Entrenamiento de Composer para horizontes más largos
Entrenamos a Composer para tareas de largo horizonte mediante un proceso de aprendizaje por refuerzo llamado autoresumen. Al incorporar el autoresumen al entrenamiento de Composer, podemos obtener señales de entrenamiento a partir de trayectorias mucho más largas que la ventana de contexto máxima del modelo. Esto permite que Composer aprenda a trabajar en tareas de programación exigentes que requieren cientos de acciones.
Los límites de las técnicas de compactación
En CursorBench, nuestro conjunto interno de pruebas comparativas, observamos que un mejor rendimiento en tareas complejas de programación del mundo real se correlaciona directamente con un mayor razonamiento y una exploración más profunda de la base de código. A medida que los usuarios trabajan con agentes para abordar tareas más difíciles y ambiciosas, esperamos que los beneficios del razonamiento y la exploración aumenten aún más.
Sin embargo, uno de los principales desafíos es que las trayectorias de los agentes están creciendo más rápido que la longitud de contexto de los modelos. Muchos sistemas de ejecución de agentes intentan resolver esto usando la compactación como un paso intermedio en el flujo de trabajo del agente. Cuando un agente alcanza su límite de contexto, el sistema de ejecución transforma el contexto a una longitud menor y continúa la generación del agente desde donde se quedó.
En la práctica, la compactación suele gestionarse en el sistema de ejecución de una de estas dos formas: ya sea en el espacio de texto mediante un modelo de resumen guiado por prompts, o mediante una ventana de contexto deslizante en la que el modelo descarta el contexto más antiguo. Los investigadores también han comenzado a explorar métodos de compactación en espacio latente, donde el modelo recuerda el contexto como vectores en lugar de texto, aunque actualmente estos enfoques son mucho más lentos que los métodos basados en texto.
Estos enfoques de compactación comparten la desventaja de que pueden hacer que el modelo olvide información crítica del contexto, lo que reduce su eficacia a medida que avanza en tareas de larga duración.
Autoresumen como comportamiento aprendido
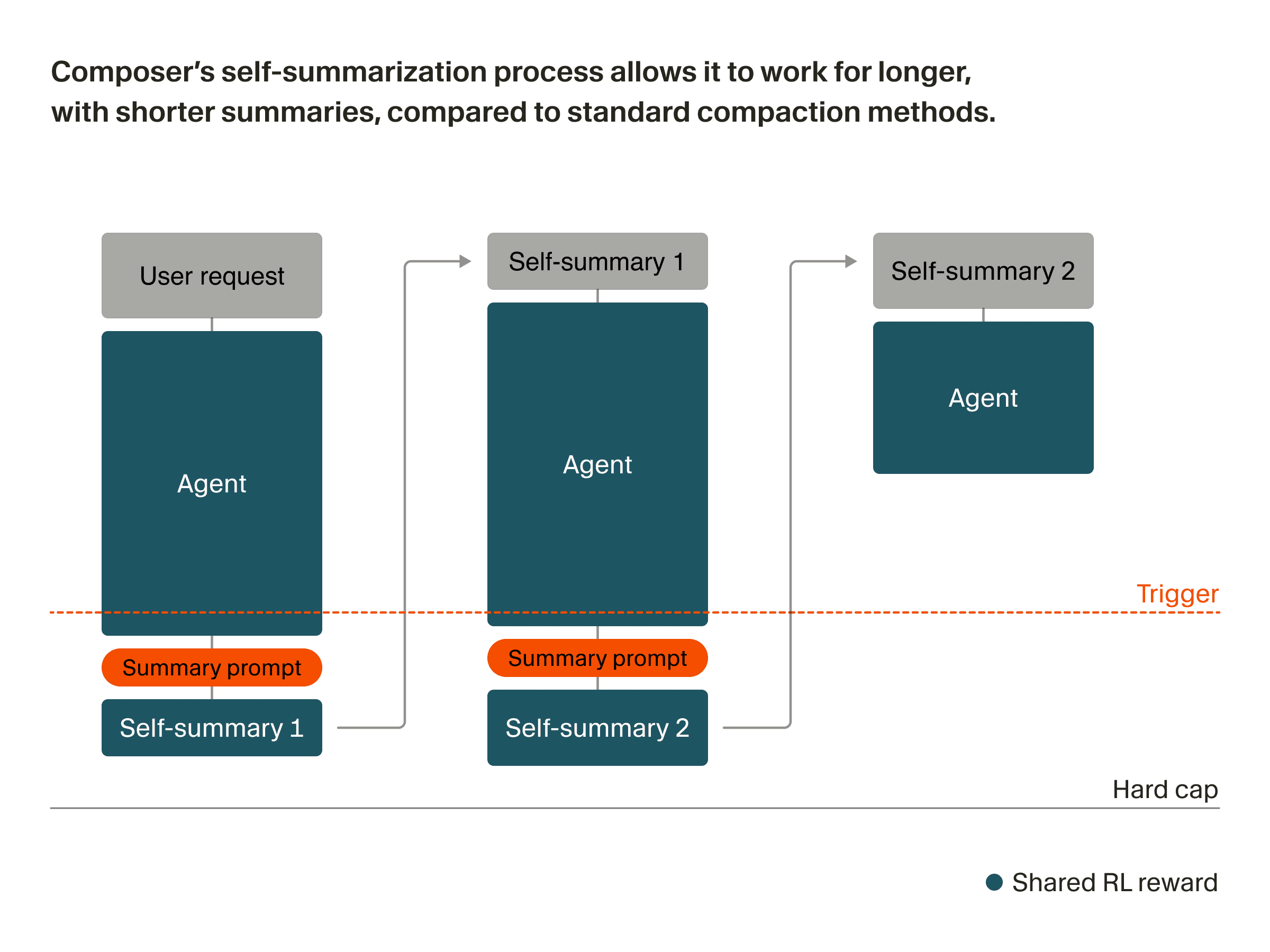
Composer es un modelo especializado diseñado para programación con agentes y entrenado mediante aprendizaje por refuerzo en el entorno de agentes de Cursor. Esto permite entrenarlo con compactación en el bucle, mejorando su capacidad para identificar la información más crítica que debe resumir y conservar.
