Composer 2를 소개합니다
읽는 데 2분
이제 Cursor에서 Composer 2를 사용할 수 있습니다.
코딩 성능은 프런티어급이며, 가격은 입력 토큰 100만 개당 2.50으로, 지능과 요금의 새로운 최적 조합을 제공합니다. 또한 이 모델을 어떻게 학습시켰는지에 대한 기술 보고서도 공개했습니다.


프런티어급 코딩 지능
저희는 모델 품질을 빠르게 개선하고 있습니다. Composer 2는 Terminal-Bench 2.01 및 SWE-bench Multilingual을 포함한 저희가 측정하는 모든 벤치마크에서 큰 폭의 향상을 보였습니다:
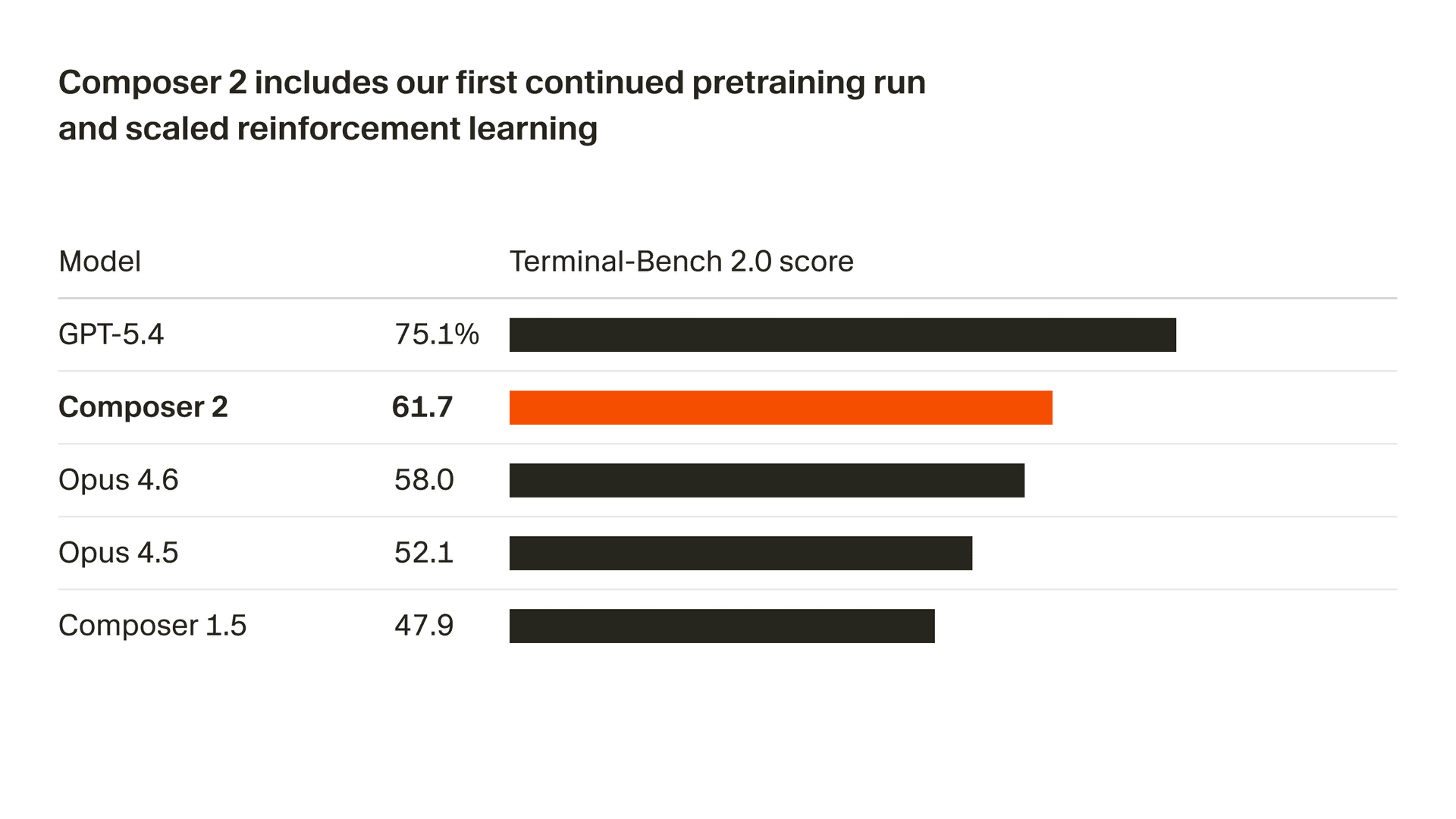
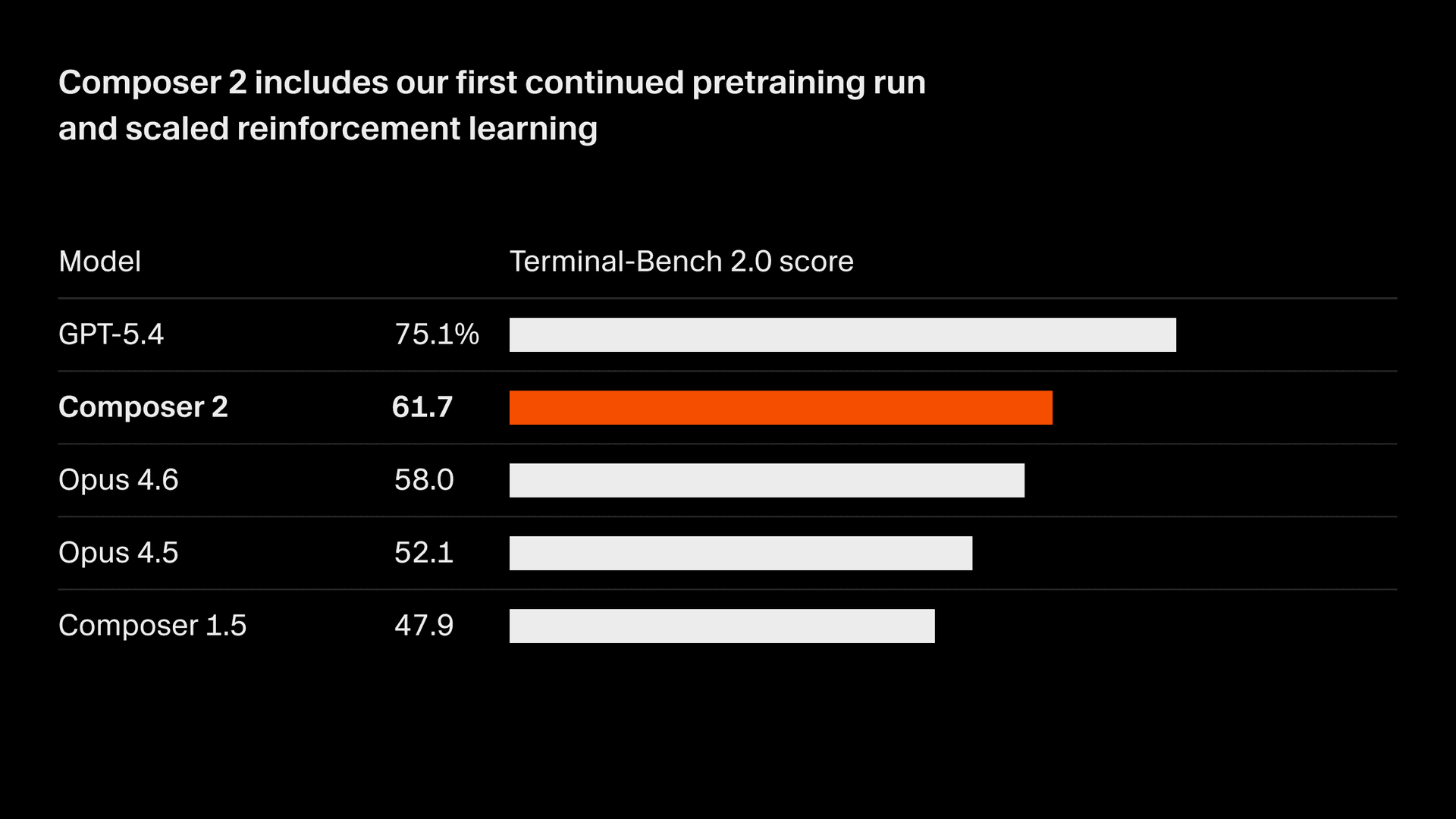
| 모델 | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
이러한 품질 향상은 저희의 첫 지속 사전학습에서 비롯되었으며, 이를 통해 강화 학습을 확장할 수 있는 훨씬 더 강력한 기반을 제공합니다.
이 기반 위에서, 저희는 강화 학습을 통해 장기 코딩 작업을 훈련합니다. Composer 2는 수백 번의 동작이 필요한 도전적인 작업을 해결할 수 있습니다.
