Iterando com shadow workspaces
Aqui vai uma receita para o fracasso: copie e cole alguns arquivos relevantes em um Google Doc, envie o link para o seu engenheiro de software nível p60 favorito, que não sabe nada sobre a sua codebase, e peça para ele implementar totalmente e corretamente a sua próxima PR dentro do documento.
Peça para uma IA fazer o mesmo e ela também, previsivelmente, vai falhar.
Agora, em vez disso, dê a eles acesso remoto ao seu ambiente de desenvolvimento, com a capacidade de ver lints, ir para definições e executar código, e você pode, de fato, esperar que sejam um pouco úteis.
Acreditamos que uma das coisas que permitirá que IAs escrevam mais do seu código é a capacidade de iterar no seu ambiente de desenvolvimento. Mas deixar IAs soltas na sua pasta de forma ingênua resulta em caos: imagine escrever uma função que exige muito raciocínio apenas para uma IA sobrescrevê-la, ou tentar executar seu programa apenas para uma IA inserir código que não compila. Para realmente ser útil, a iteração da IA precisa acontecer em segundo plano, sem afetar a sua experiência de codificação.
Para conseguir isso, implementamos no Cursor o que chamamos de shadow workspace. Neste post do blog, primeiro vou apresentar nossos critérios de design e, em seguida, descrever a implementação que existe no Cursor no momento em que escrevo (uma janela Electron oculta) e para onde pretendemos levá-la no futuro (um proxy de pasta em nível de kernel).

Critérios de design
Queremos que o shadow workspace atinja os seguintes objetivos:
-
Usabilidade de LSP: as IAs devem conseguir ver os lints decorrentes de suas alterações, navegar até definições e, de forma geral, interagir com todas as partes do language server protocol (LSP).
-
Capacidade de execução: as IAs devem conseguir executar seu código e ver a saída.
Inicialmente, focamos na usabilidade de LSP.
Os objetivos devem ser alcançados sob os seguintes requisitos:
-
Independência: a experiência de programação do usuário não deve ser afetada.
-
Privacidade: o código do usuário deve estar seguro (por exemplo, mantendo tudo local).
-
Concorrência: várias IAs devem conseguir fazer seu trabalho simultaneamente.
-
Universalidade: deve funcionar para todas as linguagens e todas as configurações de workspace.
-
Manutenibilidade: a solução deve ser implementada com o mínimo de código possível e de forma bem isolada.
-
Velocidade: não deve haver atrasos de minutos em nenhum lugar, e deve haver capacidade (throughput) suficiente para centenas de branches de IAs.
Muitos desses pontos refletem a realidade de construir um editor de código para mais de cem mil usuários. Não queremos, de forma alguma, prejudicar a experiência de programação de ninguém.
Alcançando usabilidade com LSP
Permitir que IAs obtenham lints para suas edições é uma das maneiras mais impactantes de melhorar o desempenho de geração de código mantendo o modelo de linguagem subjacente fixo. Os lints não apenas permitem ir de 90% de código funcionando para 100% de código funcionando, como também são muito úteis em situações com contexto limitado, quando a IA pode precisar fazer uma suposição bem informada sobre qual método ou serviço chamar na primeira tentativa. Os lints podem ajudar a identificar pontos em que a IA precisa pedir mais informações.

A usabilidade com LSP também é mais simples do que a possibilidade de execução, porque quase todos os language servers conseguem operar em arquivos que não estão gravados no sistema de arquivos (e, como veremos depois, envolver o sistema de arquivos deixa as coisas bem mais difíceis). Então vamos começar por aqui! Em consonância com nosso quinto requisito, manutenibilidade, primeiro experimentamos as soluções mais simples possíveis.
As soluções simples que não funcionam
Como o Cursor é um fork do VS Code, já temos acesso muito fácil aos language servers. No VS Code, cada arquivo aberto é representado por um objeto TextModel, que armazena o estado atual do arquivo em memória. Os language servers leem esses objetos TextModel em vez de ler diretamente do disco, e é assim que conseguem fornecer completions e lints enquanto você digita (em vez de apenas quando você salva).
Suponha que uma IA faça uma edição no arquivo lib.ts. Obviamente, não podemos modificar o objeto TextModel existente correspondente a lib.ts, porque o usuário pode estar editando esse arquivo ao mesmo tempo. Ainda assim, uma ideia aparentemente plausível é criar uma cópia do objeto TextModel, desacoplar essa cópia de qualquer arquivo real em disco e deixar a IA editar e obter lints a partir desse objeto. Isso poderia ser feito com as 6 linhas de código a seguir.
