推出 Composer 2
2 分钟阅读
Composer 2 现已在 Cursor 中上线。
它具备前沿级的编程能力,定价为每百万输入 token 2.50,使其成为兼顾智能与成本的全新最优组合。我们还发布了一份关于其训练方式的技术报告。


前沿级编程智能
我们正在快速提升模型质量。Composer 2 在我们衡量的所有基准测试上都取得了大幅提升,其中包括 Terminal-Bench 2.01 和 SWE-bench Multilingual:
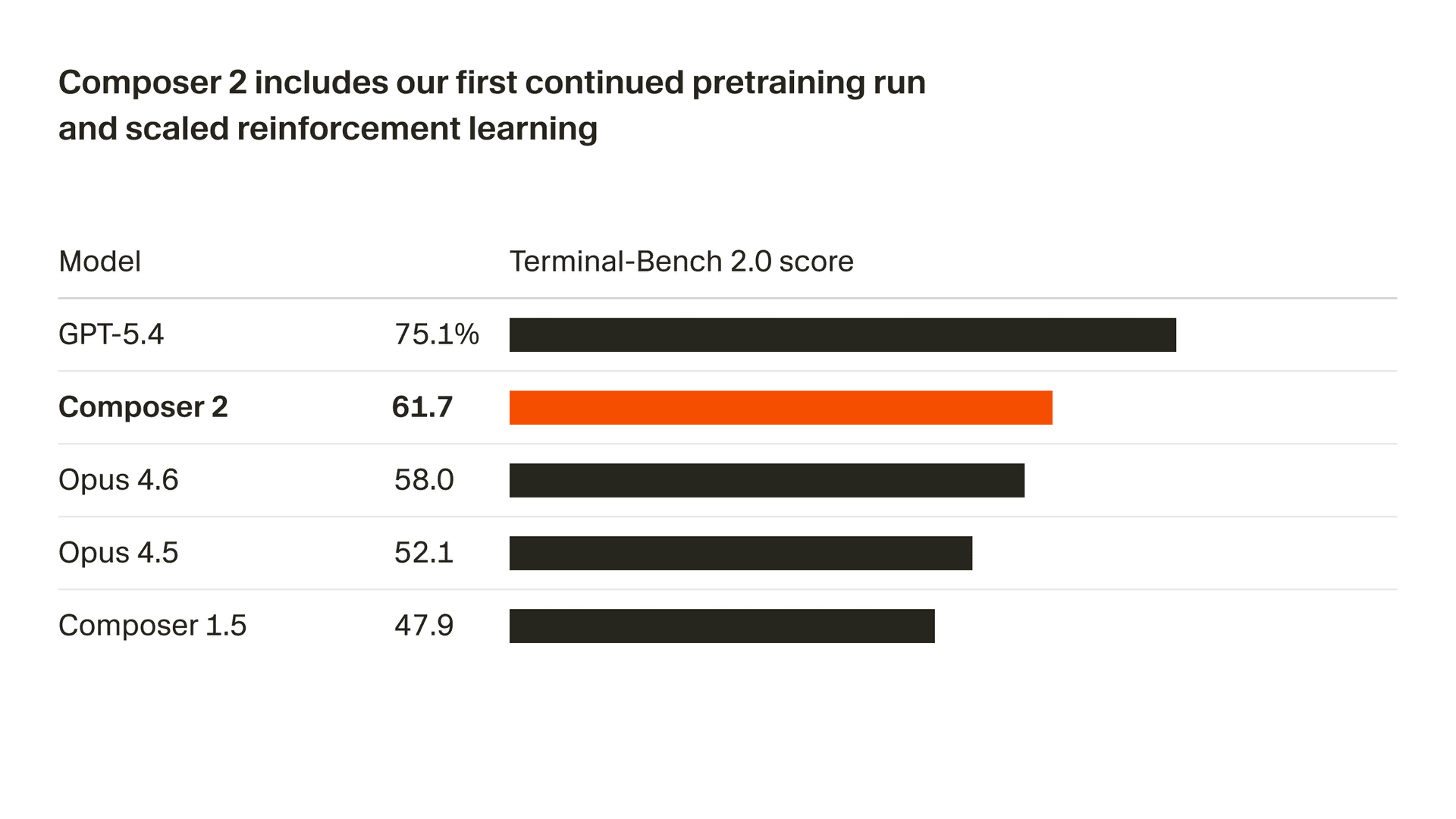
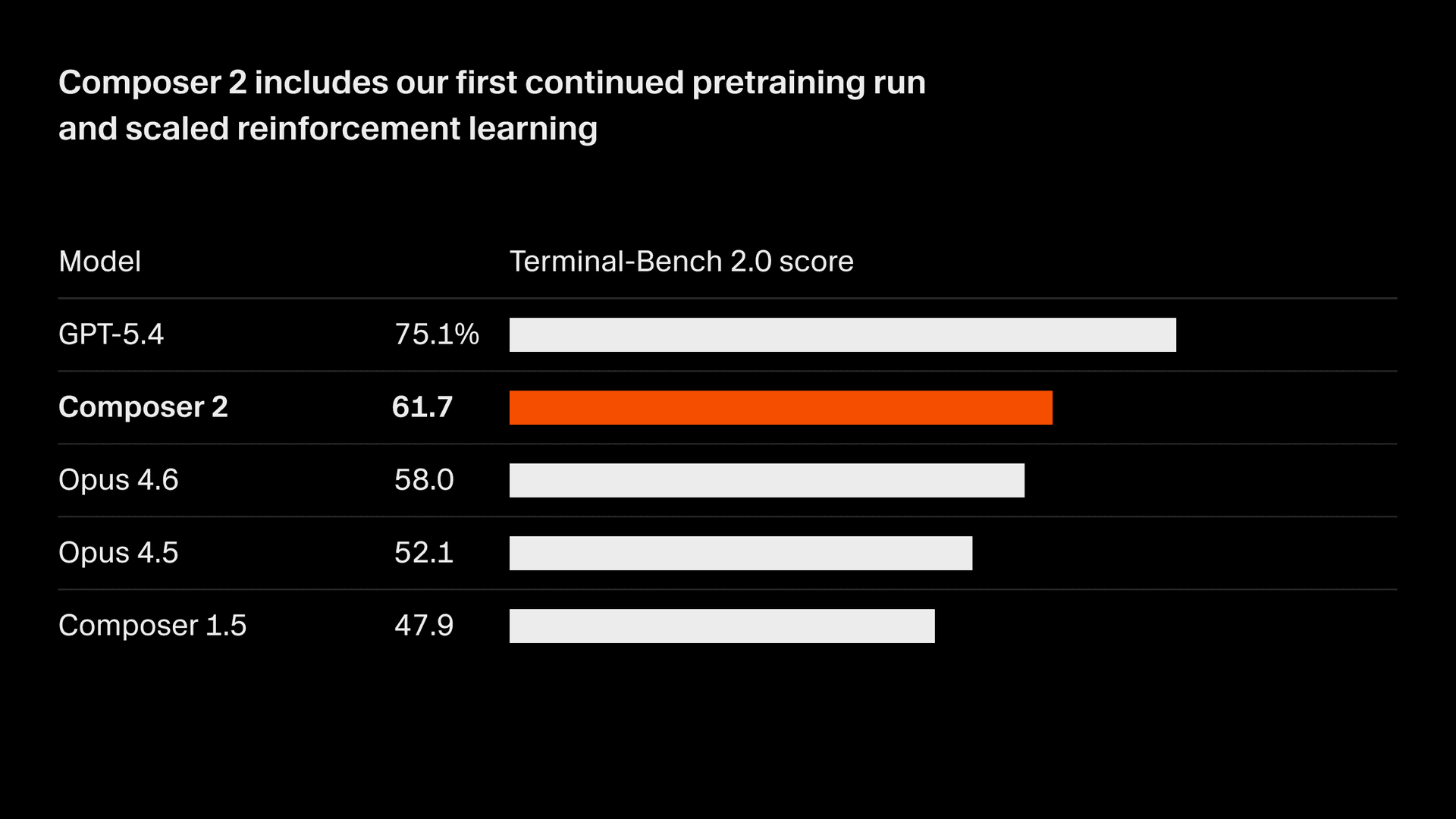
| 模型 | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
这些质量提升来自我们首次进行的持续预训练运行,为进一步扩展强化学习奠定了更强的基础。
