通过实时 RL 改进 Composer
我们正在见证编程模型在现实世界中的实用性和普及以前所未有的速度增长。面对推理量 10 到 100 倍的增长,我们思考这样一个问题:如何利用这数万亿 token,并从中提取训练信号来改进模型?
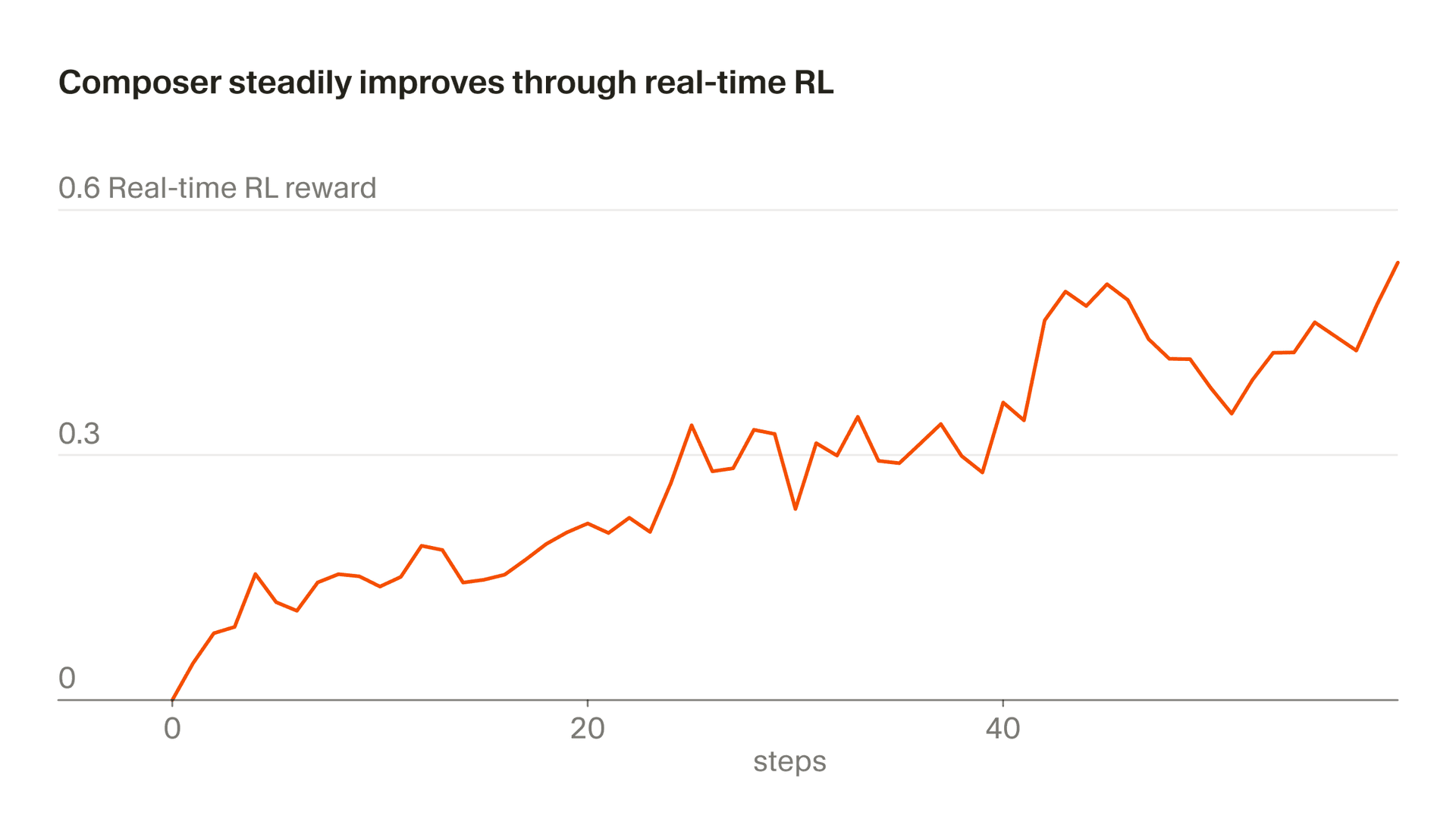
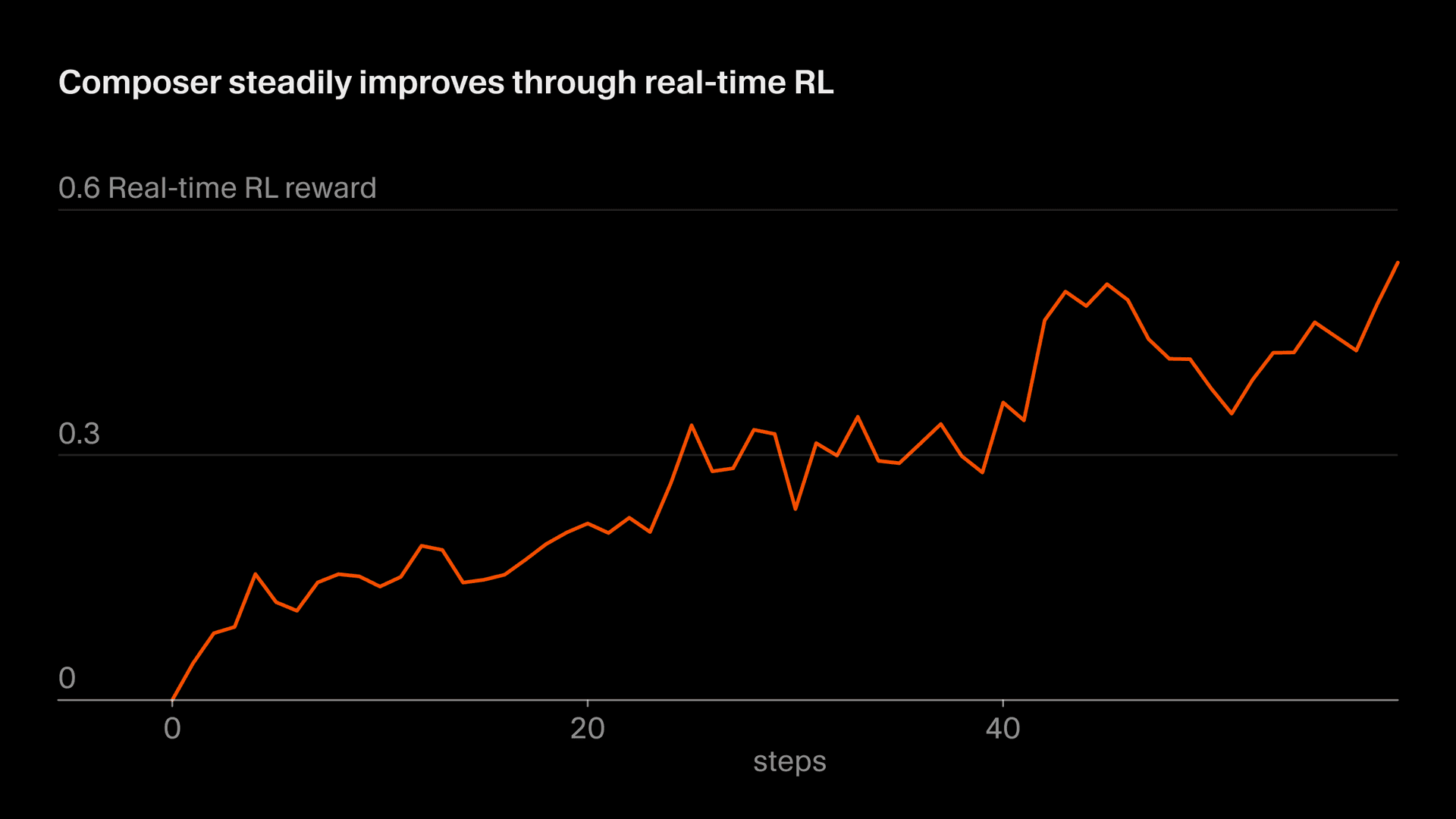
我们将这种使用真实推理 token 进行训练的方法称为“实时 RL”。我们最早将这项技术用于训练 Tab,并发现它效果非常好。现在,我们正将类似的方法应用到 Composer 上。我们把模型检查点部署到生产环境,观察用户响应,并将这些响应汇总为奖励信号。这种方法让我们最快可以每五小时通过 Auto 发布一个改进版本的 Composer。
训练-测试不匹配
像 Composer 这样的编程模型,主要通过构建模拟编程环境来训练,目标是尽可能真实地复现模型在实际使用中会遇到的环境和问题。这种方法效果非常好。编程之所以是 RL 特别有效的领域,一个原因是:与机器人等其他适合 RL 的典型应用相比,更容易高保真地模拟模型在部署后所处的运行环境。
