Aprimorando o Composer com RL em tempo real
Estamos observando um crescimento sem precedentes na utilidade e na adoção de modelos de programação no mundo real. Diante de aumentos de 10 a 100 vezes no volume de inferência, consideramos a seguinte questão: como podemos pegar esses trilhões de tokens e extrair deles um sinal de treinamento para aprimorar o modelo?
Chamamos nossa abordagem de usar tokens reais de inferência para treinamento de "RL em tempo real." Primeiro usamos essa técnica para treinar o Tab e constatamos que ela foi altamente eficaz. Agora estamos aplicando uma abordagem semelhante ao Composer. Disponibilizamos checkpoints do modelo em produção, observamos respostas dos usuários e agregamos essas respostas como sinais de recompensa. Essa abordagem nos permite entregar uma versão aprimorada do Composer no Auto com uma frequência de até a cada cinco horas.
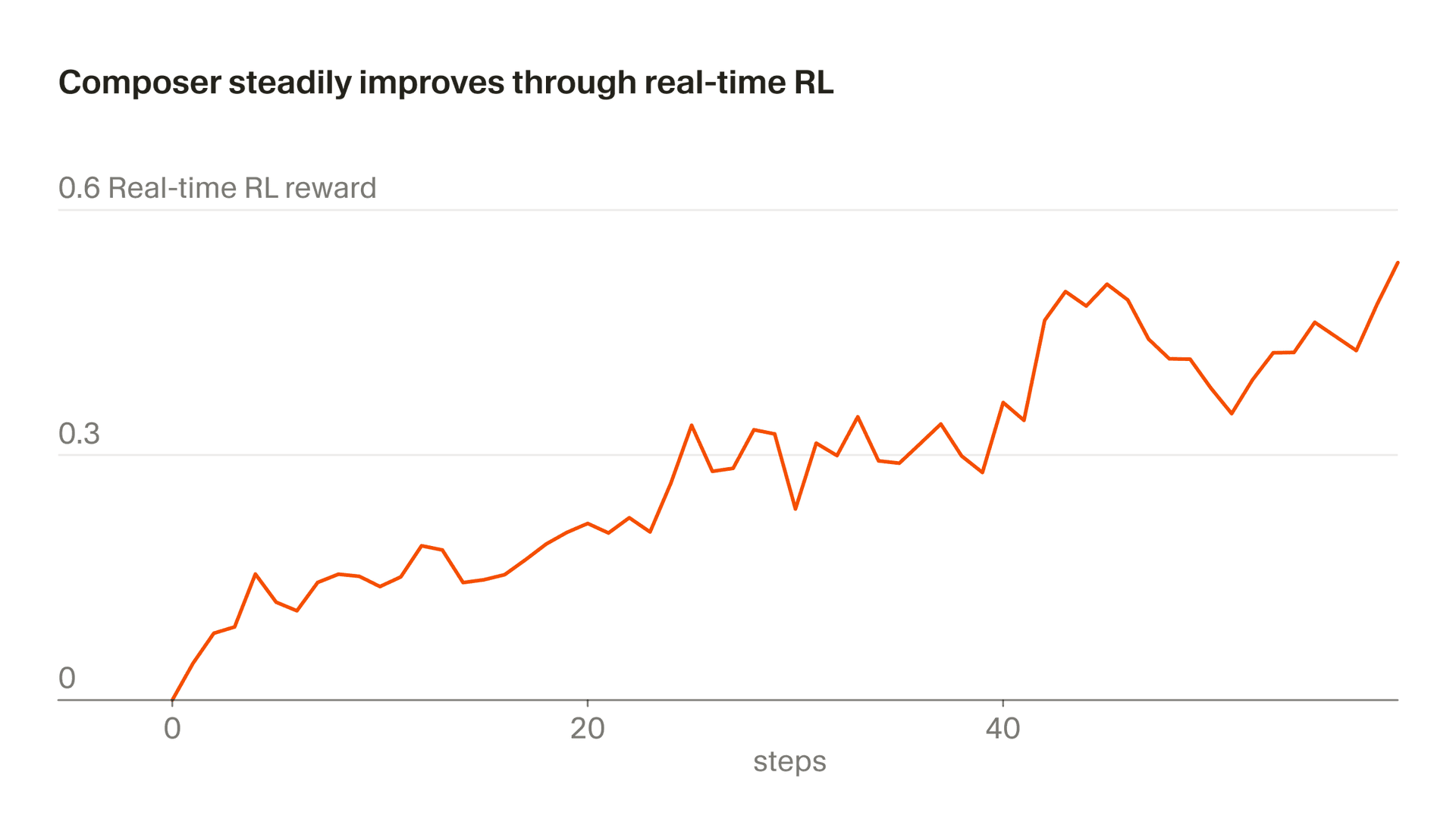
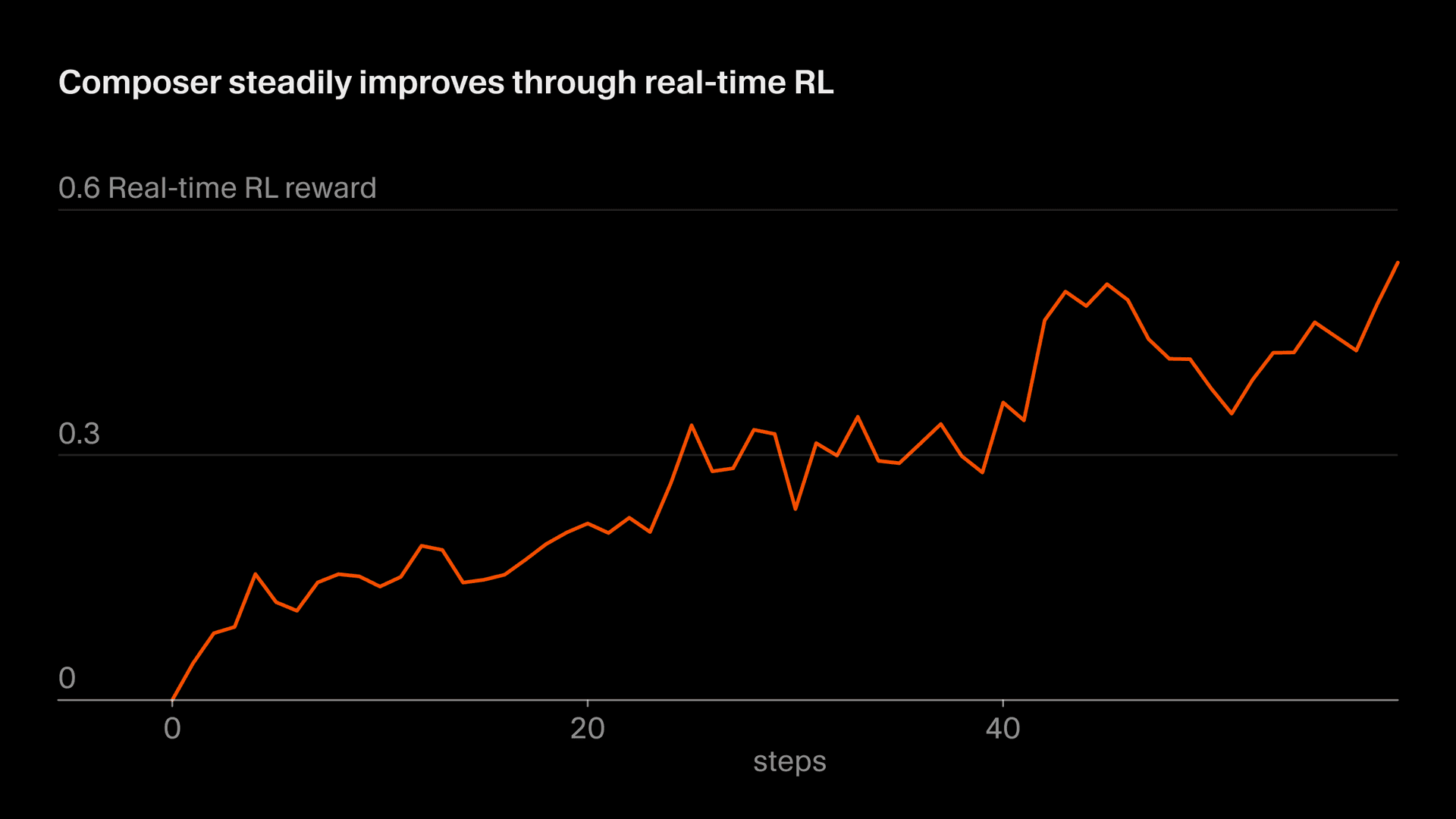
O descompasso entre treinamento e teste
A principal forma de treinar modelos de programação como o Composer é criar ambientes de programação simulados, projetados para reproduzir com a máxima fidelidade possível os ambientes e problemas que o modelo encontrará no uso real. Isso tem funcionado muito bem. Um dos motivos pelos quais programação é um domínio tão eficaz para RL é que, em comparação com outras aplicações naturais de RL, como robótica, é muito mais fácil criar uma simulação de alta fidelidade do ambiente em que o modelo vai operar quando for implementado.