我们通过强化学习训练 Composer 处理长周期编程任务的能力。Composer 2 能够解决需要数百个操作的高难度任务。
试用 Composer 2
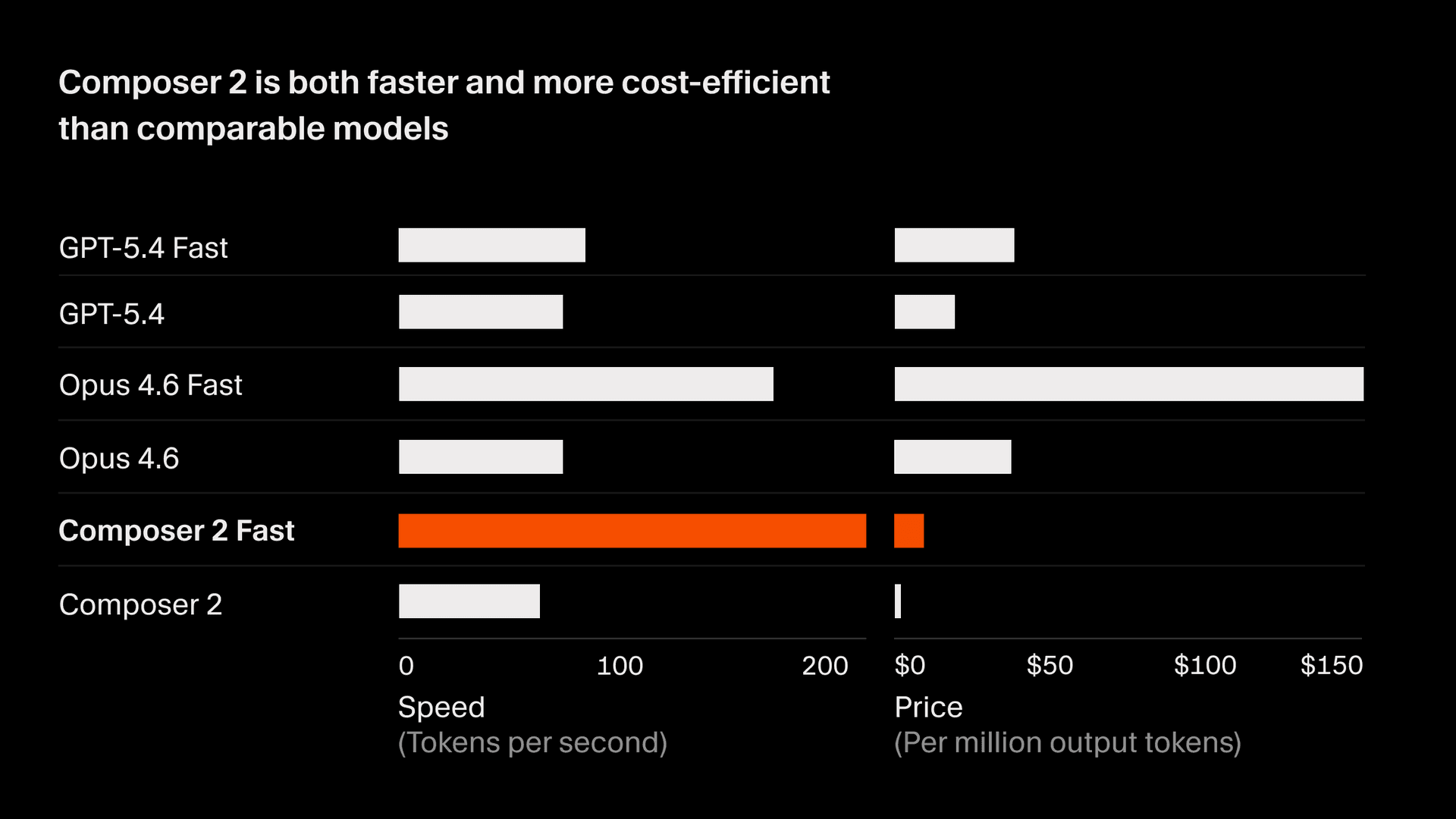
Composer 2 的定价为每百万输入 token 2.50。
此外,我们还提供了一个智能水平相同但速度更快的变体,定价为每百万输入 token 7.50,成本低于其他快速模型2。我们将把快速变体设为默认选项。完整详情请参见当前的 Composer 模型文档。

对于个人方案,Composer 用量属于第一方模型池,并包含充足的使用额度。你今天就可以在 Cursor 中试用 Composer 2,或在我们的新界面早期 alpha 版中体验。
- Terminal-Bench 2.0 是一项由 Laude Institute 维护的、面向终端使用场景的智能体评测基准测试。Anthropic 模型的分数使用 Claude Code harness,OpenAI 模型的分数使用 Simple Codex harness。我们的 Cursor 分数使用官方 Harbor evaluation framework(Terminal-Bench 2.0 的指定 harness)并在默认基准测试设置下计算得出。我们对每个模型-智能体组合运行了 5 次迭代,并报告平均值。有关该基准测试的更多详情,请参见官方 Terminal Bench 网站。对于 Composer 2 以外的其他模型,我们取 官方排行榜分数与在我们的基础设施中运行记录的分数两者中的较高值。↩
- 所有模型的每秒 token 数(TPS)均来自 2026 年 3 月 18 日的 Cursor 流量快照。Composer 和 GPT 模型的 token 大小相近。Anthropic 的 token 约小 15%,TPS 数值已做归一化处理以反映这一点。类似地,非 Anthropic 模型的输出 token 价格也按相同约 15% 的变化进行了缩放。速度可能会因 provider 容量以及随时间推移的改进而有所不同。↩