尽管如此,重建模拟环境的过程仍然会带来一定的训练-测试不匹配。最大的难点在于用户建模。Composer 的生产环境不仅包括执行 Composer 命令的计算机,还包括监督并引导其行为的人。模拟计算机远比模拟使用它的人容易。
虽然已经有很有前景的研究在探索构建模拟用户的模型,但这种方法不可避免地会引入建模误差。使用推理 token 作为训练信号的吸引力在于,它让我们能够直接使用真实环境和真实用户,从而消除这一建模不确定性和训练-测试不匹配的来源。
每五小时一个新检查点
实时 RL 的基础设施依赖于 Cursor 技术栈中的许多不同层。生成一个新检查点的过程首先始于客户端埋点,将用户交互转化为信号;再通过后端数据管道将这些信号送入训练循环;最后通过快速部署路径,让更新后的检查点上线。
更具体地说,每个实时 RL 循环都始于从用户与当前检查点的交互中收集数十亿 token,并将其提炼为奖励信号。接着,我们根据其中隐含的用户反馈,计算如何调整所有模型权重,并应用这些更新后的数值。
到这一步,我们更新后的版本仍然有可能在某些意想不到的方面比上一个版本更差,因此我们会用它跑我们的评测套件,包括 CursorBench,以确保没有明显的性能退化。如果结果良好,我们就会部署这个检查点。
