关于 Composer 2 的技术报告

我们在 arXiv 发布了一篇关于 Composer 2 训练的技术报告。Composer 2 是我们面向智能体驱动软件工程的代码模型。这份报告介绍了完整的训练流程:从基于开放基础模型 Kimi K2.5 的持续预训练,到大规模强化学习,重点是在训练中尽可能逼近真实的 Cursor 环境。
持续预训练与 RL
Composer 2 的训练分为两个阶段:首先是在强调代码的数据混合上进行持续预训练,以深化基础模型的编程知识;随后进行大规模强化学习,以提升端到端的智能体表现。我们发现,降低预训练损失会提升下游 RL 的效果;更扎实的基础知识也会可靠地转化为更强的智能体能力。
Composer 2 的 RL 训练在真实的 Cursor 会话中进行,使用与已部署模型相同的工具和执行框架,并基于能够反映开发者让 Composer 完成的各类任务全范围的问题分布。我们发现,RL 训练同时提升了平均表现和 best-of-K 表现,这表明模型学到的是新的解题路径,而不只是把已知路径进一步集中。
使用 CursorBench 进行真实场景评估
构建代码模型的一个核心挑战在于,公开基准往往无法反映开发者实际要做的工作。任务通常被描述得过于具体,解法空间有限,而且代码库规模较小。
我们基于工程团队的真实编码会话构建了 CursorBench。它包含这样的任务:提示简短且存在歧义,而完成解答往往需要在多个文件中进行数百行修改。我们在训练和评估的全过程中使用 CursorBench,让模型始终贴近真实问题。
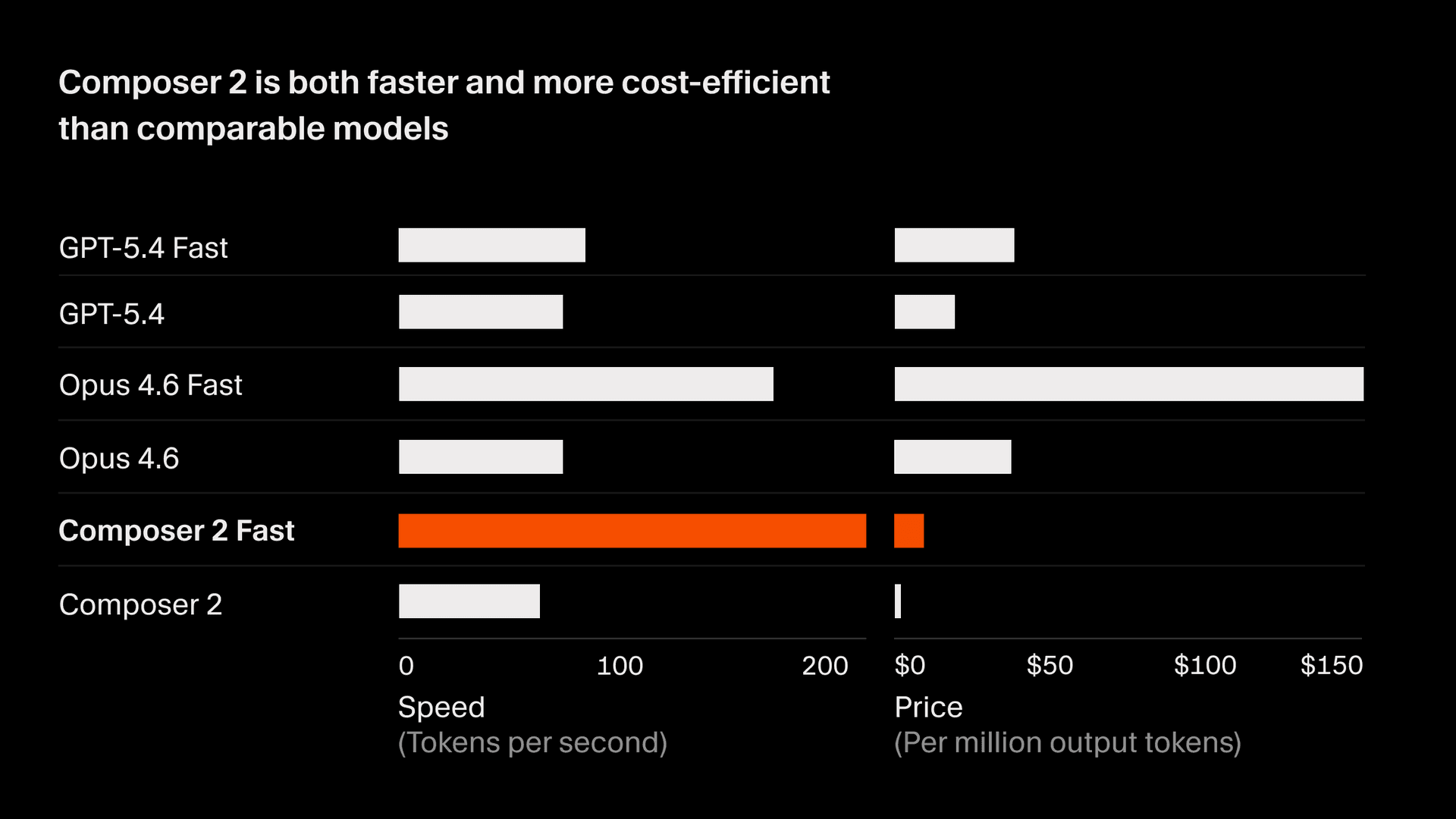
性能
在 CursorBench 上,Composer 2 得分 61.3,较 Composer 1.5 提升了 37%,可与最强的前沿模型媲美。在公开基准中,Composer 2 在 SWE-bench Multilingual 上得分 73.7,在 Terminal-Bench 上得分 61.7。与此同时,它的推理成本显著低于同类模型,因此在面向开发者的交互式工作流中,在准确性与成本之间实现了帕累托最优的平衡。



基础设施
为了训练 Composer 2,我们投入了大量基础设施开发工作,包括:为在 Blackwell GPU 上高效进行 MoE 训练而定制的低精度内核、跨多个区域的全异步 RL 流水线,以及 Anyrun——我们用于运行数十万个沙箱编程环境的内部计算平台。该报告覆盖了完整技术栈,包括我们在权重同步、容错和环境保真度方面的方案。
报告还对这些内容做了更深入的展开,包括训练方案的消融实验、我们塑造智能体行为的方法,以及评测套件的设计。
感谢 Kimi K2.5、Ray、ThunderKittens、PyTorch 及更广泛开源社区背后的团队。我们也感谢 Fireworks 和 Colfax 的协作与支持。
在这里读取完整技术报告。