推出 Composer 2
閱讀時間 2 分鐘
Composer 2 現已在 Cursor 中可使用。
它在程式設計方面達到前沿水準,價格為每百萬個輸入 token 2.50,使其成為智慧與成本之間全新且最佳的組合。我們也發布了一份關於我們如何訓練它的技術報告。


前沿水準的程式開發智慧
我們正在迅速提升模型品質。Composer 2 在我們衡量的所有基準測試上都有大幅提升,包括 Terminal-Bench 2.01 和 SWE-bench Multilingual:
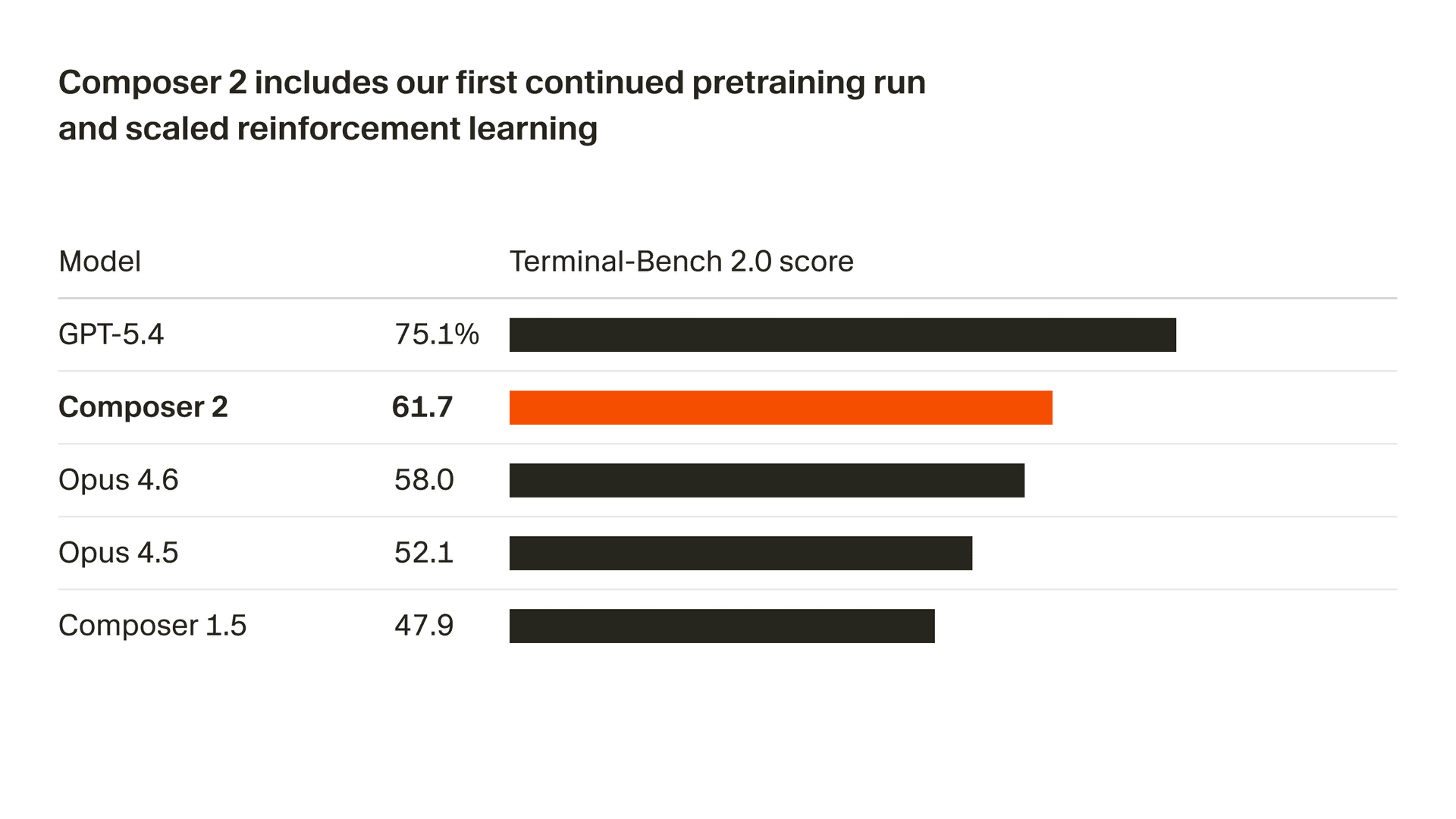
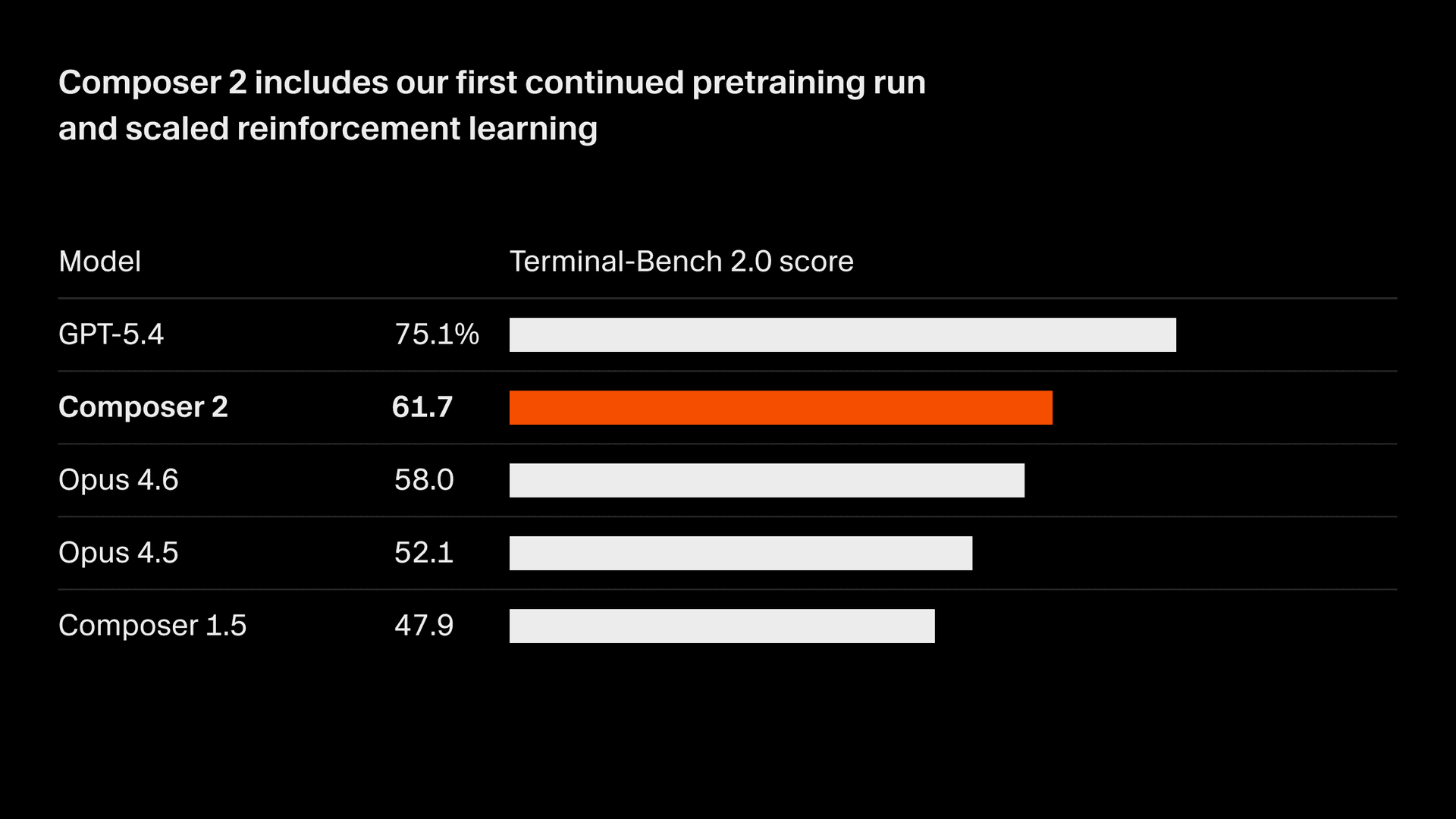
| 模型 | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
這些品質提升來自我們首次進行的持續預訓練流程,為擴展強化學習提供了更強大的基礎。
