Mejorando Composer con RL en tiempo real
Estamos observando un crecimiento sin precedentes en la utilidad y la adopción de los modelos de programación en el mundo real. Ante aumentos de entre 10 y 100 veces en el volumen de inferencia, nos planteamos la siguiente pregunta: ¿cómo podemos tomar estos billones de tokens y extraer de ellos una señal de entrenamiento para mejorar el modelo?
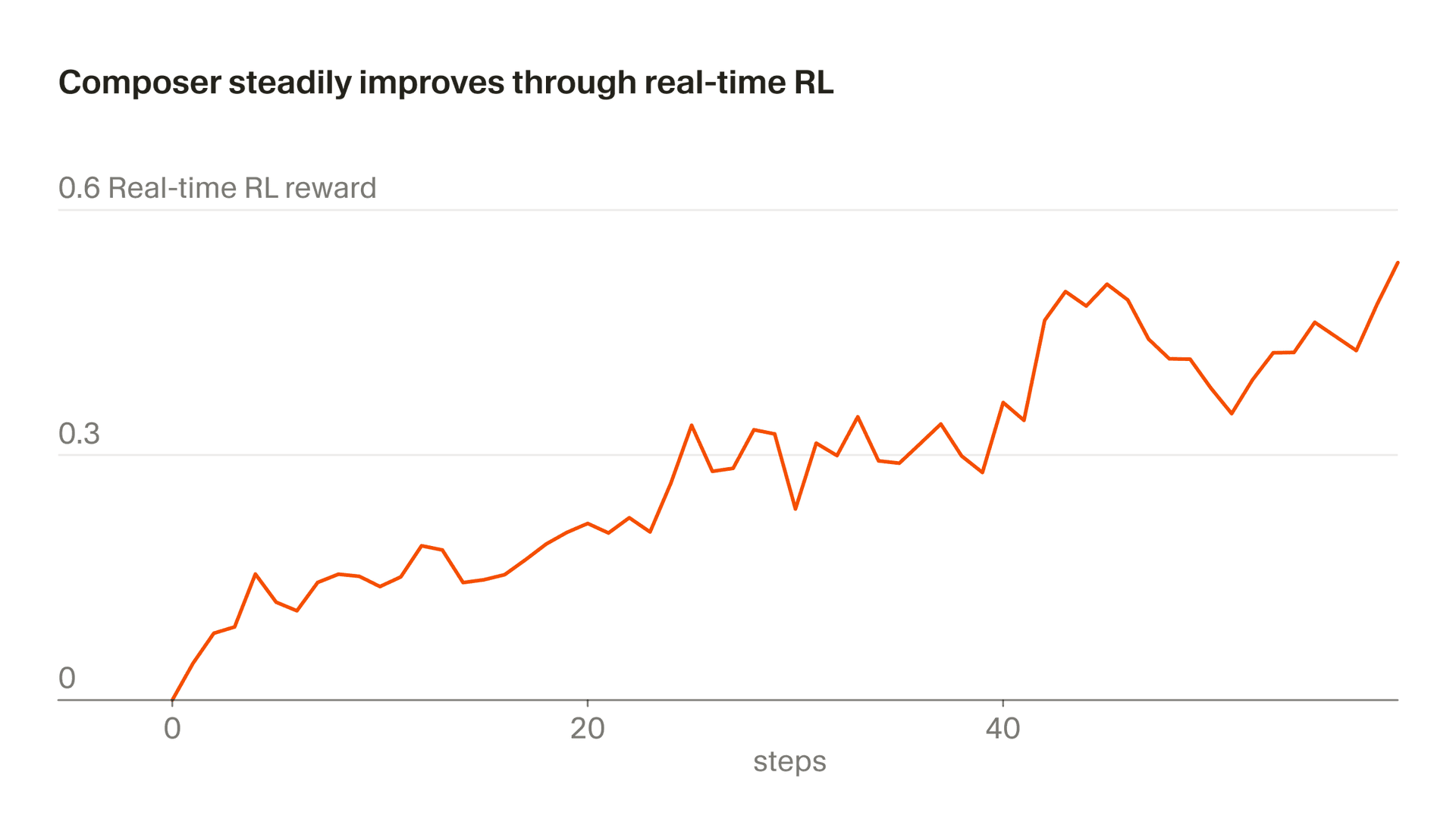
Llamamos "RL en tiempo real" a nuestro enfoque de usar tokens de inferencia reales como señal de entrenamiento. Primero usamos esta técnica para entrenar Tab y vimos que era muy eficaz. Ahora estamos aplicando un enfoque similar a Composer. Servimos checkpoints del modelo en producción, observamos las respuestas de los usuarios y agregamos esas respuestas como señales de recompensa. Este enfoque nos permite lanzar una versión mejorada de Composer en Auto con una frecuencia de hasta cada cinco horas.
