Presentamos Composer 2
Composer 2 ya está disponible en Cursor.
Ofrece capacidades de programación de vanguardia y su precio es de 2.50/M de tokens de salida, lo que la convierte en una nueva combinación óptima de inteligencia y costo. También publicamos un informe técnico sobre cómo lo entrenamos.


Inteligencia de programación de vanguardia
Estamos mejorando rápidamente la calidad de nuestro modelo. Composer 2 ofrece mejoras notables en todos los benchmarks que evaluamos, incluidos Terminal-Bench 2.01 y SWE-bench Multilingual:
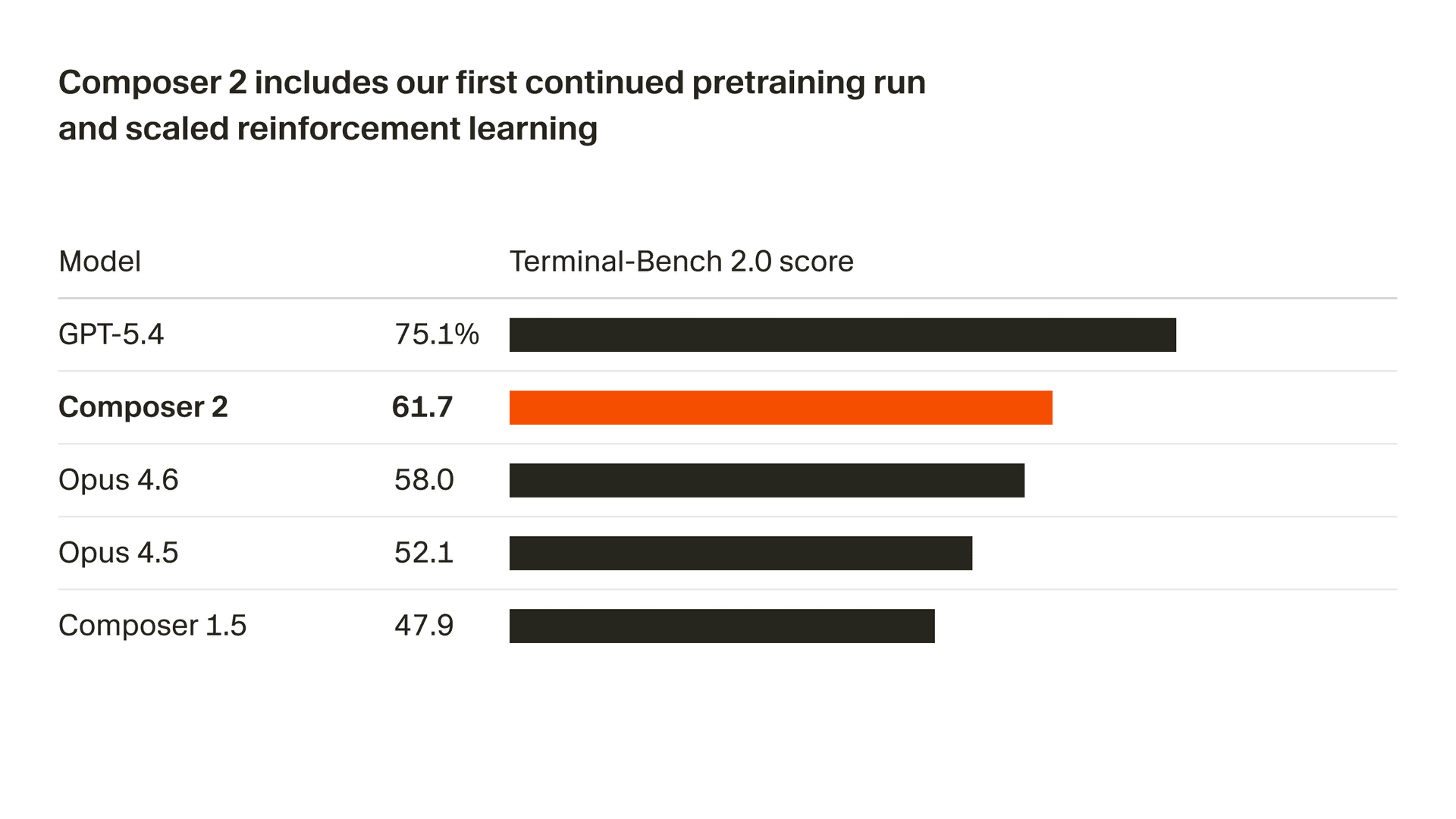
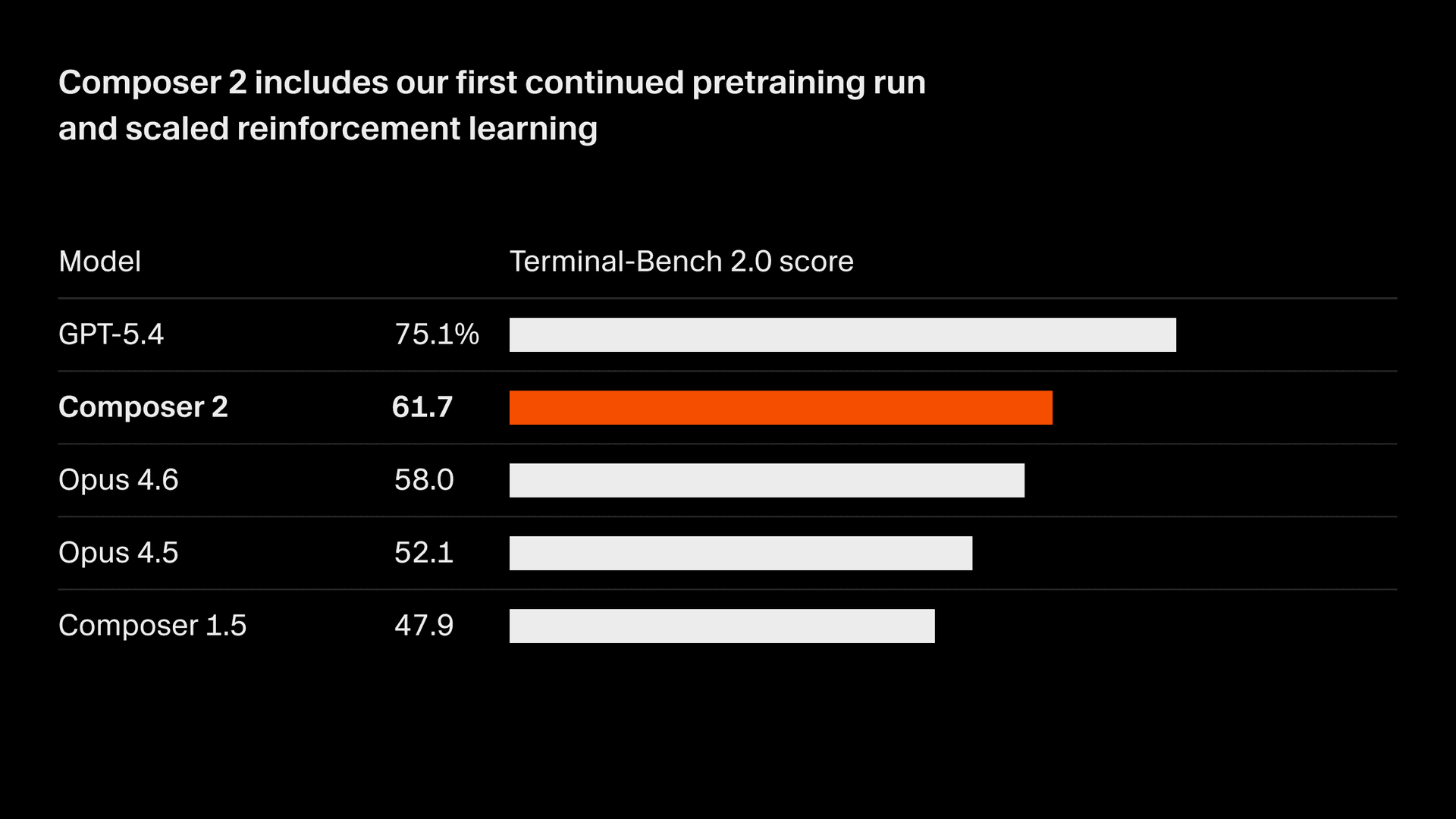
| Modelo | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Estas mejoras de calidad provienen de nuestra primera ejecución de preentrenamiento continuo, que proporciona una base mucho más sólida para escalar nuestro aprendizaje por refuerzo.
A partir de esta base, entrenamos en tareas de programación de largo plazo mediante aprendizaje por refuerzo. Composer 2 es capaz de resolver tareas complejas que requieren cientos de acciones.