以此為基礎,我們透過強化學習訓練模型處理長時程程式開發任務。Composer 2 能夠解決需要數百個動作的具挑戰性任務。
試用 Composer 2
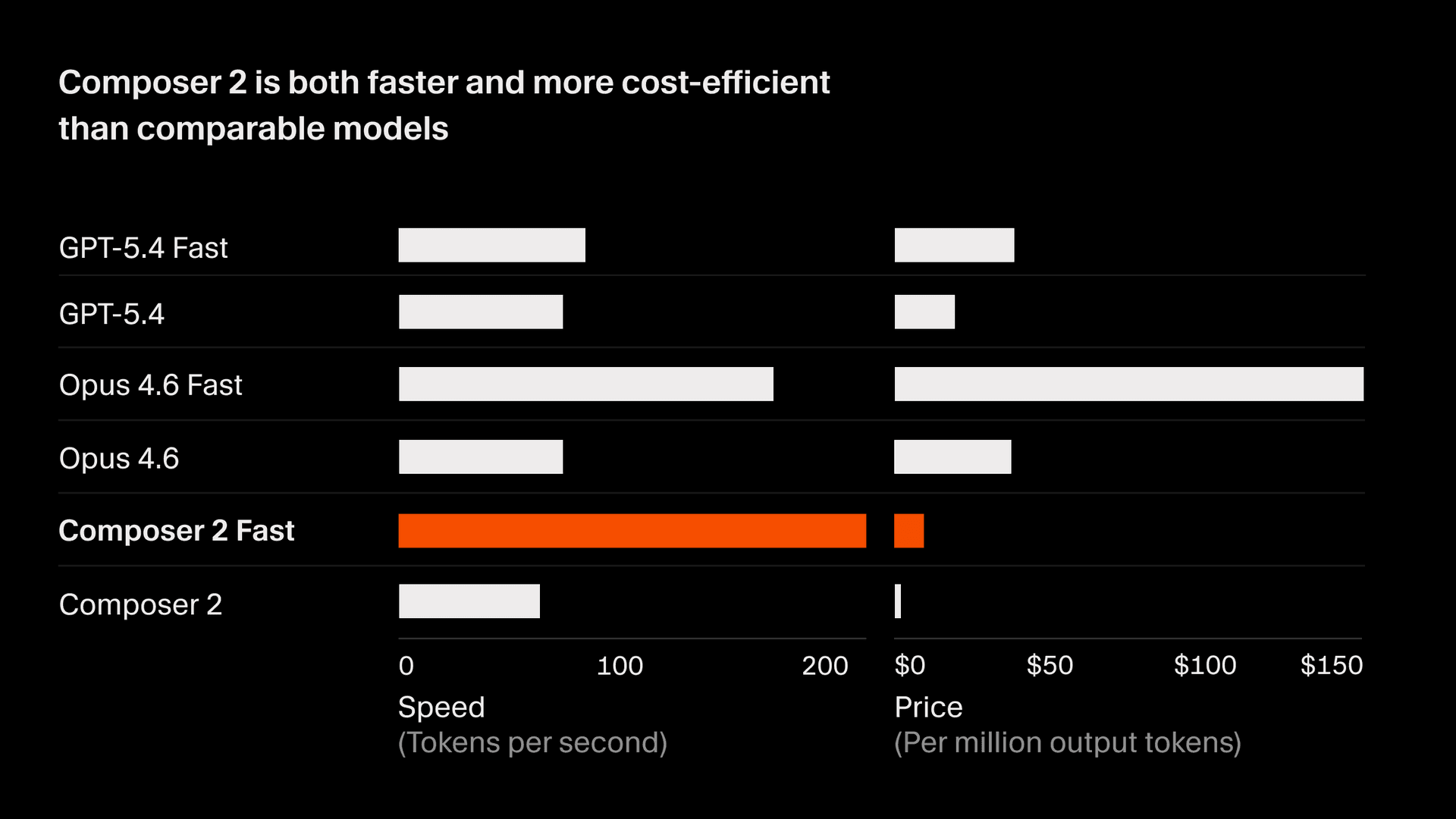
Composer 2 的定價為每百萬輸入 token 2.50。
另外還有一個 具備相同智慧、但速度更快的版本,定價為每百萬輸入 token 7.50,而且成本低於其他快速模型2。我們會將 fast 設為預設選項。完整資訊請參閱目前的 Composer 模型文件。

在個人方案中,Composer 用量屬於第一方模型池,並包含充足的使用額度。立即在 Cursor 或我們新介面的早期 alpha 版中試用 Composer 2。
- Terminal-Bench 2.0 是由 Laude Institute 維護、用於終端機使用情境的代理評估基準測試。Anthropic 模型分數使用 Claude Code harness,OpenAI 模型分數使用 Simple Codex harness。我們的 Cursor 分數是使用官方的 Harbor evaluation framework(Terminal-Bench 2.0 指定的 harness),並採用預設基準測試設定計算得出。我們針對每個模型-代理組合執行了 5 次迭代,並回報平均值。更多基準測試資訊可在官方的 Terminal Bench 網站 找到。對於 Composer 2 以外的其他模型,我們取 官方排行榜 分數與在我們基礎架構中執行時記錄的分數兩者中的較高值。↩
- 所有模型的每秒 token 數(TPS)皆來自 2026 年 3 月 18 日 Cursor 流量的快照。Composer 與 GPT 模型的 token 大小相近。Anthropic 的 token 約小 15%,TPS 數值已標準化以反映此差異。同樣地,非 Anthropic 模型的輸出 token 價格也已按比例調整,以符合這相同約 15% 的變化。速度可能會依供應商容量及隨時間推進的改進而有所變化。↩