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// cria o TextModel copiado em memória e aplica a edição da IA nele
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// aguarda 2 segundos para permitir que os servidores de linguagem processem o novo objeto TextModel
await new Promise((resolve) => setTimeout(resolve, 2000));
// lê os lints do serviço de marcadores, que internamente roteia para a extensão correta com base na linguagem
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}Esta solução é claramente excelente em termos de manutenibilidade. Ela também é ótima em termos de caráter universal, porque a maioria das pessoas já terá instalado e configurado as extensões específicas de linguagem corretas para o seu projeto. Concorrência e privacidade são atendidas de forma trivial.
O problema é a independência. Embora criar uma cópia de TextModel signifique que não estamos modificando diretamente o arquivo que o usuário está editando, ainda assim informamos ao language server — o mesmo language server que o usuário está usando — sobre a existência do nosso arquivo copiado. Isso causa problemas: os resultados de go-to-references vão incluir o nosso arquivo copiado, linguagens como Go, que têm um escopo de namespace padrão envolvendo vários arquivos, vão reclamar de declarações duplicadas para todas as funções tanto no arquivo copiado quanto no arquivo original que o usuário pode estar editando, e linguagens como Rust, em que arquivos só são incluídos se forem explicitamente importados em algum outro lugar, não vão mostrar erro nenhum. Provavelmente existem muitos outros problemas desse tipo.
Talvez pareça que esses problemas sejam menores, mas a independência é absolutamente crítica para nós. Se degradarmos nem que seja um pouco a experiência normal de edição de código, não vai importar quão bons sejam nossos recursos de IA — as pessoas, inclusive eu, simplesmente não usariam o Cursor.
Também consideramos algumas outras ideias que acabaram não dando certo: iniciar nossas próprias instâncias de tsc, gopls ou rust-analyzer fora da infraestrutura do VS Code, duplicar o processo de host de extensões onde todas as extensões do VS Code são executadas para que possamos rodar duas cópias de cada extensão de language server, e fazer fork de todos os language servers populares para suportar múltiplas versões diferentes de arquivos e então empacotar essas extensões dentro do Cursor.