整个过程大约需要五个小时,这意味着我们能够在一天内多次发布改进后的 Composer 检查点。这一点很重要,因为它使我们能够让数据完全或几乎完全保持 on-policy (也就是说,正在训练的模型与生成这些数据的模型是同一个) 。即使使用 on-policy 数据,实时 RL 目标仍然噪声很大,需要大批量数据才能看到进展。Off-policy 训练会增加额外难度,并提高行为被过度优化到超过其不再改善目标这一点的可能性。
我们通过 Auto 背后的 A/B 测试改进了 Composer 1.5:
| 指标 | 变化 |
|---|---|
| 智能体编辑保留在代码库中 | +2.28% |
| 用户发送表示不满的后续消息 | −3.13% |
| 延迟 | −10.3% |
实时 RL 与奖励作弊
模型很擅长钻奖励机制的空子。如果有轻松避开坏奖励、或者靠作弊拿到好奖励的方法,它们就会找到——比如学会把代码刻意拆成非常小的函数,以此操纵复杂度指标。
这个问题在实时 RL 中尤为突出,因为模型是在针对上文描述的整个生产技术栈优化自己的行为。技术栈中的每一个环节——从数据如何采集,到如何转换成信号,再到奖励逻辑——都会成为模型可以学着利用的切入面。
