Como comparamos a qualidade dos modelos no Cursor
Observação: O CursorBench é atualizado continuamente à medida que as capacidades dos agentes evoluem. A versão atual em produção é o CursorBench 3.1; consulte essa página para ver a classificação mais recente.
Os desenvolvedores estão recorrendo a agentes de programação para assumir tarefas mais longas e complexas, que envolvem vários arquivos, ferramentas e etapas. À medida que essas solicitações aumentam de escopo, as evals que medem o desempenho dos agentes também precisam evoluir.
No Cursor, usamos um processo híbrido de avaliação online-offline para manter nossa visão da qualidade dos modelos alinhada ao que os desenvolvedores realmente fazem.
A parte offline usa o CursorBench, nossa suíte interna de avaliação baseada em sessões reais do Cursor da nossa equipe de engenharia. Como as tarefas vêm do uso real do Cursor, e não de repositórios públicos, o CursorBench distingue melhor os modelos e se alinha mais aos resultados reais dos desenvolvedores do que os benchmarks públicos.
Criamos o CursorBench para medir várias dimensões do desempenho do agente, incluindo correção da solução, qualidade do código, eficiência e comportamento na interação. Este post se concentra nos resultados de correção da solução, mas, na prática, avaliamos os agentes em todos esses eixos.
Atualização, maio de 2026: Desde então, atualizamos o CursorBench para a versão 3.1 com problemas mais difíceis. Como a distribuição dos problemas mudou, as pontuações do CursorBench 3.1 podem diferir dos números e gráficos deste post e devem ser comparadas dentro da mesma versão de avaliação.


Complementamos o CursorBench com análises controladas em tráfego real. Essas avaliações online identificam regressões que as suítes offline não capturam, como quando a saída do agente parece correta para um avaliador, mas passa uma sensação pior para o desenvolvedor que está usando o produto.
Juntos, esse ciclo online-offline mantém nossa noção de qualidade dos modelos ancorada em produção à medida que os fluxos de trabalho mudam, e nos permite criar a melhor experiência possível com agentes no Cursor.
As limitações dos benchmarks públicos
Um bom benchmark precisa distinguir entre modelos que apresentam desempenhos diferentes na prática, ao mesmo tempo que reflete como os desenvolvedores realmente usam esses modelos. As avaliações offline públicas têm dificuldade em ambos os aspectos.
A primeira questão é o alinhamento. À medida que os desenvolvedores passam a realizar trabalhos cada vez mais complexos e variados com agentes, benchmarks estáticos ou desalinhados acabam medindo coisas totalmente erradas. A maioria dos benchmarks de SWE, por exemplo, ainda se concentra em tarefas de correção de bugs. Da mesma forma, o Terminal-Bench enfatiza tarefas amplas em estilo de quebra-cabeça, como encontrar o melhor lance de xadrez a partir de uma posição no tabuleiro. Na nossa visão, isso não está bem alinhado com o trabalho de programação que os desenvolvedores pedem aos agentes para realizar.
A segunda é a avaliação. Muitas tarefas de benchmarks públicos pressupõem um conjunto restrito de soluções corretas, mas a maioria das solicitações dos desenvolvedores é subespecificada o suficiente para admitir muitas abordagens válidas. Como resultado, os benchmarks tendem a penalizar abordagens alternativas corretas ou a acrescentar requisitos sintéticos para eliminar a subespecificação. Nenhuma dessas opções fornece uma avaliação precisa do desempenho real.
A terceira é a contaminação. SWE-bench Verified, Pro e Multilingual extraem tarefas de repositórios públicos que acabam entrando nos dados de treinamento dos modelos, inflando as pontuações. A OpenAI recentemente deixou de relatar por completo os resultados do SWE-bench Verified depois de constatar que modelos de ponta conseguiam reproduzir patches de referência de memória e que quase 60% dos problemas não resolvidos tinham testes com falhas.