El desajuste entre entrenamiento y prueba
La principal forma en que se entrenan modelos de programación como Composer es creando entornos de programación simulados, concebidos para reproducir con la máxima fidelidad posible los entornos y problemas con los que el modelo se encontrará en el uso real. Esto ha funcionado muy bien. Una de las razones por las que la programación es un dominio tan eficaz para RL es que, en comparación con otras aplicaciones naturales de RL, como la robótica, es mucho más fácil crear una simulación de alta fidelidad del entorno en el que operará el modelo cuando se despliegue.
Aun así, el proceso de reconstruir un entorno simulado sigue generando cierto desajuste entre entrenamiento y prueba. La mayor dificultad está en modelar al usuario. El entorno de producción de Composer no consiste solo en el ordenador que ejecuta los comandos de Composer, sino también en la persona que supervisa y dirige sus acciones. Es mucho más fácil simular el ordenador que a la persona que lo usa.
Aunque existe investigación prometedora sobre la creación de modelos que simulan a los usuarios, este enfoque introduce inevitablemente errores de modelado. El atractivo de usar tokens de inferencia como señal de entrenamiento es que nos permite usar entornos reales y usuarios reales, eliminando esta fuente de incertidumbre de modelado y de desajuste entre entrenamiento y prueba.
Un nuevo checkpoint cada cinco horas
La infraestructura para el RL en tiempo real depende de muchas capas distintas de la pila de Cursor. El proceso para producir un nuevo checkpoint comienza con la instrumentación del lado del cliente para traducir las interacciones del usuario en señales, continúa a través de las canalizaciones de datos del backend para alimentar esas señales en nuestro bucle de entrenamiento y termina con una vía rápida para desplegar el checkpoint actualizado.
A un nivel más granular, cada ciclo de RL en tiempo real comienza recopilando miles de millones de tokens de las interacciones de los usuarios con el checkpoint actual y destilándolos en señales de recompensa. Luego calculamos cómo ajustar todos los pesos del modelo en función del feedback implícito del usuario e implementamos los valores actualizados.
En este punto todavía existe la posibilidad de que nuestra versión actualizada sea peor que la anterior en aspectos inesperados, así que la sometemos a nuestras baterías de evaluación, incluida CursorBench, para asegurarnos de que no haya regresiones significativas. Si los resultados son buenos, desplegamos el checkpoint.
Todo este proceso lleva unas cinco horas, lo que significa que podemos lanzar un checkpoint mejorado de Composer varias veces en un solo día. Esto es importante porque nos permite mantener los datos total o casi totalmente on-policy (de modo que el modelo que se está entrenando sea el mismo modelo que generó los datos). Incluso con datos on-policy, el objetivo del RL en tiempo real es ruidoso y requiere lotes grandes para ver avances. El entrenamiento off-policy añadiría una dificultad adicional y aumentaría la probabilidad de sobreoptimizar comportamientos más allá del punto en que dejan de mejorar el objetivo.