A medida que Composer avanza en una tarea, se acerca a un umbral fijo de longitud de contexto, momento en el que se detiene para resumir su propio contexto antes de continuar. Más concretamente, el proceso de autoresumen funciona así:
-
Composer genera a partir de un prompt hasta alcanzar un umbral fijo de longitud de tokens.
-
Insertar una consulta sintética que le pide al modelo resumir el contexto actual.
-
Se le da al modelo un espacio auxiliar para pensar en el mejor resumen y luego genera un contexto condensado.
-
Composer vuelve al paso 1 con el contexto condensado, que incluye el resumen más el estado de la conversación (estado del plan, tareas restantes, número de resúmenes previos, etc.).
Para que Composer haga esto bien durante la inferencia, incorporamos el mismo procedimiento de resumen al entrenamiento. Cada rollout de entrenamiento puede implicar múltiples generaciones encadenadas mediante resúmenes, en lugar de un único par prompt-respuesta. Esto significa que los propios autoresúmenes forman parte de lo que se recompensa.
Desde una perspectiva técnica, esto no requiere cambios significativos en el entrenamiento. Usamos la recompensa final para todos los tokens producidos por el modelo en la cadena. Esto aumenta el peso tanto de las respuestas del agente en trayectorias buenas como de los autoresúmenes que hicieron que funcionaran. Al mismo tiempo, los resúmenes deficientes que perdieron información crítica reciben menos peso. A medida que Composer se entrena, aprende a usar este proceso de autoresumen para ampliar el contexto. En ejemplos difíciles, a menudo se autorresume varias veces.
Compactación eficiente en tokens
Para evaluar el autoresumen, lo comparamos con una referencia de compactación basada en prompts muy optimizada. Estudiamos el problema en un conjunto de tareas complejas de ingeniería de software mientras variamos el disparador de compactación.
En el enfoque de compactación de referencia, el prompt de resumen tiene miles de tokens e incluye casi una docena de secciones cuidadosamente redactadas que describen el contenido que debe preservarse en el resumen. El contexto compactado resultante también supera, en promedio, los 5.000 tokens y contiene muchas secciones estructuradas que describen información crítica del contexto.
En cambio, como Composer está entrenado para autorresumirse, necesita un prompt muy breve que contiene poco más que "Por favor, resume la conversación". Los resúmenes que genera tienen, en promedio, solo unos 1.000 tokens, ya que aprende a decidir según el contexto qué información de mayor valor conviene conservar.