O resultado é que, no nível dos modelos de ponta, esses benchmarks já não conseguem diferenciar modelos com utilidade muito diferente para os desenvolvedores.
Construindo o CursorBench
Obtemos tarefas para o CursorBench usando o Cursor Blame, que rastreia o código commitado até a solicitação ao agente que o produziu. Isso nos dá um pareamento natural entre a consulta do desenvolvedor e a solução de referência. Muitas tarefas vêm da nossa base de código interna e de fontes controladas, o que reduz o risco de os modelos já terem visto essas tarefas durante o treinamento. Atualizamos o conjunto a cada poucos meses para acompanhar as mudanças na forma como os desenvolvedores usam agentes.
O escopo dos problemas em nossas avaliações de corretude praticamente dobrou da versão inicial para a atual, CursorBench-3, tanto em linhas de código quanto no número médio de arquivos. As tarefas do CursorBench-3 envolvem substancialmente mais linhas do que as do SWE-bench Verified, Pro ou Multilingual. Embora linhas de código sejam uma medida imperfeita de dificuldade, o crescimento nessa métrica reflete a forma como incorporamos tarefas mais desafiadoras ao CursorBench, como lidar com ambientes com vários workspaces e monorepos, investigar logs de produção e executar experimentos de longa duração.
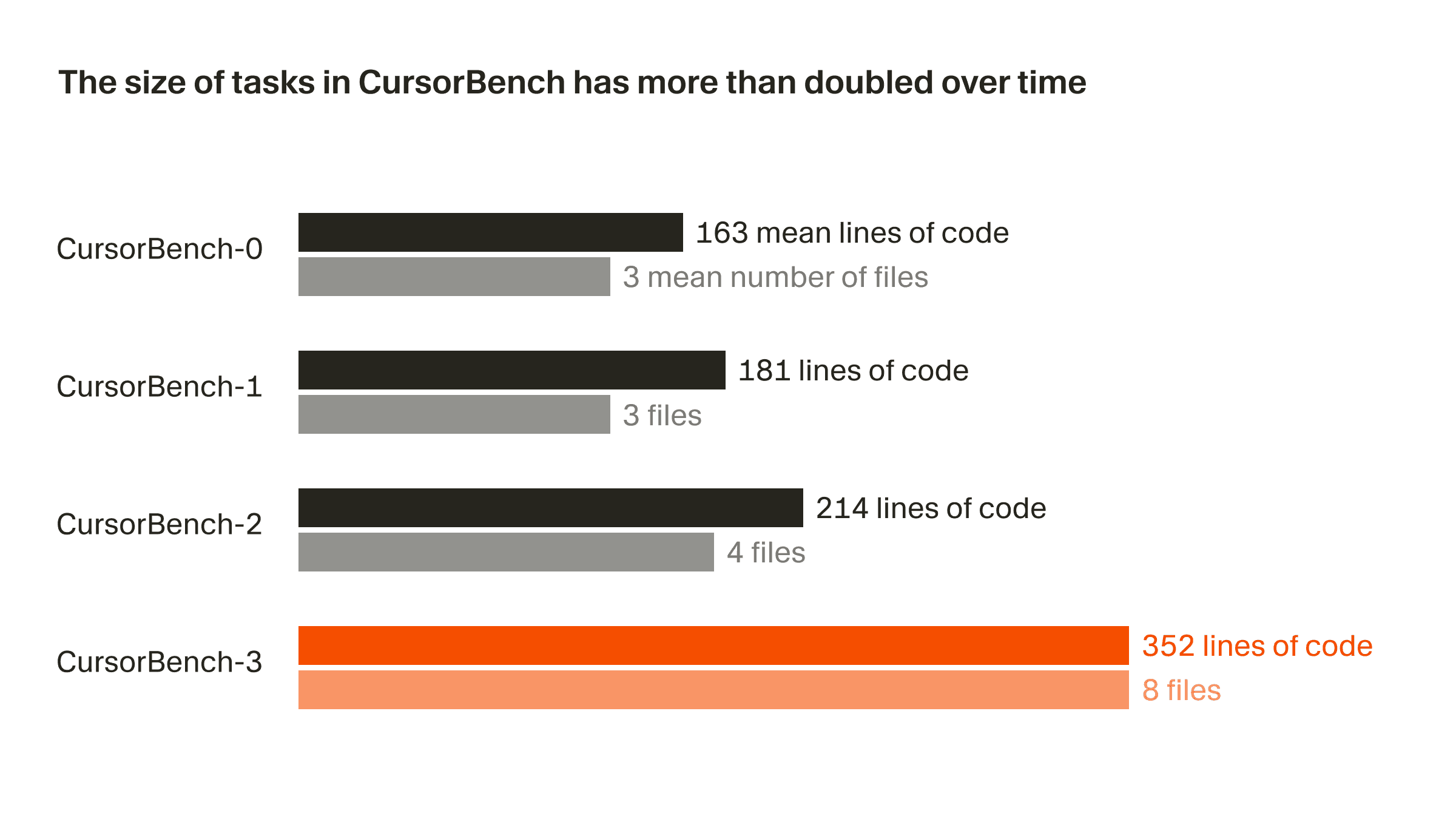
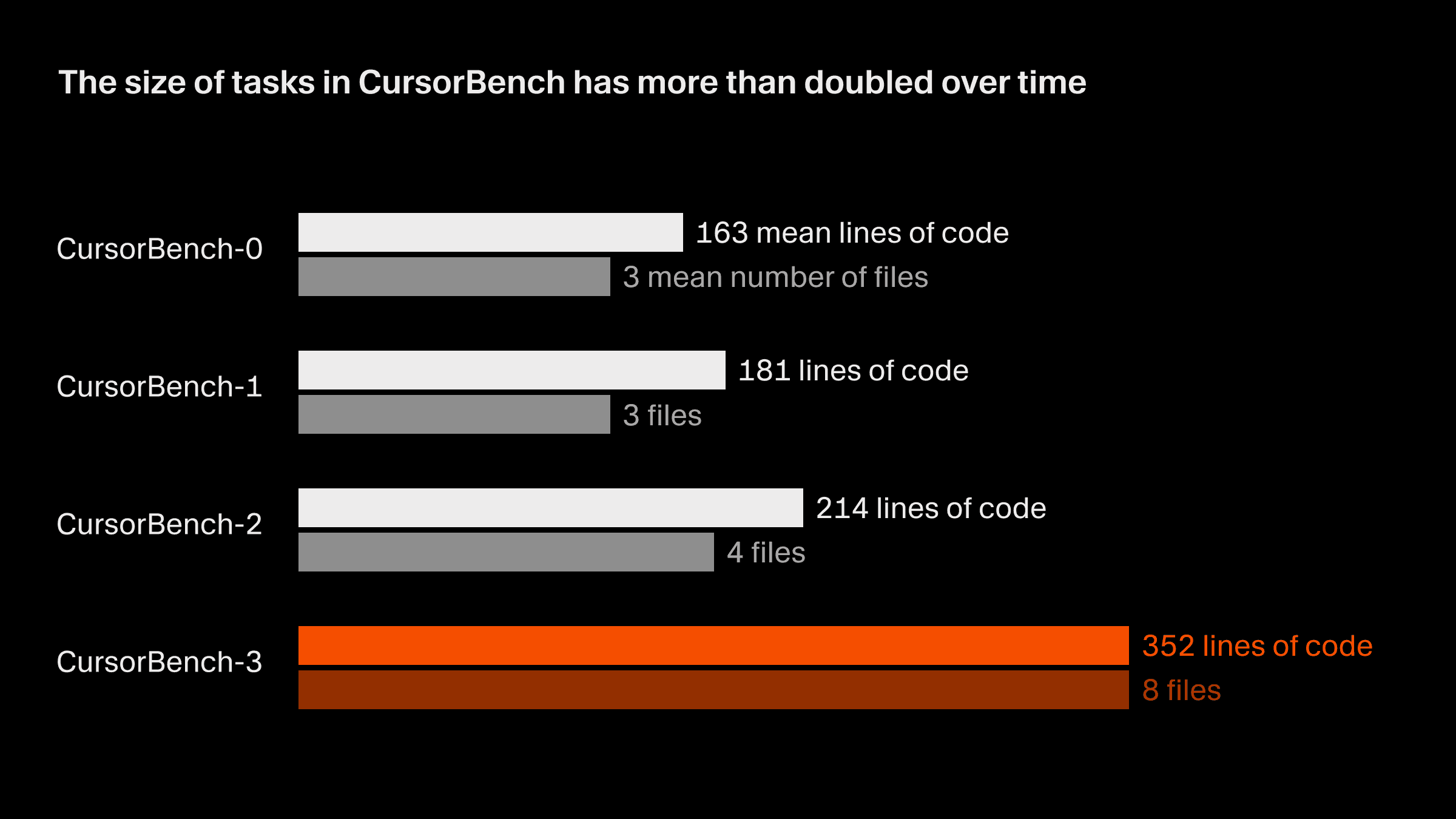
As tarefas do CursorBench também se alinham à forma pouco especificada e frequentemente ambígua como os desenvolvedores falam com agentes. Nossas descrições de tarefas são intencionalmente curtas, em contraste com as issues detalhadas do GitHub usadas em benchmarks públicos, e usamos avaliadores baseados em agentes para pontuá-las com confiabilidade.


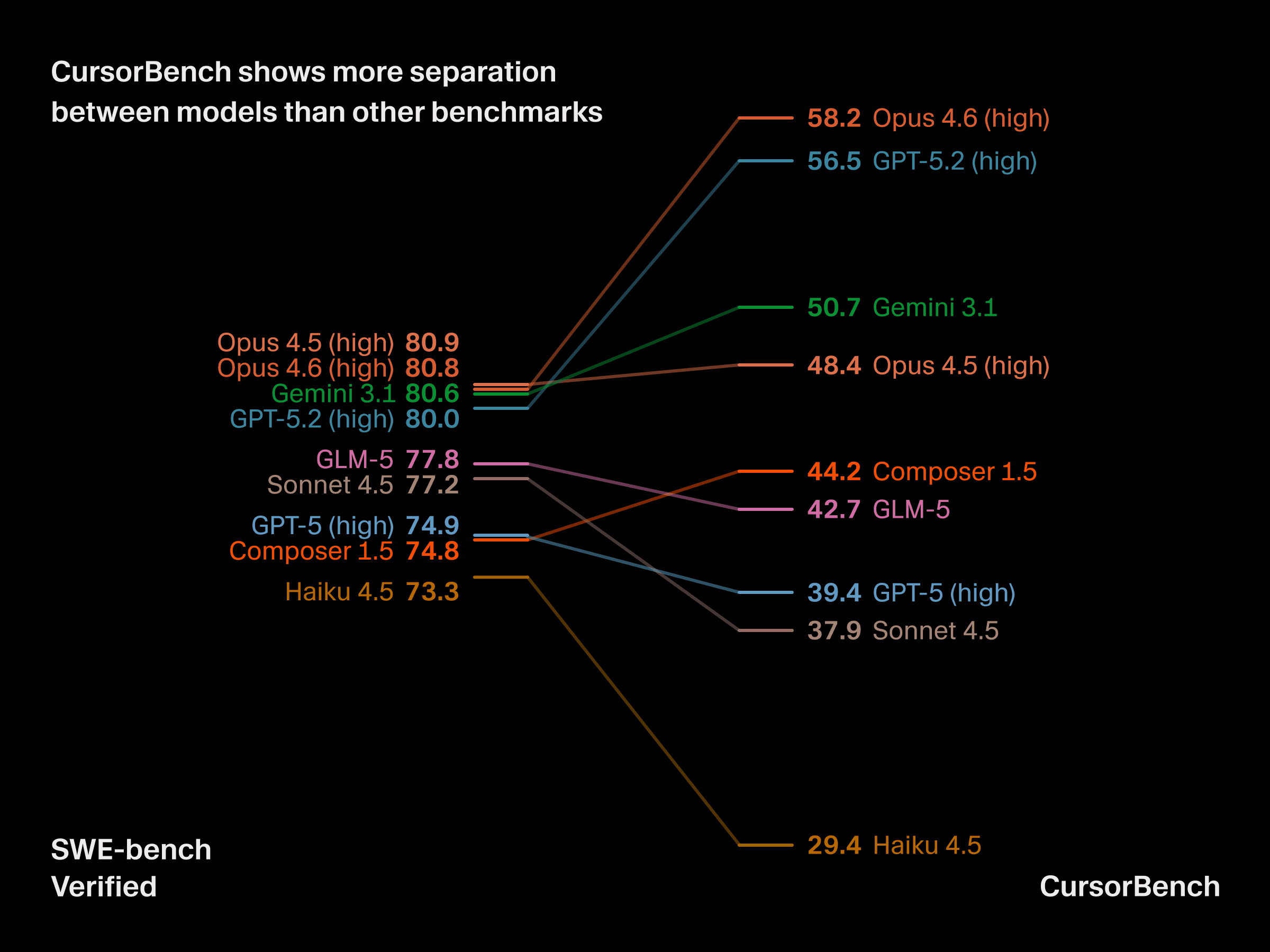
CursorBench mostra maior diferenciação entre modelos
Essas diferenças na complexidade das tarefas e no nível de especificação têm consequências práticas para a utilidade do benchmark. O CursorBench gera maior diferenciação entre modelos em níveis de fronteira, onde os benchmarks públicos estão cada vez mais saturados e, em alguns casos, modelos como Haiku conseguem igualar ou superar o GPT-5. O CursorBench distingue de forma confiável modelos que desenvolvedores percebem como significativamente diferentes.