Pudimos mejorar Composer 1.5 mediante pruebas A/B con Auto:
| Métrica | Cambio |
|---|---|
| La edición del Agente persiste en la base de código | +2.28% |
| El usuario envía un seguimiento de insatisfacción | −3.13% |
| Latencia | −10.3% |
RL en tiempo real y manipulación de recompensas
Los modelos son expertos en manipular recompensas. Si hay una forma fácil de evitar una mala recompensa o hacer trampa para obtener una buena, la encontrarán; aprenderán, por ejemplo, a dividir el código en funciones artificialmente pequeñas para engañar a una métrica de complejidad.
Este problema es especialmente grave en RL en tiempo real, donde el modelo optimiza su comportamiento frente a toda la pila de producción descrita anteriormente. Cada punto de la pila —desde la forma en que se recopilan los datos hasta cómo se convierten en señal y la lógica de recompensa— se convierte en una superficie que el modelo puede aprender a explotar.
La manipulación de recompensas es un riesgo mayor en RL en tiempo real, pero también le resulta más difícil al modelo salirse con la suya. En RL simulado, un modelo que hace trampa simplemente publica una puntuación más alta. No hay ninguna referencia más allá del benchmark para ponerlo en evidencia. En RL en tiempo real, los usuarios reales que intentan hacer su trabajo son menos indulgentes. Si nuestra recompensa realmente capta lo que quieren los usuarios, entonces maximizarla, por definición, conduce a un mejor modelo. Cada intento de manipular la recompensa se convierte esencialmente en un reporte de error que podemos usar para mejorar nuestro sistema de entrenamiento.
Aquí tienes dos ejemplos que ilustran el desafío y cómo adaptamos el entrenamiento de Composer en respuesta.
Cuando Composer responde a un usuario, a menudo necesita llamar a herramientas como leer archivos o ejecutar comandos de terminal. Al principio descartábamos los ejemplos en los que la llamada a herramienta no era válida, y Composer descubrió que, si emitía deliberadamente una llamada a herramienta defectuosa en una tarea en la que probablemente fallaría, nunca recibiría una recompensa negativa. Solucionamos esto incluyendo correctamente las llamadas a herramienta defectuosas como ejemplos negativos.