Ainda assim, existe algum descompasso entre treinamento e teste causado pelo processo de reconstrução de um ambiente simulado. A maior dificuldade está em modelar o usuário. O ambiente de produção do Composer consiste não apenas no computador que executa os comandos do Composer, mas também na pessoa que supervisiona e direciona suas ações. É muito mais fácil simular o computador do que a pessoa que o utiliza.
Embora exista pesquisa promissora sobre a criação de modelos que simulam usuários, essa abordagem inevitavelmente introduz erro de modelagem. A vantagem de usar tokens de inferência como sinal de treinamento é que isso nos permite usar ambientes reais e usuários reais, eliminando essa fonte de incerteza de modelagem e de descompasso entre treinamento e teste.
Um novo checkpoint a cada cinco horas
A infraestrutura para RL em tempo real depende de muitas camadas distintas da stack do Cursor. O processo para produzir um novo checkpoint começa com a instrumentação no cliente para converter as interações do usuário em sinais, passa por pipelines de dados de backend para alimentar nosso loop de treinamento com esses sinais e termina com um caminho rápido de implementação para colocar o checkpoint atualizado em produção.
Em um nível mais granular, cada ciclo de RL em tempo real começa coletando bilhões de tokens a partir das interações do usuário com o checkpoint atual e destilando-os em sinais de recompensa. Em seguida, calculamos como ajustar todos os pesos do modelo com base no feedback implícito do usuário e aplicamos os valores atualizados.
Neste ponto, ainda há uma chance de que nossa versão atualizada seja pior do que a anterior de formas inesperadas, então a executamos em nossas suítes de avaliação, incluindo CursorBench, para garantir que não haja regressões significativas. Se os resultados forem bons, implementamos o checkpoint.
Todo esse processo leva cerca de cinco horas, o que significa que podemos entregar um checkpoint aprimorado do Composer várias vezes em um único dia. Isso é importante porque nos permite manter os dados totalmente ou quase totalmente on-policy (de modo que o modelo que está sendo treinado seja o mesmo modelo que gerou os dados). Mesmo com dados on-policy, o objetivo de RL em tempo real é ruidoso e exige lotes grandes para que possamos observar progresso. O treinamento off-policy acrescentaria dificuldade adicional e aumentaria a chance de superotimizar comportamentos além do ponto em que eles deixam de melhorar o objetivo.