A implementação atual de shadow workspace
Acabamos implementando o shadow workspace como uma janela oculta: sempre que uma IA quiser ver os lints do código que ela escreveu, criamos uma janela oculta para o workspace atual e então fazemos a edição nessa janela, reportando de volta os lints. Reutilizamos a janela oculta entre as requisições. Isso nos dá (quase*) usabilidade LSP completa, ao mesmo tempo que satisfaz todos os requisitos (quase*) completamente. Os asteriscos são abordados depois.
Um diagrama de arquitetura simplificado é mostrado na Figura 4.
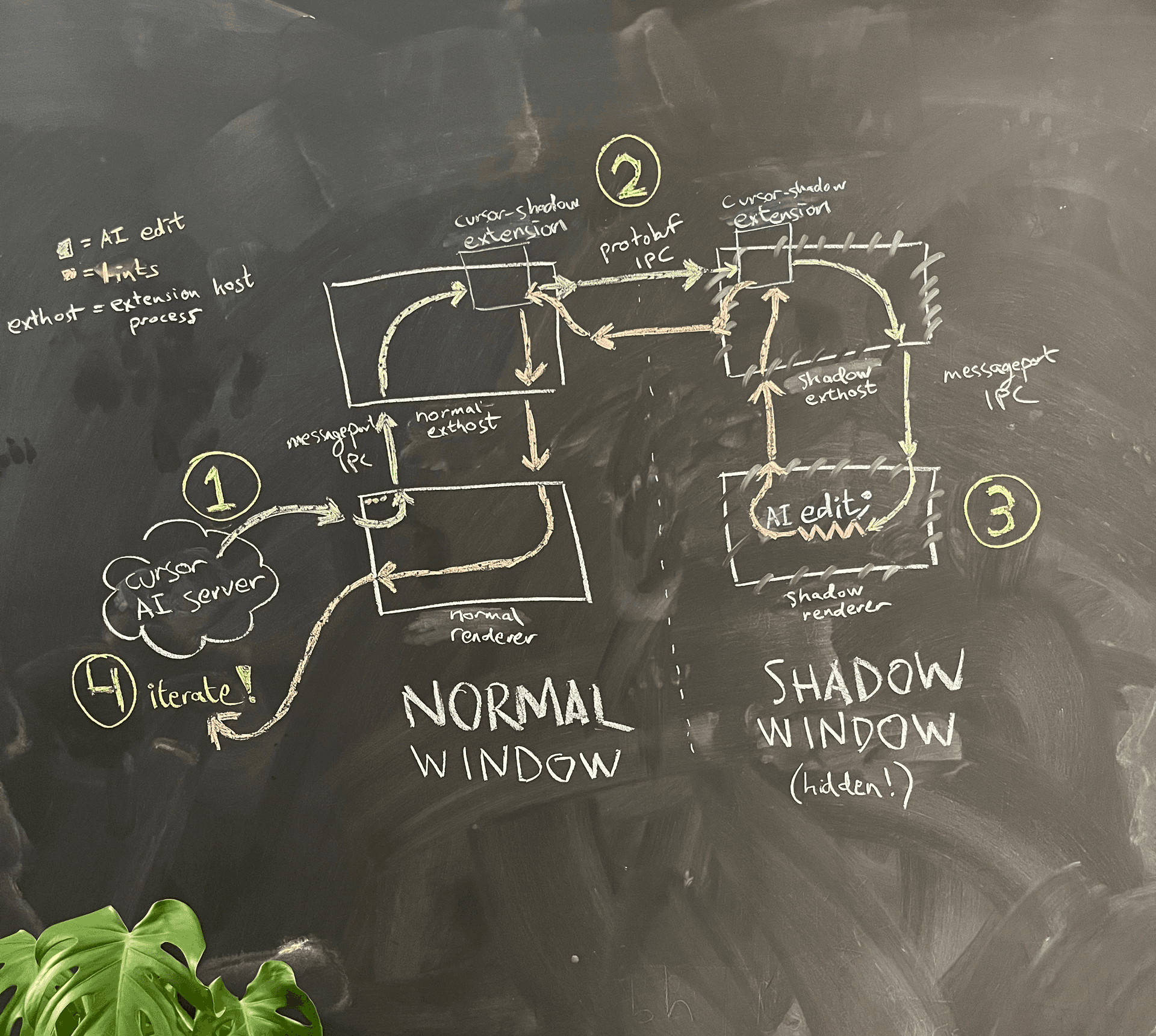
A IA está rodando no processo de renderização da janela normal. Quando quer ver os lints do código que escreveu, o processo de renderização pede ao processo principal para criar uma janela sombra oculta na mesma pasta.
Por causa do sandboxing do Electron, os dois processos de renderização não podem se comunicar diretamente. Uma opção que consideramos foi reutilizar a lógica cuidadosa de criação de portas de mensagem que o VS Code implementou para permitir que o processo de renderização se comunique com o processo do extension host, e usá-la para criar nossa própria IPC por porta de mensagem entre a janela normal e a janela sombra. Cientes do peso de manutenção, optamos por um hack: reutilizamos a IPC existente por porta de mensagem do processo de renderização para o extension host e então nos comunicamos de extension host para extension host usando uma conexão IPC independente. Ali, também incluímos discretamente uma melhoria de qualidade de vida: agora poderíamos usar gRPC e buf (que adoramos) para nos comunicar, em vez da lógica de serialização JSON personalizada e um tanto frágil do VS Code.
Essa configuração é, por construção, bastante fácil de manter, já que o código adicionado é independente de outros trechos de código, e o código central necessário para ocultar a janela é apenas uma linha (ao abrir uma janela no Electron, você pode fornecer o parâmetro show: false para escondê-la). Ela satisfaz trivialmente universalidade e privacidade.
Felizmente, independência também é satisfeita! A nova janela é completamente independente do usuário, então as IAs podem livremente fazer quaisquer alterações que desejarem e obter os lints correspondentes. O usuário não notará nada.
