Descubrimiento dinámico de contexto
Los agentes de programación están cambiando rápidamente la forma en que se desarrolla software. Su rápida mejora se debe tanto a la mejora de los modelos orientados a agentes como a una mejor ingeniería de contexto para guiarlos.
El harness del agente de Cursor —las instrucciones y herramientas que proporcionamos al modelo— está optimizado individualmente para cada nuevo modelo de frontera con el que somos compatibles. Sin embargo, hay mejoras de ingeniería de contexto que podemos aplicar, como la forma en que recopilamos contexto y optimizamos el uso de tokens a lo largo de una trayectoria prolongada, que se aplican a todos los modelos dentro de nuestro harness.
A medida que los modelos mejoran como agentes, hemos tenido éxito al proporcionar menos detalles desde el principio, lo que facilita que el agente obtenga por sí mismo el contexto relevante. A este patrón lo llamamos descubrimiento dinámico de contexto, en contraste con el contexto estático, que siempre se incluye.
Archivos para el descubrimiento dinámico de contexto
El descubrimiento dinámico de contexto es mucho más eficiente en el uso de tokens, ya que solo se incorporan los datos necesarios a la ventana de contexto. También puede mejorar la calidad de la respuesta del agente al reducir la cantidad de información potencialmente confusa o contradictoria en la ventana de contexto.
Así es como hemos utilizado el descubrimiento dinámico de contexto en Cursor:
- Convertir respuestas largas de herramientas en archivos
- Usar el historial del chat durante la generación de resúmenes
- Admitir el estándar abierto Agent Skills
- Cargar de forma eficiente solo las herramientas MCP necesarias
- Considerar todas las sesiones de terminal integradas como archivos
1. Convertir respuestas largas de herramientas en archivos
Las llamadas a herramientas pueden aumentar drásticamente la ventana de contexto al devolver una respuesta JSON grande.
Para las herramientas propias de Cursor, como editar archivos y buscar en la base de código, podemos evitar el inflado del contexto con definiciones de herramientas inteligentes y formatos de respuesta mínimos, pero las herramientas de terceros (es decir, comandos de shell o llamadas MCP) no reciben de forma nativa este mismo tratamiento.
El enfoque común que toman los agentes de programación es truncar los comandos de shell largos o los resultados de MCP. Esto puede provocar pérdida de datos, que podría incluir información importante que quieres en el contexto. En Cursor, en cambio escribimos la salida en un archivo y le damos al agente la capacidad de leerlo. El agente llama a tail para revisar el final y luego leer más si lo necesita.
Esto ha dado como resultado menos resúmenes innecesarios al alcanzar los límites de contexto.
2. Consultar el historial de chat durante el resumen
Cuando se llena la ventana de contexto del modelo, Cursor inicia un paso de resumen para darle al agente una nueva ventana de contexto con un resumen de su trabajo hasta el momento.
Pero el conocimiento del agente puede degradarse después del resumen, ya que es una compresión con pérdida del contexto. El agente podría haber olvidado detalles cruciales sobre su tarea. En Cursor, usamos el historial de chat como archivos para mejorar la calidad del resumen.


Después de que se alcanza el límite de la ventana de contexto, o cuando el usuario decide resumir manualmente, le damos al agente una referencia al archivo de historial. Si el agente sabe que necesita más detalles que faltan en el resumen, puede buscar en el historial para recuperarlos.
3. Compatibilidad con el estándar abierto Agent Skills
Cursor es compatible con Agent Skills, un estándar abierto para extender agentes de programación con capacidades especializadas. De forma similar a otros tipos de Rules, las Skills se definen mediante archivos que le indican al agente cómo desempeñarse en una tarea específica de un dominio.
Las Skills también incluyen un nombre y una descripción que pueden incluirse como "contexto estático" en el system prompt. El agente luego puede hacer descubrimiento dinámico de contexto para incorporar las Skills relevantes, usando herramientas como grep y la búsqueda semántica de Cursor.
Las Skills también pueden agrupar ejecutables o scripts relevantes para la tarea. Dado que son solo archivos, el agente puede encontrar fácilmente qué es relevante para una Skill en particular.
4. Cargar de forma eficiente solo las herramientas MCP necesarias
MCP es útil para acceder a recursos protegidos mediante OAuth. Eso puede incluir registros de producción, archivos de diseño externos o contexto y documentación internos para una empresa.