Probamos Composer en dos entornos de prueba con contexto restringido para medir el impacto del autoresumen: uno con un disparador de 80k tokens y otro con un disparador de 40k (lo que significa resúmenes más frecuentes). En ambos escenarios, el autoresumen produce resultados significativamente mejores en CursorBench con compactaciones mucho más eficientes en tokens. Reduce de forma sistemática el error de compactación en un 50%, incluso en comparación con el enfoque de referencia específico, mientras usa una quinta parte de los tokens y reutiliza la caché KV (los cálculos intermedios almacenados de tokens anteriores).


Resolviendo problemas difíciles
La gran promesa de la compactación es permitir que los modelos resuelvan de una sola pasada problemas difíciles que requieren largas cadenas de razonamiento. En nuestro entrenamiento actual de Composer 2, vemos a menudo que esto sucede. Como caso de estudio, consideramos un problema de Terminal-Bench 2.0 conocido como make-doom-for-mips. El problema es tan conciso como desafiante:
He proporcionado /app/doomgeneric/, el código fuente de doom. También he escrito un doomgeneric_img.c especial que quiero que uses, que escribirá cada fotograma renderizado en /tmp/frame.bmp. Por último, he proporcionado vm.js, que esperará un archivo llamado doomgeneric_mips y lo ejecutará. Por favor, averigua el resto…
Aunque es bastante fácil de describir, este problema es lo suficientemente desafiante como para que varios modelos potentes no consigan resolverlo correctamente según las métricas oficiales publicadas.
Al probar un checkpoint preliminar de investigación de Composer, descubrimos que era capaz de resolver este problema correctamente. La solución requirió desarrollar y probar una cantidad considerable de código, además de explorar algunas implementaciones alternativas. Aquí hay una imagen renderizada durante el proceso de resolución del problema:

En total, Composer trabajó durante 170 turnos para encontrar una solución exacta, creando en el camino auto-resúmenes de forma compacta, legible y estructurada para humanos. Auto-resumió más de 100,000 tokens hasta reducirlos a los 1,000 que creía que más le ayudarían a resolver el problema:
## Resumen de la conversación
### Objetivo del usuario
Crear un ELF MIPS little-endian llamado doomgeneric_mips para que `node vm.js` pueda ejecutarlo: stdout debe funcionar y los fotogramas deben escribirse en `/tmp/frame.bmp` usando el archivo doomgeneric_img.c proporcionado (y las fuentes de doomgeneric en `/app/doomgeneric/`).
### Qué se implementó
1. libc independiente para la VM de JS (`/app/mips_freestanding/`)
- La VM implementa flags de apertura al estilo Linux, pero los números de syscall no son los reales de MIPS Linux (0=read, 1=write, 2=open, 3=close, 8=lseek, 201=time, 38=rename, 39=mkdir). El uso normal de mipsel-linux-gnu-gcc + glibc emplearía números del estilo 4003+ y no funcionaría.
- `my_libc.c` + `vm_syscall.h`: esas syscalls, más `malloc`/`free`/`realloc` mínimos, `stdio` (`fopen`/`fread`/`fwrite`/…), cadenas, subconjunto de `printf`, `qsort`, `sin`/`atan`/`fabs`, `strdup`, `abs`, stub de `system`, etc.
2. `doomgeneric_img.c` (en `/app/doomgeneric/doomgeneric/`)
- Usa `my_stdlib.h`.
- `DG_DrawFrame`: escribe cada fotograma en `/tmp/frame.bmp` (BMP de 32 bits).
- `main`: `argc`/`argv` seguros (argv de reserva si es nulo), luego `doomgeneric_Create` → bucle infinito `doomgeneric_Tick()` (mismo patrón que otros front ends de doomgeneric).
3. Compilación — `/app/doomgeneric/doomgeneric/Makefile.mips`
- `mipsel-linux-gnu-gcc`, `-fno-pic -mno-abicalls`, `-static -nostdlib`, `-Wl,-e,main`, enlace con `libgcc`.
- Era necesario evitar PIC: la entrada en `main` con `$t9` sin definir rompía el GOT relativo a GP; sin PIC se solucionó.
- Objetos: lista completa de doom con `doomgeneric_img.o` en lugar de xlib; sin `deh_str.o` (solo encabezado).
- `i_system.c`: `DEFAULT_RAM` / `MIN_RAM` sobreescribibles mediante `-D`; la compilación usó `-DDEFAULT_RAM=4 -DMIN_RAM=4` para reducir la zona de memoria de la VM.