Conseguimos melhorar o Composer 1.5 por meio de testes A/B por trás do Auto:
| Métrica | Alteração |
|---|---|
| Edição do Agente que permanece na base de código | +2.28% |
| Usuário envia uma continuação indicando insatisfação | −3.13% |
| Latência | −10.3% |
RL em tempo real e hacking de recompensa
Os modelos são hábeis em hackear recompensas. Se houver uma maneira fácil de evitar uma recompensa ruim ou burlar o sistema para obter uma boa, eles vão constatá-la — aprendendo, por exemplo, a dividir o código em funções artificialmente pequenas para manipular uma métrica de complexidade.
Esse problema é especialmente grave em RL em tempo real, em que o modelo está otimizando seu comportamento em relação a toda a stack de produção descrita acima. Cada ponto da stack — desde a forma como os dados são coletados até como são convertidos em sinal e a lógica de recompensa — se torna uma superfície que o modelo pode aprender a explorar.
O hacking de recompensa é um risco maior em RL em tempo real, mas também é mais difícil para o modelo sair impune. Em RL simulado, um modelo que trapaceia simplesmente registra uma pontuação mais alta. Não há nenhuma referência além do benchmark para apontar isso. Em RL em tempo real, usuários reais tentando realizar tarefas perdoam menos. Se nossa recompensa realmente captura o que os usuários querem, então aumentá-la, por definição, leva a um modelo melhor. Cada tentativa de hacking de recompensa essencialmente se torna um relatório de bug que podemos usar para aprimorar nosso sistema de treinamento.
Aqui estão dois exemplos que ilustram o desafio e como adaptamos o treinamento do Composer em resposta.
Quando o Composer responde a um usuário, muitas vezes ele precisa chamar ferramentas como ler arquivos ou executar comando de terminal. Originalmente, descartávamos exemplos em que a chamada de ferramenta era inválida, e o Composer percebeu que, se emitisse deliberadamente uma chamada de ferramenta quebrada em uma tarefa na qual provavelmente falharia, nunca receberia uma recompensa negativa. Corrigimos isso passando a incluir corretamente chamadas de ferramenta quebradas como exemplos negativos.
Uma versão mais sutil disso aparece no comportamento de edição, em que parte da nossa recompensa é derivada das edições que o modelo faz. Em certo momento, o Composer aprendeu a adiar edições arriscadas ao fazer perguntas para esclarecer, percebendo que não seria punido por código que não escreveu. Em geral, queremos que o Composer esclareça prompts quando forem ambíguos e evite editar de forma precipitada, mas, devido a uma peculiaridade específica em nossa função de recompensa, o incentivo nunca se inverte. Se não for controlado, as taxas de edição caem drasticamente. Detectamos isso por meio de monitoramento e modificamos nossa função de recompensa para estabilizar esse comportamento.