Algunos servidores MCP incluyen muchas herramientas, a menudo con descripciones extensas, lo que puede inflar significativamente la ventana de contexto. La mayoría de estas herramientas no se usan, aunque siempre se incluyen en el prompt. Esto se agrava si utilizas varios servidores MCP.
No es realista esperar que cada servidor MCP se optimice para esto. Creemos que es responsabilidad de los agentes de programación reducir el uso de contexto. En Cursor, ofrecemos descubrimiento dinámico de contexto para MCP sincronizando las descripciones de herramientas en una carpeta.1
El agente ahora solo recibe una pequeña cantidad de contexto estático, incluidos los nombres de las herramientas, lo que lo lleva a buscar herramientas cuando la tarea lo requiere. En una prueba A/B, descubrimos que, en ejecuciones en las que se invocaba una herramienta MCP, esta estrategia redujo el total de tokens del agente en un 46,9% (estadísticamente significativo, con una alta variabilidad según el número de MCP instalados).
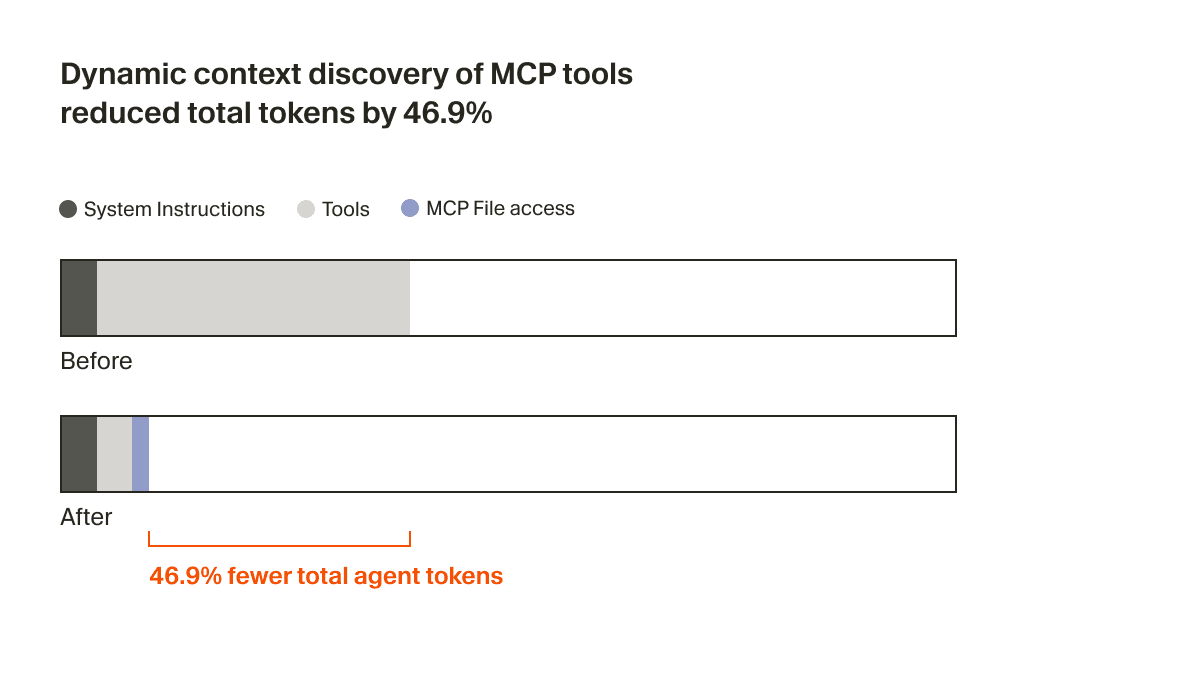
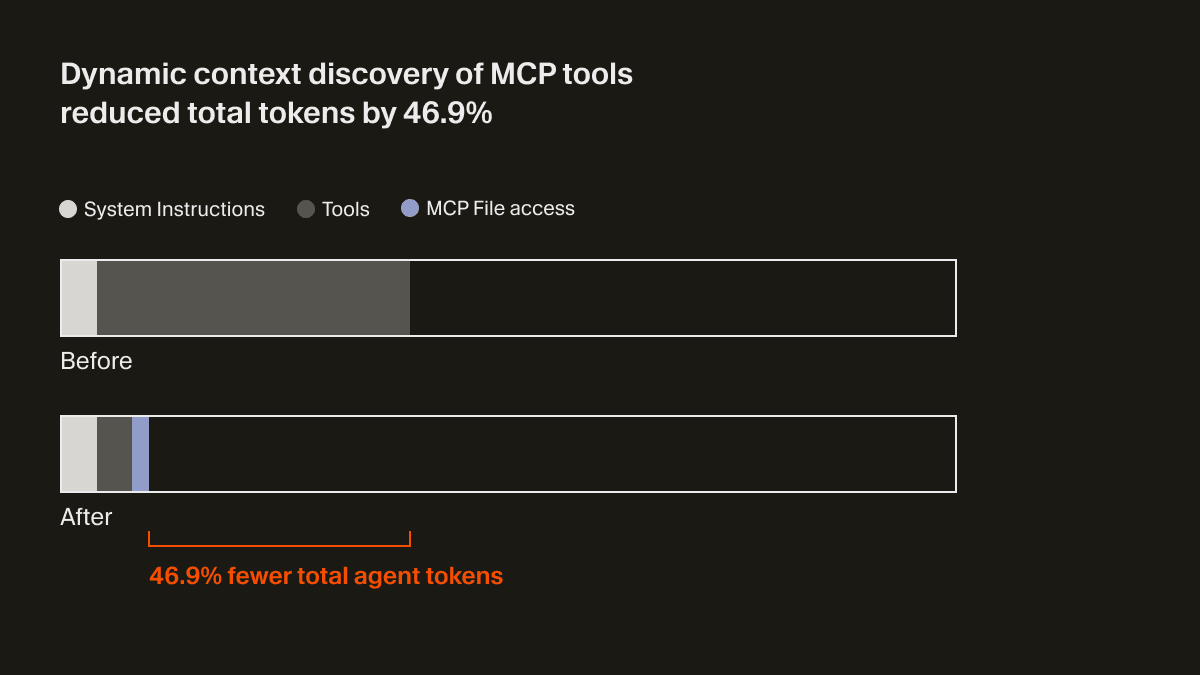
Este enfoque basado en archivos también permite comunicar el estado de las herramientas MCP al agente. Por ejemplo, antes, si un servidor MCP necesitaba volver a autenticarse, el agente se olvidaba por completo de esas herramientas, dejando al usuario confundido. Ahora puede avisar proactivamente al usuario de que debe volver a autenticarse.
5. Considerar todas las sesiones de terminal integrado como archivos
En lugar de tener que copiar y pegar la salida de una sesión de terminal en la entrada del agente, Cursor ahora sincroniza las salidas del terminal integrado con el sistema de archivos local.