Prueba Composer 2
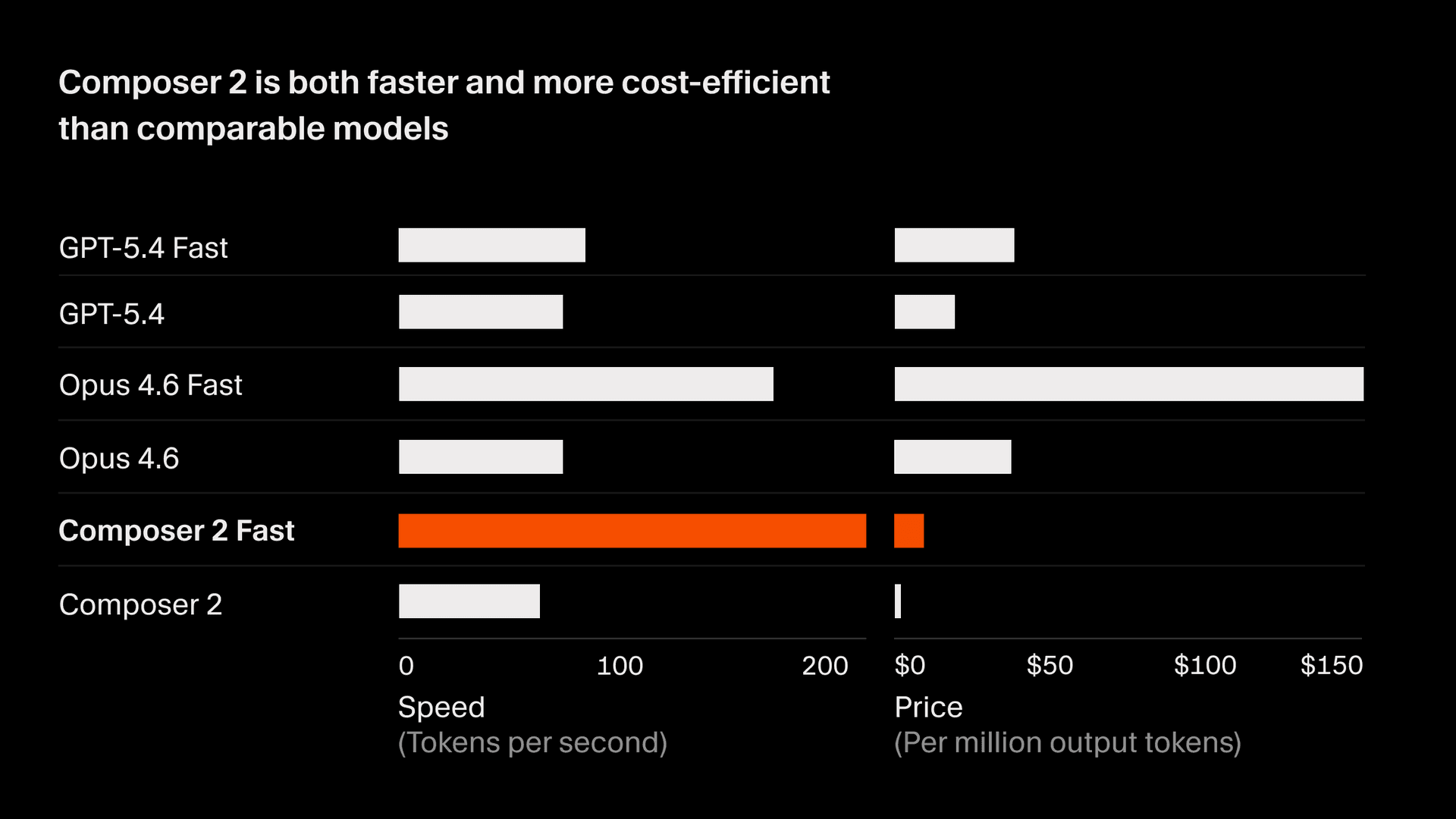
Composer 2 tiene un precio de 2.50/M por tokens de salida.
También hay una variante más rápida con la misma inteligencia a 7.50/M por tokens de salida, que tiene un costo menor que otros modelos rápidos2. Vamos a convertir la variante rápida en la opción predeterminada. Consulta la documentación actual del modelo Composer para todos los detalles.

En los planes individuales, el uso de Composer forma parte del grupo de modelos propios con una cantidad generosa incluida. Prueba Composer 2 hoy mismo en Cursor o en la versión alfa temprana de nuestra nueva interfaz.
- Terminal-Bench 2.0 es un benchmark de evaluación de agentes para uso en terminal mantenido por Laude Institute. Las puntuaciones de los modelos de Anthropic usan el harness Claude Code y las puntuaciones de los modelos de OpenAI usan el harness Simple Codex. Nuestra puntuación de Cursor se calculó usando el framework de evaluación Harbor oficial (el harness designado para Terminal-Bench 2.0) con la configuración predeterminada del benchmark. Ejecutamos 5 iteraciones por cada par modelo-agente y reportamos el promedio. Puedes encontrar más detalles sobre el benchmark en el sitio web oficial de Terminal Bench. Para otros modelos aparte de Composer 2, tomamos la puntuación máxima entre la puntuación de la clasificación oficial y la puntuación registrada al ejecutarlos en nuestra infraestructura. ↩
- Los tokens por segundo (TPS) de todos los modelos provienen de una instantánea del tráfico de Cursor del 18 de marzo de 2026. El tamaño de los tokens para Composer y los modelos GPT es similar. Los tokens de Anthropic son ~15% más pequeños y la cifra de TPS está normalizada para reflejarlo. De forma similar, el precio por token de salida de los modelos que no son de Anthropic se ajustó para reflejar el mismo cambio de ~15%. La velocidad puede variar según la capacidad del proveedor y las mejoras con el tiempo. ↩