Descoberta dinâmica de contexto
Agentes de código estão mudando rapidamente a forma como o software é desenvolvido. Seu avanço acelerado vem tanto de modelos de agente mais avançados quanto de uma engenharia de contexto mais eficaz para orientá-los.
O agent harness do Cursor, ou seja, as instruções e ferramentas que fornecemos ao modelo, é otimizado individualmente para cada novo modelo de ponta que suportamos. No entanto, há melhorias de engenharia de contexto que podemos fazer, como na forma de reunir contexto e otimizar o uso de tokens ao longo de uma interação longa, que se aplicam a todos os modelos dentro do nosso harness.
À medida que os modelos se tornaram melhores como agentes, temos obtido sucesso fornecendo menos detalhes de início, facilitando para o agente buscar o contexto relevante por conta própria. Estamos chamando esse padrão de descoberta dinâmica de contexto, em contraste com o contexto estático, que é sempre incluído.
Arquivos para descoberta dinâmica de contexto
A descoberta dinâmica de contexto é muito mais eficiente em termos de tokens, pois somente os dados necessários são trazidos para a janela de contexto. Ela também pode melhorar a qualidade da resposta do agente ao reduzir a quantidade de informações potencialmente confusas ou contraditórias na janela de contexto.
Veja como usamos a descoberta dinâmica de contexto no Cursor:
- Transformar respostas longas de ferramentas em arquivos
- Referenciar o histórico do chat durante a criação de resumos
- Dar suporte ao padrão aberto Agent Skills
- Carregar com eficiência apenas as ferramentas MCP necessárias
- Tratar todas as sessões de terminal integradas como arquivos
1. Transformando respostas longas de ferramentas em arquivos
Chamadas de ferramentas podem aumentar drasticamente a janela de contexto ao retornar uma grande resposta JSON.
Para ferramentas próprias do Cursor, como edição de arquivos e pesquisa na base de código, podemos evitar inflar demais o contexto com definições de ferramentas inteligentes e formatos de resposta mínimos, mas ferramentas de terceiros (isto é, comandos de shell ou chamadas MCP) não recebem esse mesmo tratamento de forma nativa.
A abordagem comum de agentes de código é truncar comandos de shell longos ou resultados de MCP. Isso pode levar à perda de dados, que pode incluir informações importantes que você queria no contexto. No Cursor, em vez disso, escrevemos a saída em um arquivo e permitimos que o agente a leia. O agente chama tail para verificar o final do arquivo e, em seguida, ler mais se precisar.
Isso reduziu o número de sumarizações desnecessárias ao atingir os limites de contexto.
2. Usando o histórico de chat como referência durante a sumarização
Quando a janela de contexto do modelo fica cheia, o Cursor aciona uma etapa de sumarização para dar ao agente uma nova janela de contexto com um resumo do trabalho feito até o momento.
Mas o conhecimento do agente pode se degradar após a sumarização, já que ela é uma compressão com perdas do contexto. O agente pode ter esquecido detalhes cruciais sobre a tarefa. No Cursor, tratamos o histórico de chat como arquivos para melhorar a qualidade da sumarização.


Depois que o limite da janela de contexto é atingido, ou quando o usuário decide resumir manualmente, fornecemos ao agente uma referência ao arquivo de histórico. Se o agente perceber que precisa de mais detalhes que estão faltando no resumo, ele pode pesquisar no histórico para recuperá-los.
3. Suporte ao padrão aberto Agent Skills
Cursor oferece suporte a Agent Skills, um padrão aberto para estender agentes de código com capacidades especializadas. Assim como outros tipos de Rules, as Skills são definidas por arquivos que informam ao agente como executar uma tarefa específica de um determinado domínio.
As Skills também incluem um nome e uma descrição que podem ser incluídos como "contexto estático" no prompt de sistema. O agente pode então fazer descoberta dinâmica de contexto para selecionar as Skills relevantes, usando ferramentas como grep e a busca semântica do Cursor.
As Skills também podem agrupar executáveis ou scripts relevantes para a tarefa. Como são apenas arquivos, o agente pode facilmente encontrar o que é relevante para uma Skill específica.
4. Carregar com eficiência apenas as ferramentas MCP necessárias
MCP é útil para acessar recursos protegidos por OAuth. Isso pode incluir logs de produção, arquivos de design externos ou contexto e documentação internos de uma empresa.
