Un informe técnico sobre Composer 2

Publicamos en arXiv un informe técnico sobre el entrenamiento de Composer 2, nuestro modelo de programación para ingeniería de software con agentes. El informe cubre todo el proceso de entrenamiento, desde el preentrenamiento continuo sobre un modelo base abierto, Kimi K2.5, hasta el aprendizaje por refuerzo a gran escala, con especial atención a emular de cerca el entorno real de Cursor.
Preentrenamiento continuo y RL
Composer 2 se entrena en dos fases: un preentrenamiento continuo sobre una mezcla de datos con énfasis en código para profundizar los conocimientos de programación del modelo base, seguido de aprendizaje por refuerzo a gran escala para mejorar el rendimiento integral del agente. Observamos que reducir la pérdida de preentrenamiento mejora el rendimiento posterior en RL, y que una mejor base de conocimientos se traduce de forma consistente en un mejor agente.
El entrenamiento de RL de Composer 2 se lleva a cabo en sesiones realistas de Cursor, con las mismas herramientas y el mismo entorno de pruebas que usa el modelo desplegado, sobre una distribución de problemas que refleja todo el abanico de tareas que los desarrolladores le piden a Composer. Observamos que el entrenamiento de RL mejora tanto el rendimiento promedio como el mejor entre K intentos, lo que sugiere que el modelo está aprendiendo nuevas vías de solución en lugar de simplemente concentrarse en las ya conocidas.
Evaluación en condiciones reales con CursorBench
Uno de los principales desafíos al crear modelos para programar es que los benchmarks públicos a menudo no reflejan el trabajo que realmente hacen los desarrolladores. Las tareas están demasiado especificadas, las soluciones son acotadas y las bases de código son pequeñas.
Creamos CursorBench a partir de sesiones reales de programación de nuestro equipo de ingeniería. Incluye tareas en las que el prompt es breve y ambiguo, y las soluciones requieren cientos de líneas de cambios repartidos en muchos archivos. Usamos CursorBench durante el entrenamiento y la evaluación para mantener el modelo alineado con problemas reales.
Rendimiento
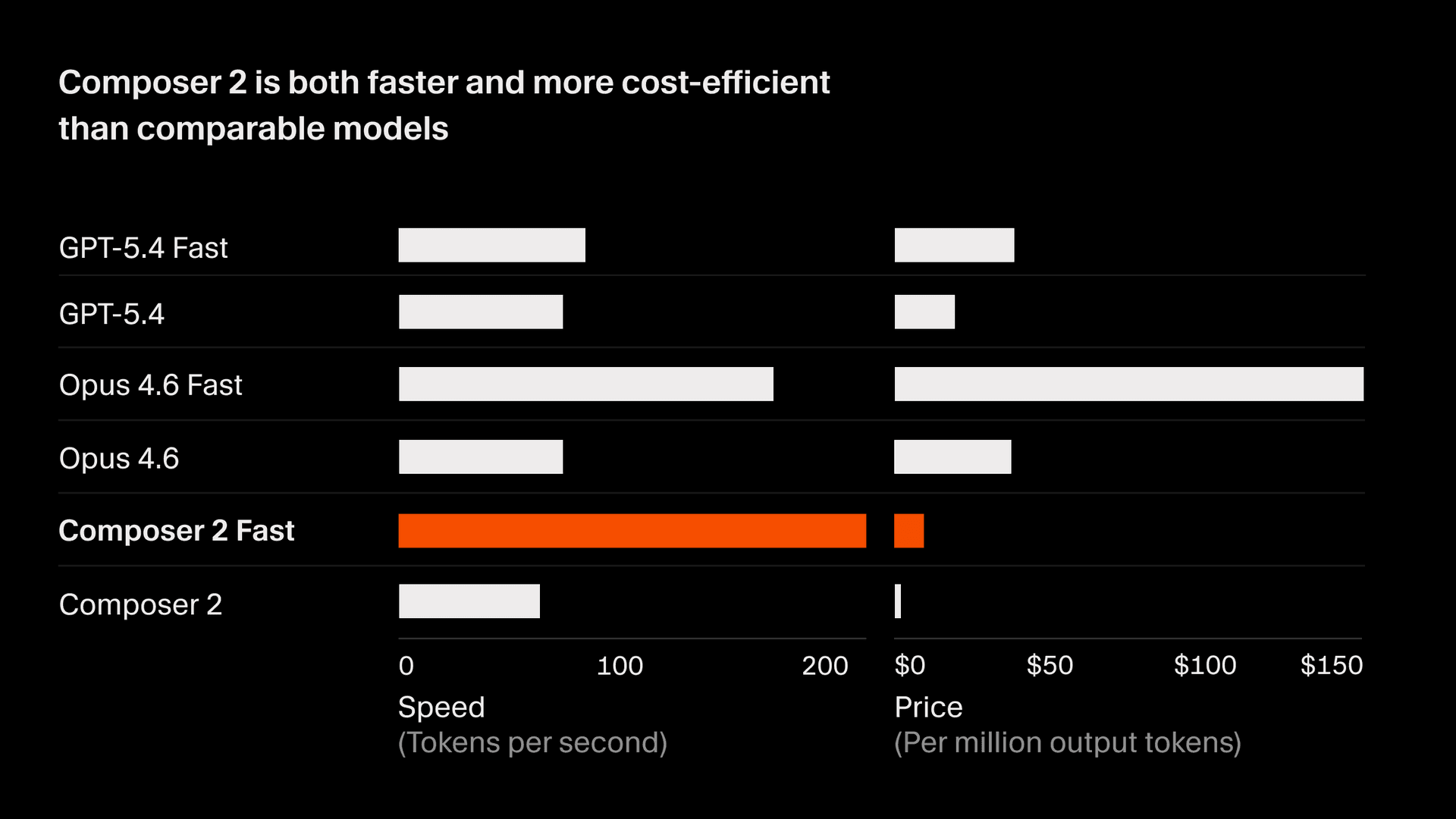
En CursorBench, Composer 2 obtiene una puntuación de 61.3, un 37% más que Composer 1.5, y compite con los modelos de vanguardia más potentes. En benchmarks públicos, Composer 2 obtiene 73.7 en SWE-bench Multilingual y 61.7 en Terminal-Bench. Lo consigue con un costo de inferencia significativamente menor que el de modelos comparables, lo que le da una relación óptima de Pareto entre precisión y costo para flujos de trabajo interactivos para desarrolladores.



Infraestructura
El entrenamiento de Composer 2 requirió un importante desarrollo de infraestructura, con kernels personalizados de baja precisión para entrenar MoE de forma eficiente en GPUs Blackwell, un pipeline de RL totalmente asíncrono que abarca varias regiones, y Anyrun, nuestra plataforma interna de cómputo para ejecutar cientos de miles de entornos de programación en sandbox. El informe cubre el stack completo, incluido nuestro enfoque para la sincronización de pesos, la tolerancia a fallos y la fidelidad del entorno.
El informe ofrece mucho más detalle sobre todo esto, incluidos estudios de ablación sobre la receta de entrenamiento, nuestro enfoque para moldear el comportamiento del agente y el diseño de nuestro conjunto de evaluación.
Gracias a los equipos detrás de Kimi K2.5, Ray, ThunderKittens, PyTorch y a la comunidad de código abierto en general. También queremos agradecer a Fireworks y Colfax por su colaboración y su alianza con nosotros.
Lee el informe técnico completo aquí.