle de codage pour l’ingénierie logicielle agentique. Le rapport couvre l’ensemble du processus d’entraînement, du préentraînement continu sur un modèle de base ouvert, Kimi K2.5, à l’apprentissage par renforcement à grande échelle, avec un accent particulier sur une reproduction fidèle de l’environnement réel de Cursor.
Préentraînement continu et RL
Composer 2 est entraîné en deux phases : d’abord, un préentraînement continu sur un mélange de données mettant l’accent sur le code afin d’approfondir les connaissances du modèle de base en codage, puis un apprentissage par renforcement à grande échelle pour améliorer les performances de l’agent de bout en bout. Nous constatons que la réduction de la perte de préentraînement améliore les performances du RL en aval : de meilleures connaissances de base se traduisent de manière fiable par un meilleur agent.
L’entraînement RL de Composer 2 se déroule dans des sessions Cursor réalistes, avec les mêmes outils et le même harness que ceux utilisés par le modèle déployé, sur une distribution de problèmes qui reflète l’ensemble des demandes adressées par les développeurs à Composer. Nous constatons que l’entraînement RL améliore à la fois les performances moyennes et les performances best-of-K, ce qui suggère que le modèle apprend de nouvelles voies de résolution plutôt que de simplement se concentrer sur celles qu’il connaît déjà.
Évaluation en conditions réelles avec CursorBench
L'un des principaux défis dans la création de modèles de codage, c'est que les benchmarks publics ne reflètent souvent pas le travail que les développeurs font réellement. Les tâches sont trop détaillées, les solutions sont étroites et les bases de code sont de petite taille.
Nous avons créé CursorBench à partir de sessions réelles de codage de notre équipe d'ingénierie. Il inclut des tâches où le prompt est bref et ambigu, et où les solutions nécessitent des centaines de lignes de modifications dans de nombreux fichiers. Nous utilisons CursorBench tout au long de l'entraînement et de l'évaluation pour que le modèle reste aligné sur des problèmes réels.
Performance
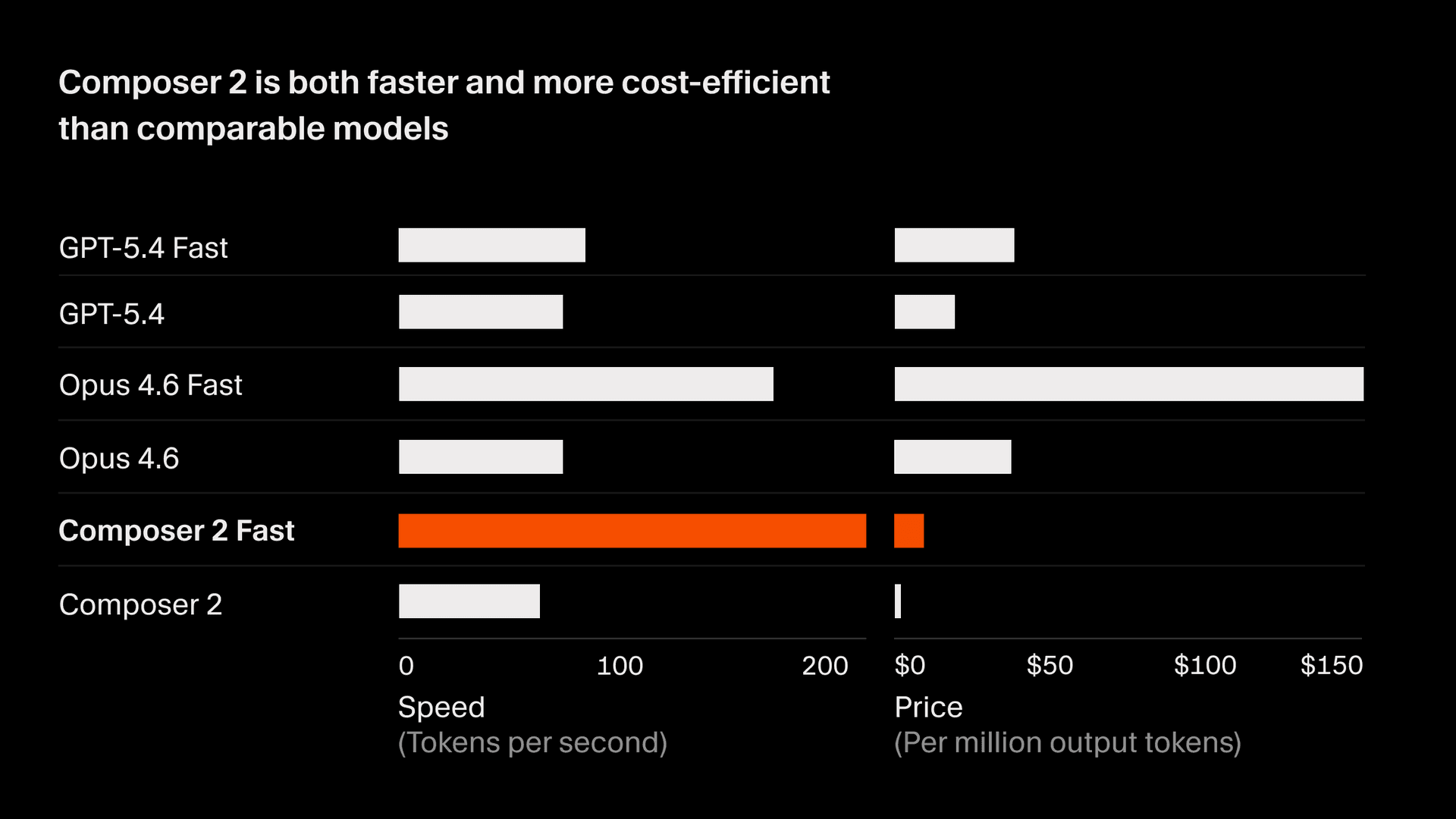
Sur CursorBench, Composer 2 obtient un score de 61,3, soit une amélioration de 37 % par rapport à Composer 1.5, et se révèle compétitif face aux modèles de pointe les plus avancés. Sur des benchmarks publics, Composer 2 obtient 73,7 sur SWE-bench Multilingual et 61,7 sur Terminal-Bench. Il atteint ce niveau avec un coût d’inférence nettement inférieur à celui de modèles comparables, offrant ainsi un compromis Pareto-optimal entre précision et coût pour des workflows interactifs de développement.



Infrastructure
L'entraînement de Composer 2 a nécessité d'importants développements d'infrastructure, avec des noyaux personnalisés à basse précision pour un entraînement MoE efficace sur des GPU Blackwell, un pipeline de RL entièrement asynchrone s'étendant sur plusieurs régions, ainsi qu'Anyrun, notre plateforme de calcul interne permettant d'exécuter des centaines de milliers d'environnements de codage isolés. Le rapport couvre l'ensemble de la stack, y compris notre approche de la synchronisation des poids, de la tolérance aux pannes et de la fidélité des environnements.
Le rapport entre dans bien plus de détails sur tous ces sujets, notamment avec des études d'ablation sur la recette d'entraînement, notre approche du façonnage du comportement des agents et la conception de notre suite d'évaluation.
Merci aux équipes à l'origine de Kimi K2.5, Ray, ThunderKittens, PyTorch, ainsi qu'à l'ensemble de la communauté open source. Nous tenons également à remercier Fireworks et Colfax pour leur collaboration et leur partenariat.
Lire le rapport technique complet ici.