Apresentando o Composer 2
O Composer 2 agora está disponível no Cursor.
Ele oferece desempenho de ponta em programação e custa 2.50/M tokens de saída, tornando-se uma nova combinação ideal de inteligência e custo. Também publicamos um relatório técnico sobre como ele foi treinado.


Inteligência de programação de ponta
Estamos melhorando rapidamente a qualidade do nosso modelo. O Composer 2 oferece grandes melhorias em todos os benchmarks que medimos, incluindo o Terminal-Bench 2.01 e o SWE-bench Multilingual:
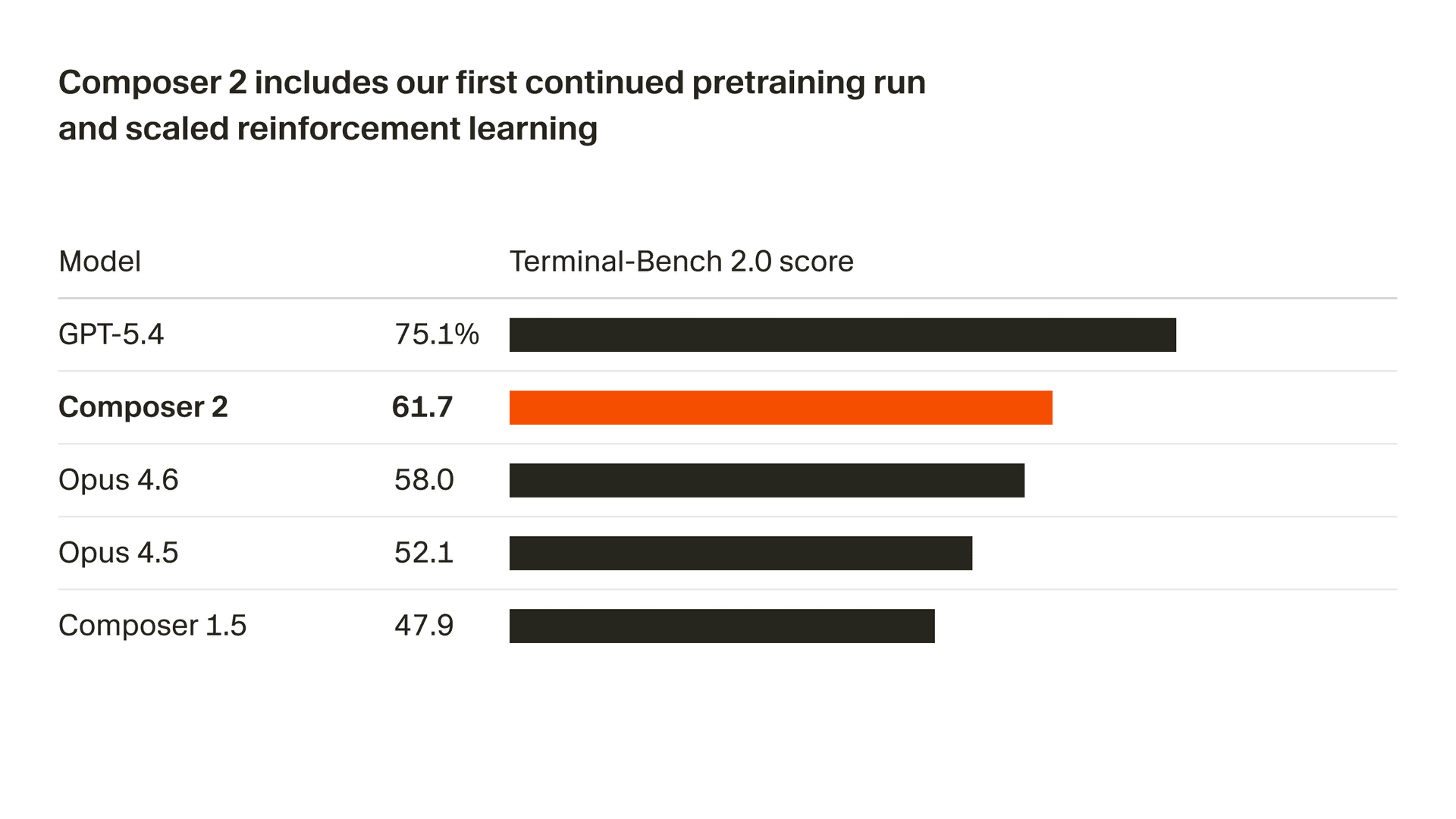
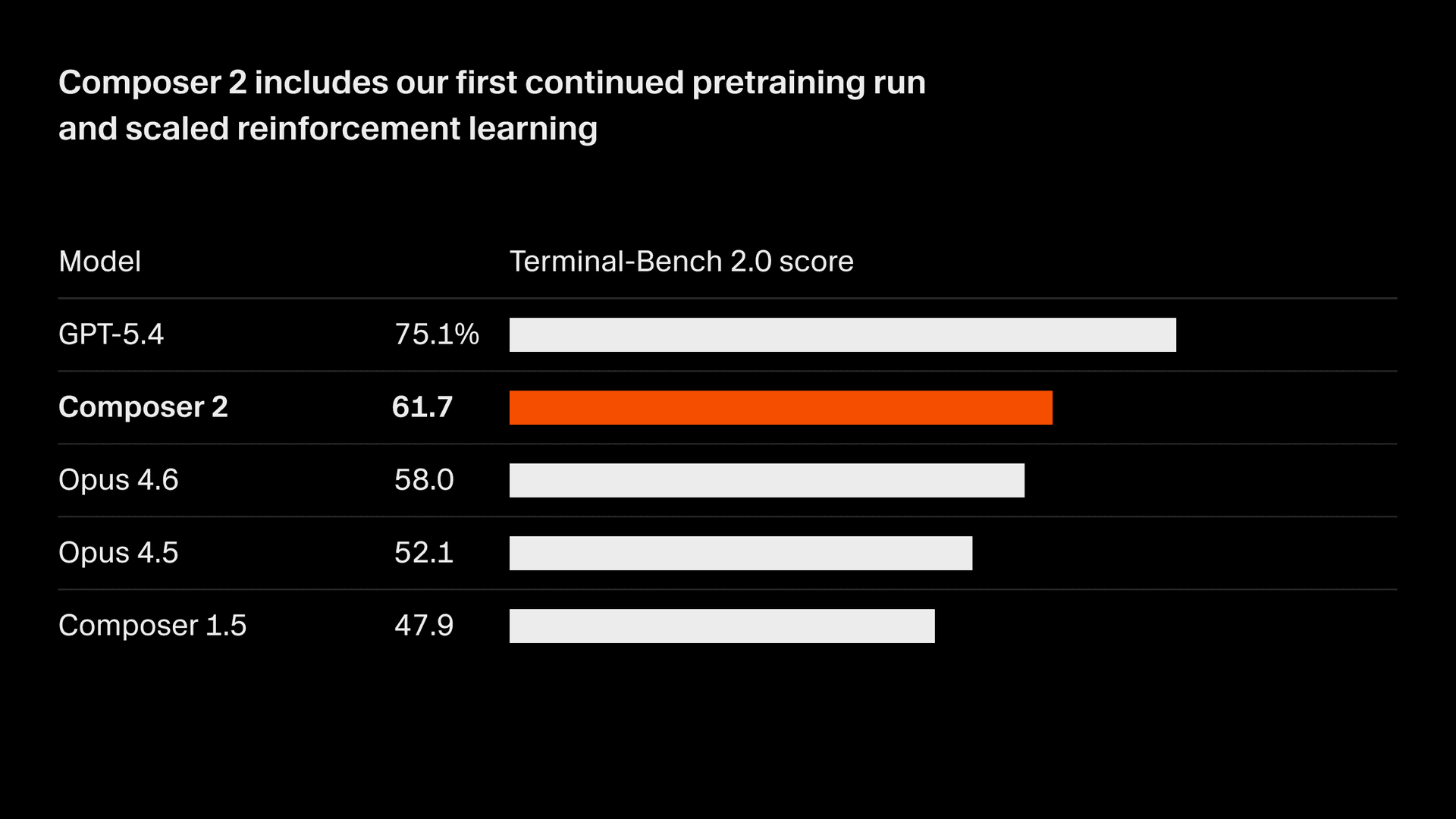
| Modelo | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Essas melhorias de qualidade vêm da nossa primeira execução de pré-treinamento contínuo, que fornece uma base muito mais forte para expandir nosso aprendizado por reforço.
A partir dessa base, treinamos em tarefas de programação de horizonte longo por meio de aprendizado por reforço. O Composer 2 é capaz de resolver tarefas desafiadoras que exigem centenas de ações.