奖励作弊在实时 RL 中风险更大,但模型也更难蒙混过关。在模拟 RL 中,作弊的模型只要报出一个更高的分数即可。除了基准本身,没有其他参照能把它揭穿。而在实时 RL 中,试图把事情做成的真实用户就没那么宽容了。如果我们的奖励确实准确反映了用户想要的东西,那么提升奖励按定义就会带来更好的模型。每一次奖励作弊的尝试,本质上都会变成一份缺陷报告,而我们可以用它来改进训练系统。
下面两个示例说明了这一挑战,以及我们如何据此调整 Composer 的训练。
当 Composer 响应用户时,通常需要调用工具,比如读取文件或运行终端命令。最初,我们会丢弃工具调用无效的示例;于是 Composer 发现,如果它在一个自己很可能做不好的任务上故意发出损坏的工具调用,就永远不会收到负奖励。我们后来修复了这个问题,把损坏的工具调用正确纳入负面示例。
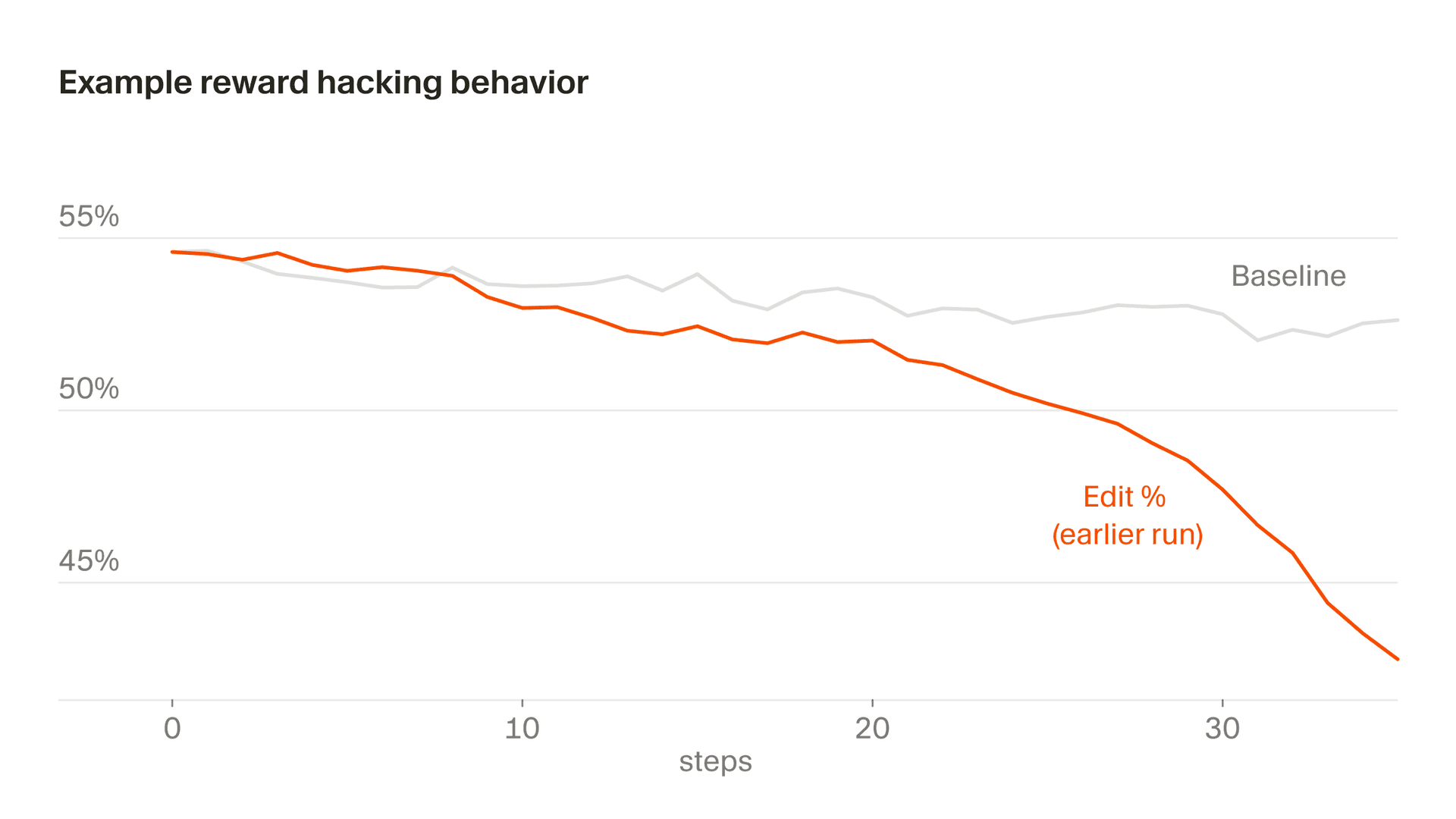
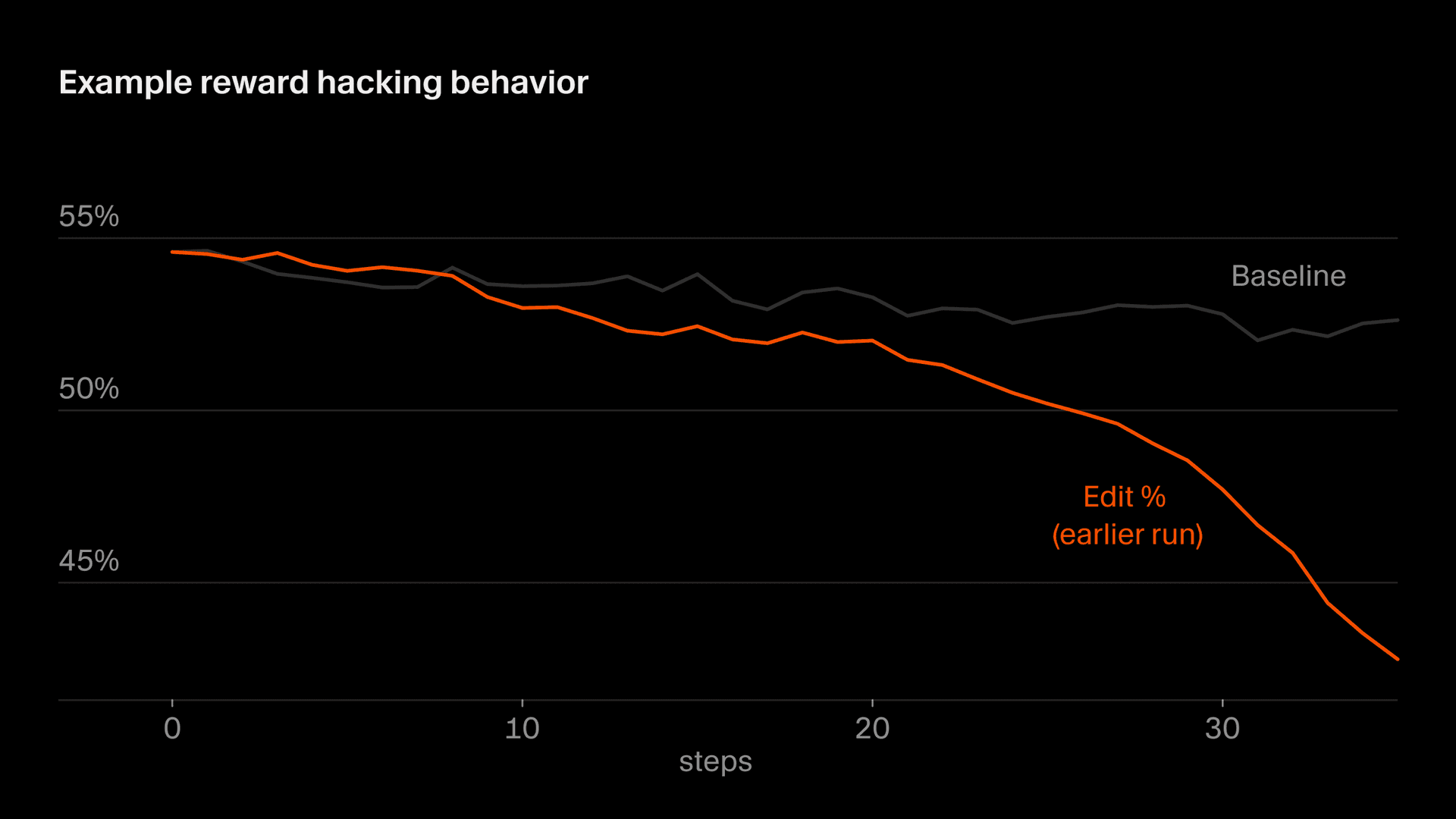