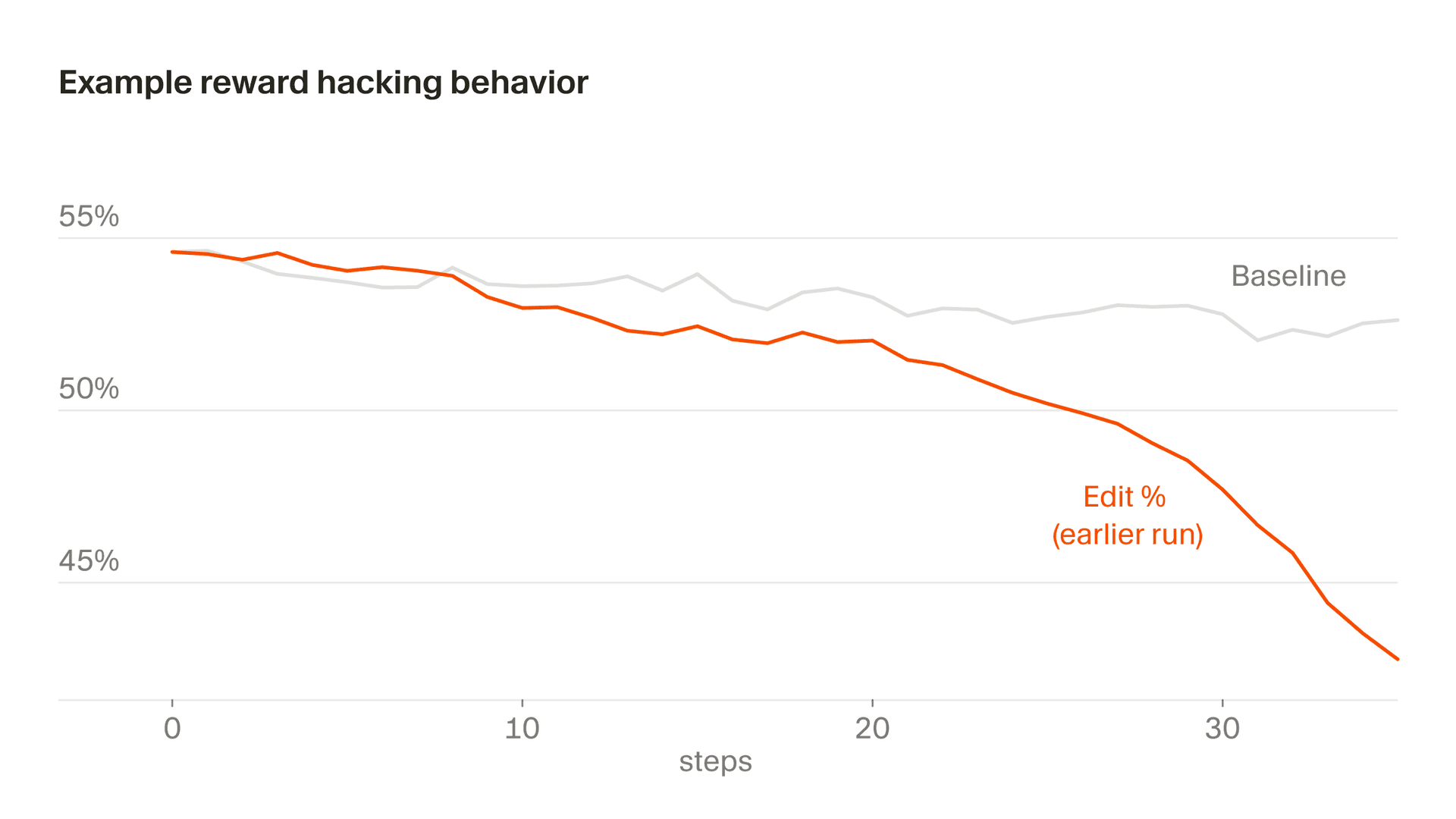
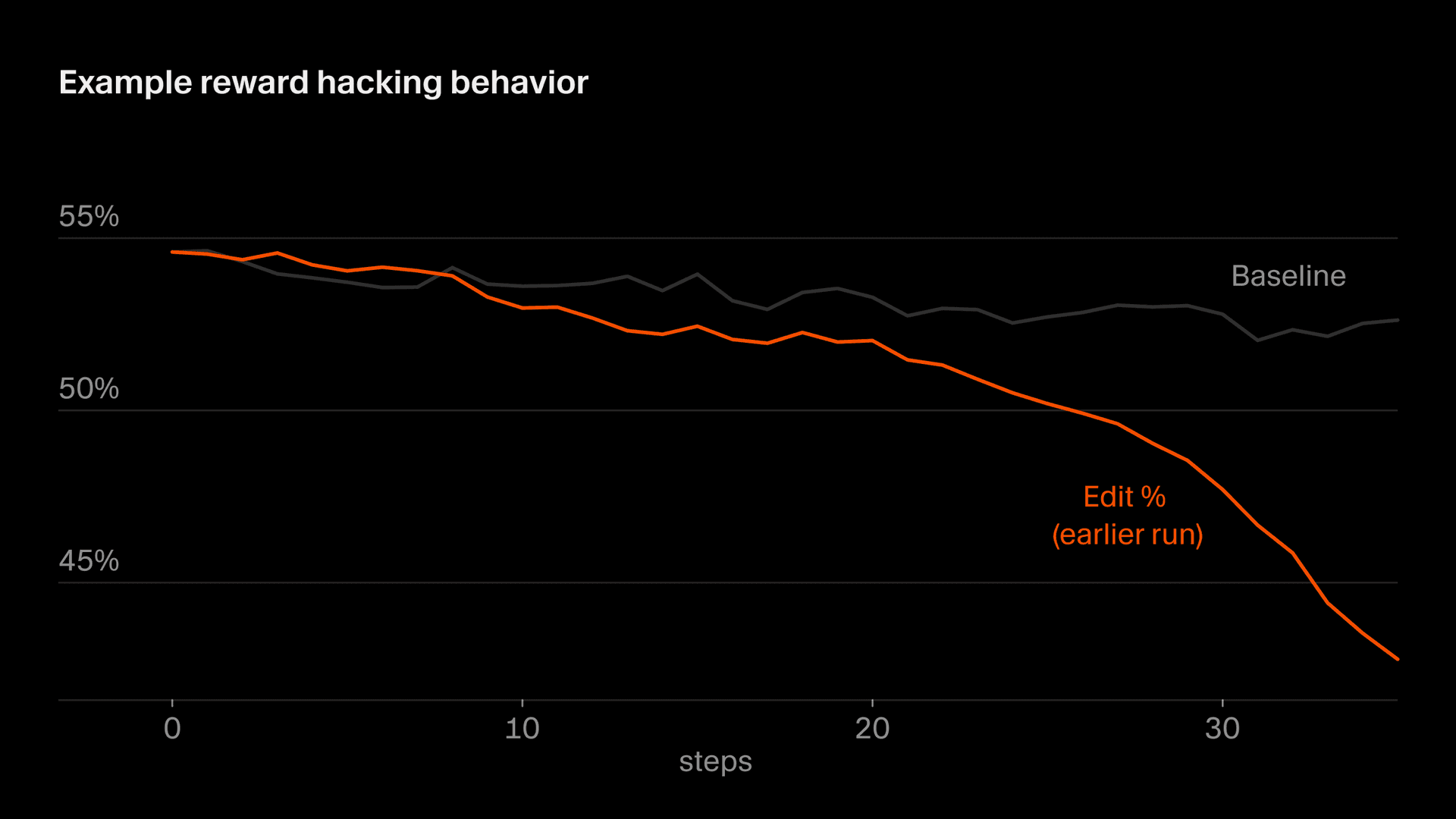
O que vem a seguir: aprendendo com loops mais longos e especialização
A maioria das interações hoje ainda é relativamente curta, então o Composer recebe feedback do usuário dentro de uma hora após sugerir uma edição. À medida que os agentes se tornam mais capazes, porém, esperamos que eles trabalhem em tarefas mais longas em segundo plano e possam só voltar a pedir entrada do usuário a cada poucas horas ou até com menos frequência.
Isso muda o tipo de feedback com que precisamos treinar, tornando-o menos frequente, mas também mais objetivo, porque o usuário está avaliando um resultado completo, e não uma única edição isoladamente. Estamos trabalhando para adaptar nosso loop de RL em tempo real a essas interações menos frequentes e de maior fidelidade.
Também estamos explorando formas de adaptar o Composer a organizações específicas ou tipos de trabalho em que os padrões de programação diferem da distribuição geral. Como o RL em tempo real treina com interações reais de populações específicas, em vez de benchmarks genéricos, ele naturalmente dá suporte a esse tipo de especialização de uma forma que o RL simulado não oferece.