Há uma preocupação com a janela sombra: a nova janela, ingênuamente, traz um aumento de 2x no uso de memória. Reduzimos o impacto disso limitando as extensões que podem rodar na janela sombra, encerrando-a automaticamente após 15 minutos de inatividade e garantindo que seja opt-in. Ainda assim, isso representa um desafio para concorrência: não podemos simplesmente criar uma nova janela sombra para cada IA. Felizmente, aqui podemos aproveitar um dos principais fatores que diferenciam IAs de humanos: IAs podem ser pausadas por um tempo indefinido sem sequer perceber. Em particular, se você tiver duas IAs, A e B, propondo edições A1 seguida de A2 e B1 seguida de B2, respectivamente, você pode intercalar essas edições. A janela sombra primeiro reseta o estado inteiro da pasta para A1, obtém os lints e os retorna para A. Depois, reseta o estado inteiro da pasta para B1, obtém os lints e os retorna para B. E assim por diante com A2 e B2. Nesse sentido, IAs são mais parecidas com processos de computador (que também são intercalados assim pela CPU sem perceber) do que com humanos (que têm um senso intrínseco de tempo).
Com tudo isso junto, obtemos uma API Protobuf simples que nossas IAs em segundo plano podem usar para refinar suas edições, sem afetar em nada o usuário.
Os asteriscos prometidos: alguns language servers dependem de que o código seja gravado em disco antes de reportar lints. O principal exemplo é o language server rust-analyzer, que simplesmente executa um cargo check em nível de projeto para obter os lints e não se integra ao sistema de arquivos virtual do VS Code (veja esta issue para referência). Assim, o shadow workspace ainda não oferece suporte a LSP para Rust, a menos que o usuário esteja usando a extensão descontinuada RLS.
Alcançando a capacidade de execução
A capacidade de execução é onde as coisas ficam interessantes e complicadas ao mesmo tempo. No momento, estamos focando em IAs que operam em janelas de tempo curtas para o Cursor — por exemplo, implementar funções para você em segundo plano enquanto você as usa, em vez de implementar PRs inteiras — então ainda não implementamos a capacidade de execução. Ainda assim, é interessante pensar em como alcançá-la.
Executar código exige salvá-lo no sistema de arquivos. Muitos projetos também terão efeitos colaterais em disco (pense em caches de build e arquivos de log). Portanto, não podemos mais abrir a shadow window na mesma pasta que o usuário. Para uma capacidade de execução perfeita em todos os projetos, também precisamos de isolamento em nível de rede, mas, por enquanto, vamos focar em obter isolamento de disco.
A ideia mais simples: cp -r
A ideia mais simples é copiar recursivamente a pasta do usuário para um diretório em /tmp, aplicar as edições da IA, salvar os arquivos e executar o código lá. Para a próxima edição por uma IA diferente, faríamos um rm -rf seguido de uma nova chamada a cp -r, para garantir que o workspace sombra permaneça sincronizado com o workspace do usuário.
O problema é a velocidade: cp -r é muito lento. O ponto importante é que, para conseguir executar um projeto, não precisamos apenas copiar o código-fonte, mas também todos os arquivos auxiliares ligados ao build. Concretamente, precisamos copiar o node_modules em projetos JavaScript, o venv em projetos Python e o target em projetos Rust. Essas geralmente são pastas enormes, mesmo para projetos de porte médio, o que decreta o fim da abordagem ingênua com cp -r.
Symlinks, hardlinks, copy-on-writes
Copiar e criar estruturas de pastas grandes não precisa ser super lento! Uma prova disso é o bun, que muitas vezes leva menos de um segundo para instalar dependências em cache em node_modules. No Linux, o bun usa hardlinks, o que é rápido porque não há movimentação real de dados. No macOS, ele usa a syscall clonefile, que é uma adição relativamente recente e realiza um copy-on-write de um arquivo ou pasta.
Infelizmente, para o nosso monorepo de tamanho moderado, até mesmo um clonefile com cp -c leva 45 segundos para terminar. Isso é lento demais para ser executado antes de cada requisição de shadow workspace. Hardlinks são assustadores porque qualquer coisa que você executa na pasta sombra pode acidentalmente modificar os arquivos reais no repositório original. Symlinks são semelhantes nesse sentido e também têm o problema adicional de não serem tratados de forma transparente, o que significa que geralmente exigem configurações extras (por exemplo, a flag --preserve-symlinks do Node.js).
Dá para imaginar que um clonefile (ou mesmo um simples cp -r) funcionaria se fosse combinado com algum esquema de controle inteligente para evitar ter que recopiar a pasta antes de cada requisição. Para garantir a correção, precisaríamos monitorar todas as alterações de arquivos na pasta do usuário desde a última cópia completa e todas as alterações de arquivos na pasta copiada e, antes de cada requisição, desfazer as últimas e reproduzir as primeiras. Sempre que o histórico de mudanças de qualquer um dos lados ficasse grande demais para acompanhar, poderíamos fazer uma nova cópia completa e redefinir o estado. Isso poderia funcionar, mas parece propenso a erros, frágil e, francamente, um pouco feio para alcançar algo que soa tão simples.