Alguns servidores MCP incluem muitas ferramentas, muitas vezes com descrições longas, o que pode aumentar significativamente o tamanho da janela de contexto. A maioria dessas ferramentas não é usada, mesmo estando sempre incluída no prompt. Isso se agrava se você usar vários servidores MCP.
Não é viável esperar que todo servidor MCP otimize isso. Acreditamos que é responsabilidade dos agentes de codificação reduzir o uso de contexto. No Cursor, oferecemos suporte à descoberta dinâmica de contexto para MCP sincronizando descrições de ferramentas com uma pasta.1
O agente agora recebe apenas um pequeno trecho de contexto estático, incluindo os nomes das ferramentas, o que o leva a consultar as ferramentas sempre que a tarefa exigir. Em um teste A/B, descobrimos que, em execuções que chamaram uma ferramenta MCP, essa estratégia reduziu o total de tokens do agente em 46,9% (estatisticamente significativo, com alta variância baseada no número de MCPs instalados).
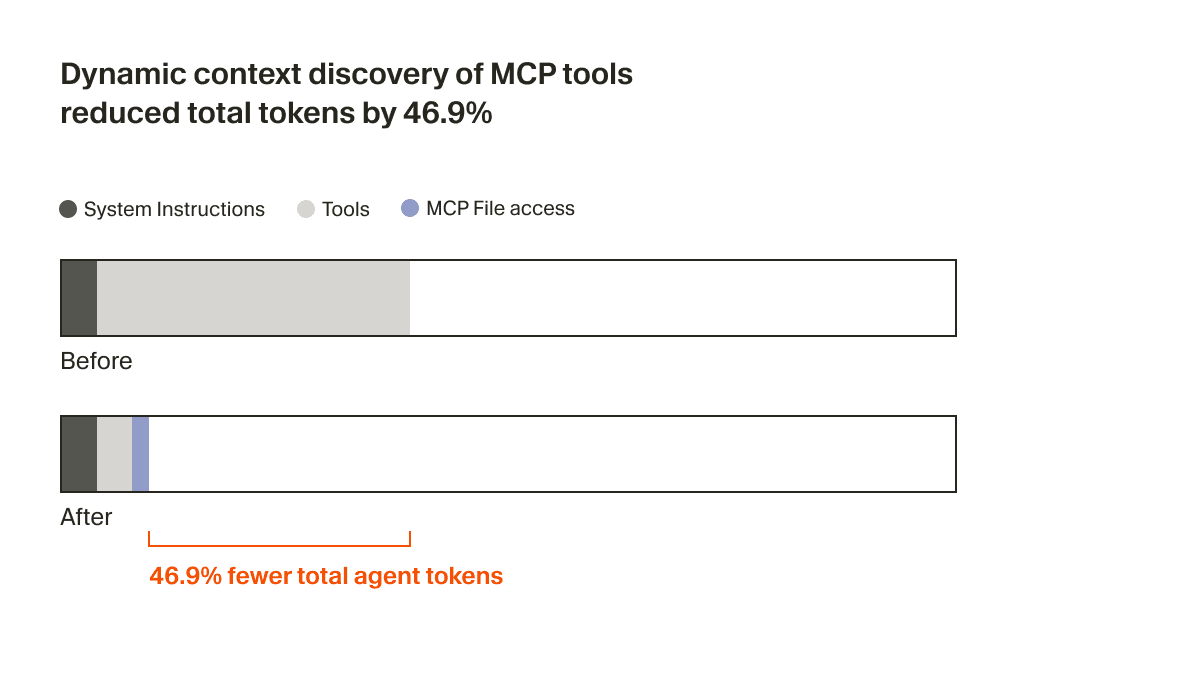
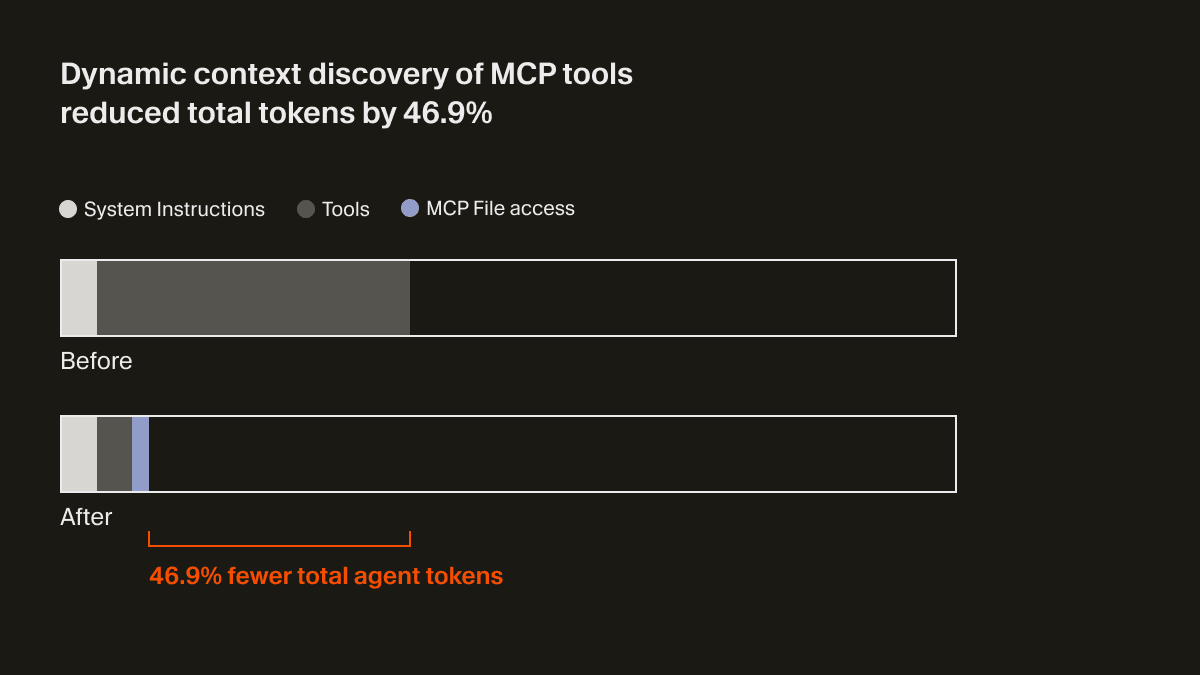
Essa abordagem baseada em arquivos também permite comunicar o status das ferramentas MCP ao agente. Por exemplo, anteriormente, se um servidor MCP precisasse de nova autenticação, o agente simplesmente esquecia completamente essas ferramentas, deixando o usuário confuso. Agora, ele pode avisar proativamente o usuário para fazer a nova autenticação.
5. Tratando todas as sessões do terminal integrado como arquivos
Em vez de precisar copiar/colar a saída de uma sessão de terminal na entrada do agente, o Cursor agora sincroniza as saídas do terminal integrado com o sistema de arquivos local.