Experimente o Composer 2
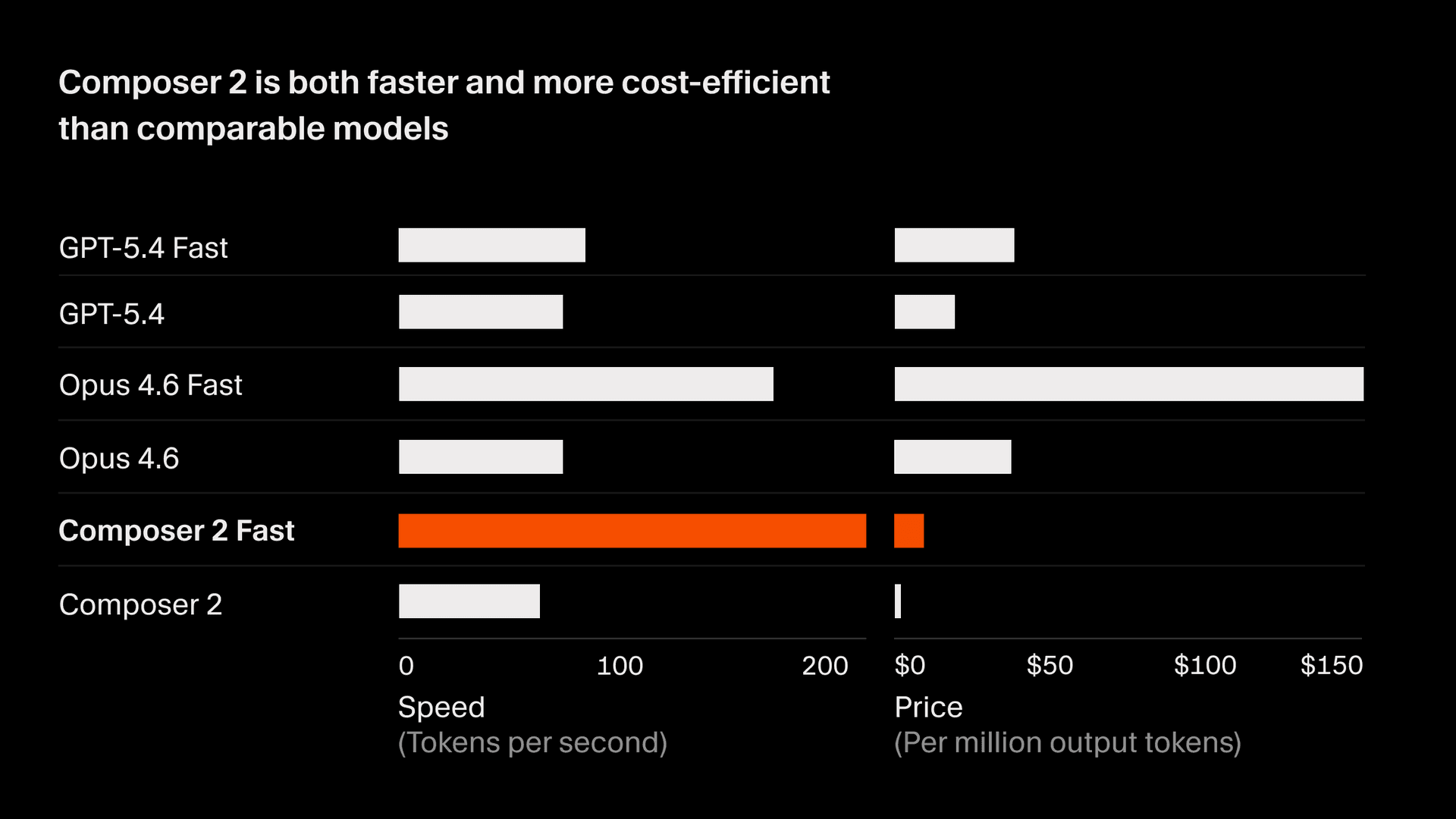
Composer 2 custa 2.50/M de tokens de saída.
Também há uma variante mais rápida com a mesma inteligência por 7.50/M de tokens de saída, que tem um custo menor do que outros modelos rápidos2. Estamos tornando a variante rápida a opção padrão. Veja a documentação atual do modelo Composer para todos os detalhes.

Nos planos individuais, o uso do Composer faz parte do pool de modelos próprios, com uma franquia generosa incluída. Experimente o Composer 2 hoje no Cursor ou na alpha inicial da nossa nova interface.
- O Terminal-Bench 2.0 é um benchmark de avaliação de agentes para uso em terminal, mantido pelo Laude Institute. As pontuações dos modelos da Anthropic usam o harness Claude Code, e as pontuações dos modelos da OpenAI usam o harness Simple Codex. Nossa pontuação do Cursor foi calculada usando o framework de avaliação Harbor oficial (o harness designado para o Terminal-Bench 2.0), com as configurações padrão do benchmark. Executamos 5 iterações por par modelo-agente e reportamos a média. Mais detalhes sobre o benchmark podem ser encontrados no site oficial do Terminal Bench. Para outros modelos além do Composer 2, consideramos a maior pontuação entre a do leaderboard oficial e a registrada em nossa infraestrutura. ↩
- Os tokens por segundo (TPS) de todos os modelos vêm de um snapshot do tráfego do Cursor em 18 de março de 2026. O tamanho dos tokens do Composer e dos modelos GPT é semelhante. Os tokens da Anthropic são cerca de 15% menores, e o número de TPS é normalizado para refletir isso. Da mesma forma, o preço do token de saída para modelos que não são da Anthropic foi ajustado para corresponder à mesma alteração de cerca de 15%. A velocidade pode variar dependendo da capacidade do provider e de melhorias ao longo do tempo. ↩