O que realmente queremos: um proxy de pasta em nível de kernel
O que realmente queremos é simples: queremos que uma pasta sombra A′ pareça idêntica à pasta A do usuário para todos os aplicativos que usam as APIs de sistema de arquivos padrão, com a capacidade de configurar rapidamente um pequeno conjunto de arquivos de substituição, cujo conteúdo é lido da memória. Também queremos que qualquer gravação na pasta A′ seja feita no armazenamento em memória de substituições, em vez de no disco. Em resumo, queremos uma pasta proxy com substituições configuráveis e estamos satisfeitos em manter a tabela de substituições inteiramente em memória. Assim, podemos abrir nossa janela sombra dentro dessa pasta proxy e obter independência perfeita em nível de disco.
Crucialmente, precisamos de suporte em nível de kernel para o proxy de pasta, de modo que qualquer código em execução possa continuar chamando as syscalls read e write sem qualquer alteração. Uma abordagem é criar uma extensão de kernel 13 que se registre como backend para a pasta sombra no sistema de arquivos virtual do kernel e implemente o comportamento simples descrito acima.
No Linux, podemos fazer isso em espaço de usuário, usando o FUSE (“Filesystem in Userspace”). FUSE é um módulo de kernel que já existe na maioria das distribuições Linux por padrão e repassa as chamadas de sistema de arquivos para um processo em espaço de usuário. Isso torna a implementação do proxy de pasta ainda mais simples. Uma implementação simples do proxy de pasta poderia ser como a seguinte, aqui apresentada em C++.
Primeiro, importamos a biblioteca FUSE em espaço de usuário, que é responsável por se comunicar com o módulo de kernel FUSE. Também definimos a pasta de destino (a pasta do usuário) e o mapa em memória das substituições.
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// outras inclusões...
using namespace std;
// a pasta com proxy que não queremos modificar
string target_folder = "/path/to/target/folder";
// as substituições em memória a serem aplicadas
unordered_map<string, vector<char>> overrides;Em seguida, definimos nossa função personalizada read para verificar se os overrides incluem o caminho e, caso contrário, ler apenas da pasta de destino.
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// verifica se o caminho está nos overrides
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// se sim, retorna o conteúdo do override
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// caso contrário, abre e lê o arquivo da pasta com proxy
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}Nossa função write personalizada grava apenas no mapa de substituições.
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// sempre escreve nos overrides
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}Por fim, registramos nossas funções personalizadas no FUSE.
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}Uma implementação real precisaria implementar toda a API do FUSE, incluindo readdir, getattr e lock, mas as funções seriam muito semelhantes às acima. Para cada nova requisição de lints, podemos simplesmente redefinir o mapa de overrides para conter apenas as edições daquela IA específica, o que é instantâneo. Se quisermos nos proteger contra uma explosão de memória, também poderíamos manter o mapa de overrides em disco (com algum trabalho extra de controle).
Com controle perfeito sobre o ambiente, provavelmente iríamos querer implementar isso como um módulo nativo de kernel, para evitar o overhead das trocas extras de contexto usuário‑kernel do FUSE. 14
...Mas: jardins murados
No Linux, o proxy de pasta FUSE funciona muito bem, mas a maioria dos nossos usuários usa macOS ou Windows, nenhum dos quais tem uma implementação FUSE nativa. Infelizmente, distribuir uma extensão de kernel também está fora de questão: em Macs com Apple Silicon, a única maneira de um usuário instalar uma extensão de kernel é reiniciar o computador segurando uma tecla especial para entrar no modo de recuperação e então reduzir o nível de segurança para “Segurança reduzida”. Impraticável!
Como o FUSE precisa rodar parcialmente dentro do kernel, implementações FUSE de terceiros como macFUSE sofrem do mesmo problema impossível de convencer os usuários a instalar.
