Um relatório técnico sobre o Composer 2

Publicamos no arXiv um relatório técnico sobre o treinamento do Composer 2, nosso modelo de programação para engenharia de software agêntica.
O relatório cobre todo o processo de treinamento, desde o pré-treinamento contínuo em um modelo base aberto, o Kimi K2.5, até o aprendizado por reforço em larga escala, com foco em reproduzir com fidelidade o ambiente real do Cursor.
Pré-treinamento contínuo e RL
O Composer 2 é treinado em duas fases: pré-treinamento contínuo em uma mistura de dados com ênfase em código para aprofundar o conhecimento de programação do modelo base, seguido de aprendizado por reforço em larga escala para melhorar a performance do agente de ponta a ponta. Constatamos que reduzir a perda no pré-treinamento melhora a performance do RL nas etapas seguintes, com um conhecimento base melhor se traduzindo de forma consistente em um agente melhor.
O treinamento de RL do Composer 2 acontece em sessões realistas do Cursor, com as mesmas ferramentas e o mesmo harness usados pelo modelo em produção, aplicados a uma distribuição de problemas que reflete toda a variedade de tarefas que os desenvolvedores pedem ao Composer para realizar. Constatamos que o treinamento de RL melhora tanto a performance média quanto a performance best-of-K, sugerindo que o modelo está aprendendo novos caminhos de solução, em vez de apenas se concentrar nos já conhecidos.
Avaliação em cenários reais com CursorBench
Um dos principais desafios ao desenvolver modelos para programação é que os benchmarks públicos muitas vezes não refletem o trabalho que os desenvolvedores realmente fazem. As tarefas são excessivamente especificadas, as soluções são restritas, e as bases de código são pequenas.
Criamos o CursorBench com base em sessões reais de programação da nossa equipe de engenharia. Ele inclui tarefas em que o prompt é curto e ambíguo, e as soluções exigem centenas de linhas de alterações em vários arquivos. Usamos o CursorBench em todo o treinamento e na avaliação para manter o modelo alinhado a problemas reais.
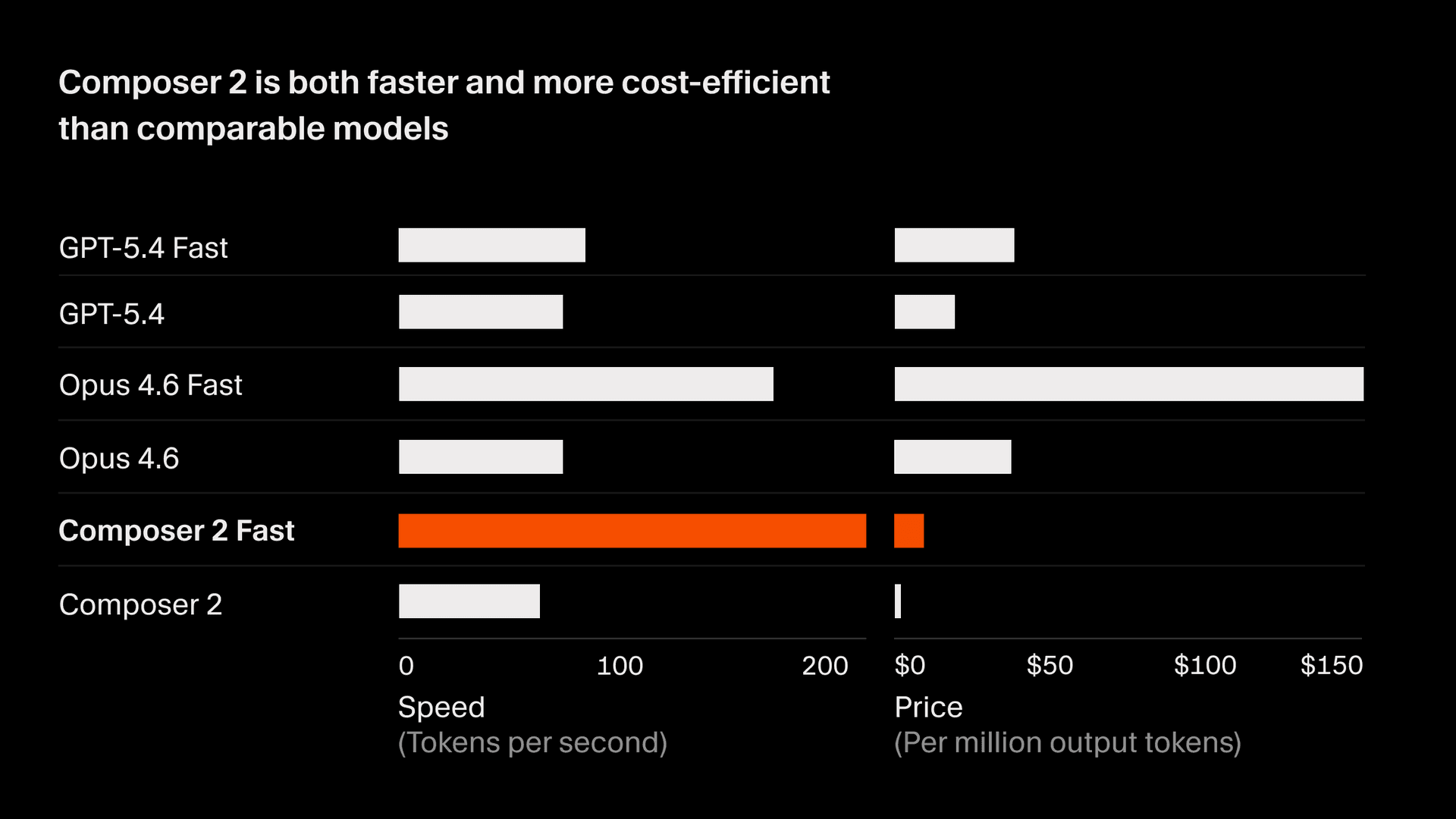
Performance
No CursorBench, o Composer 2 alcança 61,3 — um ganho de 37% em relação ao Composer 1.5 — e se mostra competitivo com os modelos de ponta mais avançados. Em benchmarks públicos, o Composer 2 obtém 73,7 no SWE-bench Multilingual e 61,7 no Terminal-Bench. Ele atinge esses resultados com um custo de inferência significativamente menor do que o de modelos comparáveis, oferecendo uma relação Pareto-ótima entre acurácia e custo para fluxos de trabalho interativos de desenvolvedores.



Infraestrutura
O treinamento do Composer 2 exigiu um desenvolvimento substancial de infraestrutura, com kernels personalizados de baixa precisão para treinar MoE com eficiência em GPUs Blackwell, um pipeline de RL totalmente assíncrono que abrange várias regiões e o Anyrun, nossa plataforma interna de computação para executar centenas de milhares de ambientes de programação isolados. O relatório cobre toda a stack, incluindo nossa abordagem para sincronização de pesos, tolerância a falhas e fidelidade dos ambientes.
O relatório traz muito mais detalhes sobre tudo isso, incluindo estudos de ablação da configuração de treinamento, nossa abordagem para modelar o comportamento do agente e o design da nossa suíte de avaliação.
Agradecemos às equipes por trás de Kimi K2.5, Ray, ThunderKittens, PyTorch e à comunidade open source em geral. Também gostaríamos de agradecer à Fireworks e à Colfax pela colaboração e parceria.
Leia o relatório técnico completo aqui.