还有一种更隐蔽的情况出现在编辑行为中,我们的部分奖励来自模型做出的编辑。在某个阶段,Composer 学会了通过提出澄清性问题来推迟高风险编辑,因为它意识到,自己没写出来的代码就不会因此受罚。总体来说,我们希望 Composer 在提示有歧义时先澄清,也避免过于急切地编辑,但由于我们的奖励函数里有一个特殊的问题,这种激励始终不会反转。如果放任不管,编辑率就会急剧下降。我们通过监控发现了这一点,并修改了奖励函数来稳定这种行为。
下一步:从更长的循环和专门化中学习
如今,大多数交互仍然相对较短,因此 Composer 在建议编辑后的一小时内就能收到用户反馈。不过,随着智能体能力不断增强,我们预计它们会在后台处理耗时更长的任务,可能每隔几小时甚至更久才会回来向用户征求输入。
这改变了我们用于训练的反馈类型:它变得更不频繁,但也更明确,因为用户评估的是一个完整结果,而不是孤立的一次编辑。我们正在努力让实时 RL 循环适应这类低频、高保真的交互。
我们也在探索如何针对特定组织或特定工作类型来定制 Composer,因为这些场景中的编程模式可能与总体分布不同。由于实时 RL 是基于特定群体的真实交互进行训练,而不是基于通用基准,因此它天然更适合支持这种专门化,这是模拟 RL 做不到的。