Já houve tentativas de ser criativo em torno dessa restrição. Uma abordagem é pegar um sistema de arquivos baseado em rede que o macOS suporta nativamente (por exemplo, NFS ou SMB) e colocar uma API FUSE por baixo dele. Há um servidor local de código aberto, prova de conceito, com uma API semelhante à FUSE construída sobre NFS, hospedado em xetdata/nfsserve, e o projeto de código fechado macOS-FUSE-t oferece suporte a backends construídos tanto em NFS quanto em SMB.
Problema resolvido? Na verdade, não... Sistemas de arquivos são mais complicados do que apenas ler, escrever e listar arquivos! Aqui, o Cargo reclama porque versões anteriores do NFS, sobre as quais a implementação xetdata/nfsserve é construída, não oferecem suporte a bloqueio de arquivos.

MacOS-FUSE-t é construído sobre NFSv4, que oferece suporte a bloqueio de arquivos, mas o repositório do GitHub não contém nada além de três arquivos que não são código-fonte (Attributions.txt, License.txt, README.md) e foi criado por uma conta do GitHub com o suspeito nome de usuário de propósito único macos-fuse-t, sem mais informações. Obviamente, não podemos distribuir binários aleatórios para nossos usuários... As issues em aberto também indicam alguns problemas mais fundamentais com a abordagem baseada em NFS/SMB, em geral relacionados a bugs de kernel da Apple.
O que nos resta? Ou uma nova abordagem criativa, 15 ou... política! A jornada de uma década da Apple para eliminar extensões de kernel levou a empresa a abrir cada vez mais APIs em nível de usuário (como DriverKit), e o suporte nativo para sistemas de arquivos antigos foi recentemente migrado para modo usuário. O código open source de MS-DOS da Apple referencia um framework privado chamado FSKit aqui, o que parece muito promissor! Parece possível que, com um pouco de política, consigamos que eles finalizem e lancem o FSKit para desenvolvedores externos (ou talvez eles já estejam planejando isso?), caso em que talvez tenhamos uma solução para o problema de execução também no macOS.
Perguntas em aberto
Como vimos, o problema aparentemente simples de deixar IAs iterarem sobre código em segundo plano é, na verdade, bastante complexo. O shadow workspace foi um projeto de 1 semana, de 1 pessoa, para criar uma implementação que resolvesse a necessidade imediata que tínhamos de mostrar lints para a IA. No futuro, planejamos estendê-lo para também resolver o problema da capacidade de execução. Algumas perguntas em aberto:
-
Existe outra maneira de implementar a pasta proxy simples que estamos imaginando sem criar uma extensão de kernel ou usar a API do FUSE? O FUSE tenta resolver um problema maior (qualquer tipo de sistema de arquivos), então parece plausível que possam existir algumas APIs obscuras no macOS e no Windows que funcionariam para a nossa pasta proxy, mas não funcionariam para uma implementação geral de FUSE.
-
Exatamente como é a história da pasta proxy no Windows? Algo como o WinFsp simplesmente funcionaria, ou existem problemas de instalação, desempenho ou segurança com isso? Passei a maior parte do meu tempo investigando como fazer a pasta proxy no macOS.
-
Talvez exista uma maneira de usar o DriverKit no macOS e simular um dispositivo USB falso para atuar como a pasta proxy? Duvido, mas não examinei a API de perto o suficiente para dizer com confiança que isso é impossível.
-
Como podemos alcançar independência em nível de rede? Uma situação específica a considerar é quando a IA quer depurar um teste de integração em que o código está dividido entre três microsserviços. É possível que queiramos fazer algo mais parecido com uma VM, embora isso exija mais trabalho para garantir equivalência de toda a configuração de ambiente e de todo o software instalado.
-
Existe uma maneira de criar um workspace remoto idêntico a partir do workspace local do usuário com o mínimo possível de configuração exigida do usuário? Na nuvem, poderíamos usar FUSE pronto para uso (ou até mesmo um módulo de kernel, se desejado por razões de desempenho) sem precisar lidar com burocracia, e também poderíamos garantir nenhum uso extra de memória para o usuário e independência completa. Para usuários que se importam menos com privacidade, isso poderia ser uma boa alternativa. Uma proto-ideia é algum tipo de container Docker inferido automaticamente observando o sistema (talvez usando uma combinação de scripts para detectar o que está rodando na máquina e usando modelos de linguagem para escrever um Dockerfile).
Se você tiver boas ideias para qualquer uma dessas perguntas, envie um e-mail para arvid@cursor.com. Além disso, se quiser trabalhar em coisas como esta, estamos contratando.