Esto facilita preguntar "¿por qué falló mi comando?" y permite que el agente entienda a qué te estás refiriendo. Dado que el historial del terminal puede ser largo, el agente puede buscar con grep solo las salidas relevantes, lo cual es útil para registros de un proceso de larga duración como un servidor.
Esto refleja lo que ven los agentes de programación basados en CLI, con la salida previa del shell en contexto, pero descubierta de forma dinámica en lugar de insertada estáticamente.
Abstracciones simples
No está claro si los archivos serán la interfaz final para las herramientas basadas en LLM.
Pero a medida que los agentes de programación mejoran rápidamente, los archivos han sido una primitiva simple y potente de usar, y una opción más segura que otra abstracción más que no puede tener plenamente en cuenta el futuro. Mantente atento: pronto compartiremos mucho más trabajo interesante en este espacio.
Estas mejoras estarán disponibles para todos los usuarios en las próximas semanas. Las técnicas descritas en este artículo del blog son el trabajo de muchos empleados de Cursor, incluidos Lukas Moller, Yash Gaitonde, Wilson Lin, Jason Ma, Devang Jhabakh y Jediah Katz. Si te interesa resolver las tareas de programación más difíciles y ambiciosas usando IA, nos encantaría saber de ti. Escríbenos a hiring@cursor.com.
- Consideramos un enfoque basado en la búsqueda de herramientas, pero eso dispersaría las herramientas en un índice plano. En su lugar, creamos una carpeta por servidor, manteniendo las herramientas de cada servidor agrupadas lógicamente. Cuando el modelo enumera una carpeta, ve todas las herramientas de ese servidor juntas y puede entenderlas como una unidad coherente. Los archivos también permiten búsquedas más potentes. El agente puede usar toda la gama de parámetros de
rgo inclusojqpara filtrar descripciones de herramientas. ↩