As pontuações do CursorBench se alinham com avaliações online
A avaliação online mede se as melhorias no nosso agente realmente ajudam os desenvolvedores na prática. Acompanhamos um conjunto de indicadores de alto nível dos resultados do agente, incluindo sinais tanto de interação quanto de qualidade da saída, e buscamos movimentos consistentes entre eles, em vez de otimizar qualquer métrica isolada. Agregar esses sinais nos permite identificar regressões em que a saída do agente pontua bem em um avaliador offline, mas na prática não funciona bem para os desenvolvedores.
Usamos experimentos online controlados para atribuir impacto. Por exemplo, ao iterar em busca e recuperação semânticas, fizemos um teste de ablação removendo totalmente a ferramenta de busca semântica. Isso nos permitiu identificar com precisão os cenários em que a busca semântica mais importava, como perguntas e respostas fundamentadas no repositório em bases de código maiores.
As classificações do CursorBench também acompanham mais de perto como os desenvolvedores percebem a qualidade do modelo no Cursor, conforme medido por nossas métricas de avaliação online.


A próxima suíte de evals
Embora as tarefas do CursorBench-3 sejam mais longas do que as de benchmarks públicos, elas ainda são concluídas em uma única sessão. Prevemos que, ao longo do próximo ano, a grande maioria do trabalho de desenvolvimento migrará para agentes de longa duração operando em seus próprios computadores, e planejamos adaptar o CursorBench a isso. Para isso, será preciso encontrar formas de baratear a avaliação, garantir a reprodutibilidade de tarefas que interagem com serviços externos e reduzir a distância entre a avaliação offline e a experiência real dos desenvolvedores.
O ciclo online-offline nos dá o que acreditamos ser a base certa, e pretendemos compartilhar mais à medida que avançarmos nesse trabalho.
Se você tem interesse em trabalhar em problemas técnicos complexos relacionados ao futuro da programação, entre em contato pelo e-mail hiring@cursor.com.