Isso torna fácil perguntar "por que meu comando falhou?" e permite que o agente entenda ao que você está se referindo. Como o histórico do terminal pode ser longo, o agente pode usar grep apenas para as saídas relevantes, o que é útil para logs de um processo de longa execução, como um servidor.
Isso reflete o que agentes de código baseados em CLI veem, com a saída anterior do shell em contexto, mas descoberta dinamicamente em vez de inserida estaticamente.
Abstrações simples
Não está claro se arquivos serão a interface final para ferramentas baseadas em LLM.
Mas, à medida que agentes de código melhoram rapidamente, arquivos têm sido uma primitiva simples e poderosa de usar, e uma escolha mais segura do que mais uma abstração que não consegue considerar totalmente o futuro. Fique de olho em muito mais novidades empolgantes que vamos compartilhar neste espaço.
Essas melhorias estarão disponíveis para todos os usuários nas próximas semanas. As técnicas descritas neste post no blog são o trabalho de muitos funcionários da Cursor, incluindo Lukas Moller, Yash Gaitonde, Wilson Lin, Jason Ma, Devang Jhabakh e Jediah Katz. Se você tiver interesse em resolver as tarefas de codificação mais difíceis e ambiciosas usando IA, adoraríamos falar com você. Entre em contato conosco em hiring@cursor.com.
- Consideramos uma abordagem de busca de ferramentas, mas isso espalharia as ferramentas em um índice plano. Em vez disso, criamos uma pasta por servidor, mantendo as ferramentas de cada servidor agrupadas logicamente. Quando o modelo lista uma pasta, ele vê todas as ferramentas daquele servidor juntas e pode entendê-las como uma unidade coesa. Arquivos também permitem buscas mais poderosas. O agente pode usar todos os parâmetros do
rgou até mesmojqpara filtrar descrições de ferramentas. ↩