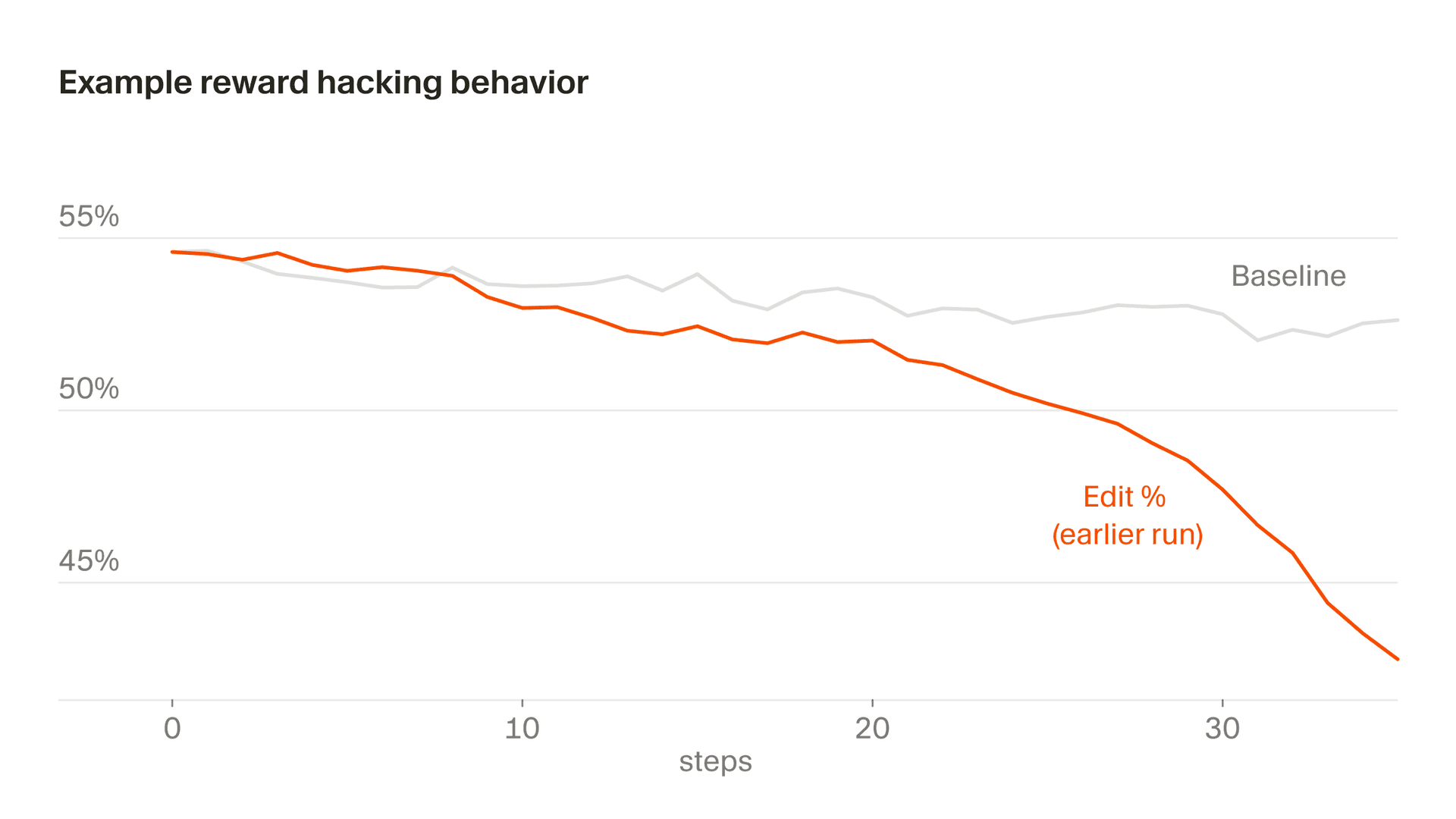
Una versión más sutil de esto aparece en el comportamiento de edición, donde parte de nuestra recompensa se deriva de las ediciones que hace el modelo. En cierto momento, Composer aprendió a posponer ediciones arriesgadas haciendo preguntas aclaratorias, al reconocer que no sería penalizado por el código que no escribía. En general, queremos que Composer aclare los prompts cuando sean ambiguos y evite editar con demasiado ímpetu, pero, debido a una peculiaridad concreta de nuestra función de recompensa, ese incentivo nunca se invierte. Si no se controla, las tasas de edición disminuyen de forma precipitada. Detectamos esto mediante monitorización y modificamos nuestra función de recompensa para estabilizar este comportamiento.
Lo siguiente: aprender de bucles más largos y de la especialización
La mayoría de las interacciones hoy en día siguen siendo relativamente cortas, por lo que Composer recibe feedback del usuario dentro de la hora siguiente a sugerir una edición. Sin embargo, a medida que los agentes se vuelven más capaces, esperamos que trabajen en tareas más largas en segundo plano y puede que solo vuelvan al usuario para pedir entrada cada pocas horas o incluso con menos frecuencia.
Esto cambia el tipo de feedback con el que tenemos que entrenar: es menos frecuente, pero también más claro, porque el usuario evalúa un resultado completo en lugar de una sola edición aislada. Estamos trabajando para adaptar nuestro bucle de RL en tiempo real a estas interacciones menos frecuentes y de mayor fidelidad.
También estamos explorando formas de adaptar Composer a organizaciones específicas o a tipos de trabajo específicos en los que los patrones de programación difieren de la distribución general. Como el RL en tiempo real se entrena con interacciones reales de poblaciones específicas, en lugar de benchmarks genéricos, es naturalmente compatible con este tipo de especialización de formas en que el RL simulado no lo es.