- Resultado: `/app/doomgeneric_mips`. No eliminar símbolos — la VM resuelve `main` desde `.symtab`.
4. Cambios en `vm.js` (importantes para el otro asistente)
- OOM: la memoria `{}` simple saturó V8 cuando doom accedió a muchas palabras.
- `runElf`: ahora asigna `Uint32Array` para RAM baja (96 MB desde `0x400000`) + pila (~8 MB desde `0x7f800000`), carga `.text`/`.data`/`.rodata` en el búfer bajo, devuelve `{ lowMem, stkMem, memLowBase, …, entry_point }` en lugar de un objeto `memory` gigante.
- `MIPSVM`: `memGetWord` / `memSetWord` enrutan a través de esos búferes; `this.memory` disperso eliminado efectivamente para escrituras (corrección de OOM); `memGetWord` fuera de límites → 0 (puede ocultar errores).
- Todos los helpers de `lw`/`sw`/byte y la obtención de instrucciones de `runProgram` usan `memGetWord`/`memSetWord`. Al final del script se conectan `vm._lowMem` etc. desde `runElf`.
### Errores / correcciones (resumen)
- Syscalls incorrectas → libc personalizada + números de syscall de la VM.
- Errores de enlace → se agregaron `strdup`, `strstr`, `abs`, `putchar`, `puts`, `atof`, `system`, `remove`/`rename`; se eliminó el inexistente `deh_str.o`.
- Fallo inmediato en la entrada → `-fno-pic -mno-abicalls`.
- OOM en Node → memoria de VM respaldada por ArrayBuffer; se eliminaron las escrituras ilimitadas en `this.memory`.
- `r_segs.c`: `SHRT_MAX` → agregado a `limits.h`.
### Qué sigue roto / pendiente para el siguiente asistente
- `/tmp/frame.bmp` nunca apareció en las pruebas: la ejecución termina con `Program terminated at PC=0x400151`, `Executed 626581578` instructions. `0x400150` es el símbolo `abort` (rama ajustada a sí misma). Algo termina saltando a `abort`, sin un bucle de juego limpio que dibuje fotogramas.
- La zona de 4 MB (`DEFAULT_RAM=4`) puede ser demasiado pequeña para jugar con un IWAD real → fallos al estilo `Z_Malloc` / OOM u otro comportamiento indefinido; vale la pena probar `DEFAULT_RAM=6`, un `HEAP_SIZE` mayor en `my_libc.c` (se redujo a 14 MB) y asegurarse de que `memGetWord` fuera de límites no enmascare fallos reales.
- Próximos pasos concretos: identificar quién llama a `abort` (p. ej., trap, ruta de libgcc, asignación fallida); solucionar la ruta de I_Error en sistemas no Windows (actualmente puede llamar a `ZenityErrorBox` / rutas inesperadas); confirmar `doomgeneric_Create` → `D_DoomMain` → … → `doomgeneric_Tick`/`D_Display` → `DG_DrawFrame`; verificar `fopen("/tmp/frame.bmp","wb")` + vaciado de `SYS_close` en la VM; volver a ejecutar hasta que `/tmp/frame.bmp` exista y stdout tenga sentido.
### Rutas
- ELF: `/app/doomgeneric_mips`
- Compilación: `/app/doomgeneric/doomgeneric/Makefile.mips`
- Front end: `/app/doomgeneric/doomgeneric/doomgeneric_img.c`
- Libc: `/app/mips_freestanding/my_libc.c`, `/app/mips_freestanding/include/*`
- VM: `/app/vm.js` (modelo de memoria parcheado)
- IWAD usado localmente: `/app/doom1.wad` (para pruebas)Hacia un futuro de largo horizonte
Al incorporar la compactación en el ciclo de entrenamiento, Composer aprende un mecanismo explícito para trasladar de forma eficiente la información crítica hacia adelante y se vuelve más capaz en tareas exigentes. Nuestro trabajo sobre la autosumariación es un paso hacia nuestro objetivo más amplio de entrenar a Composer en procesos aún más largos y complejos, como la coordinación entre múltiples agentes. Seguimos viendo que un mejor entrenamiento de los modelos mejora el alcance y la inteligencia de estos sistemas con agentes.
También compartiremos más sobre la próxima versión de Composer en breve.