Composer 2 사용해 보기
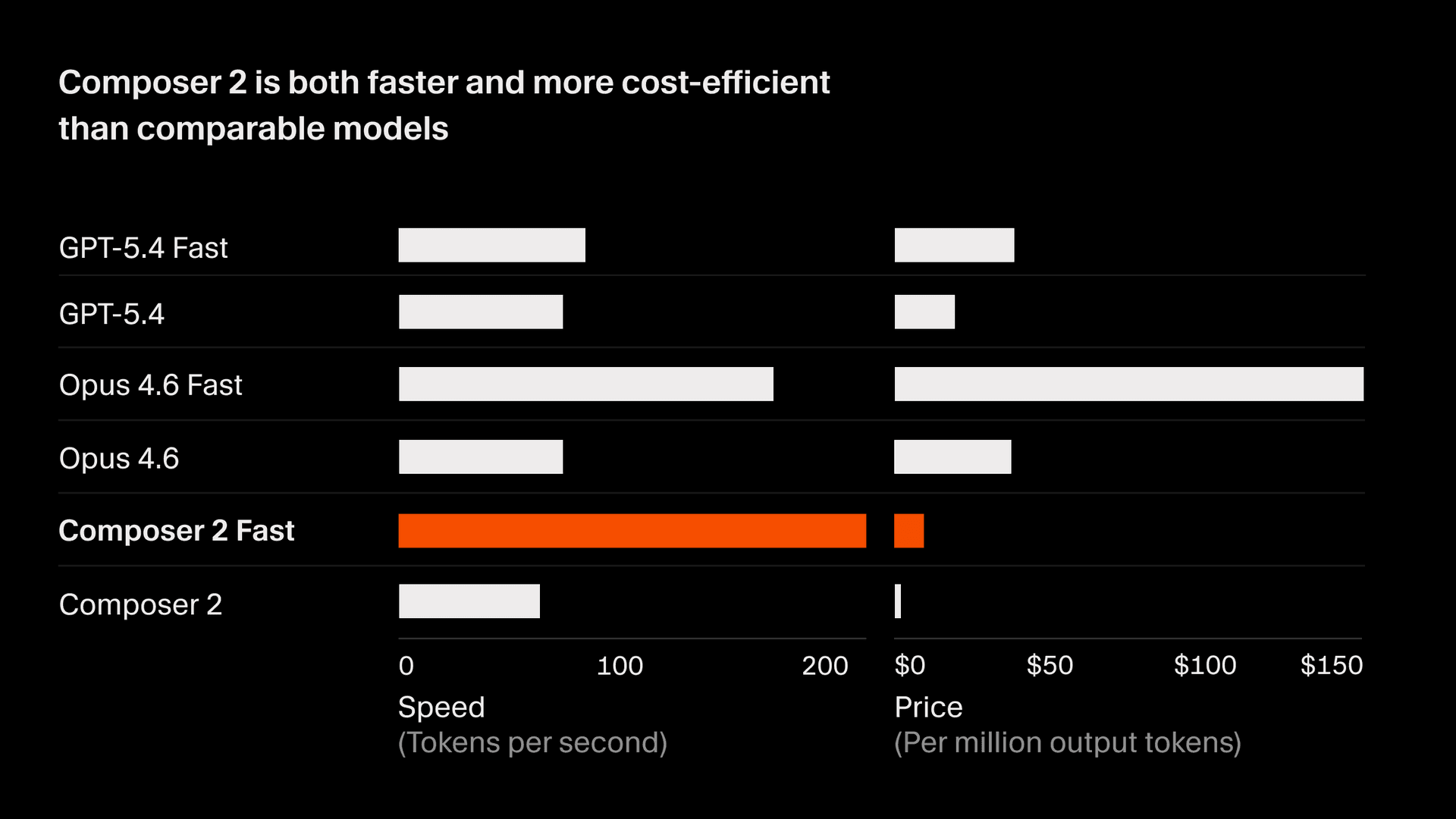
Composer 2의 가격은 입력 토큰 100만 개당 2.50입니다.
또한 동일한 수준의 지능을 제공하는 더 빠른 기본형도 있으며, 가격은 입력 토큰 100만 개당 7.50입니다. 이 빠른 기본형은 다른 고속 모델보다 비용이 더 낮습니다2. 이 빠른 기본형을 기본 옵션으로 제공할 예정입니다. 자세한 내용은 현재 Composer 모델 문서에서 확인하세요.

개별 플랜에서는 Composer 사용량이 넉넉한 기본 제공량이 포함된 자사 모델 풀에 포함됩니다. 지금 바로 Cursor 또는 새 인터페이스의 초기 알파 버전에서 Composer 2를 사용해 보세요.
- Terminal-Bench 2.0은 Laude Institute에서 관리하는 터미널 사용용 에이전트 평가 벤치마크입니다. Anthropic 모델 점수는 Claude Code 하네스를 사용하고, OpenAI 모델 점수는 Simple Codex 하네스를 사용합니다. Cursor 점수는 기본 벤치마크 설정에서 공식 Harbor 평가 프레임워크(Terminal-Bench 2.0용으로 지정된 하네스)를 사용해 계산했습니다. 각 모델-에이전트 쌍마다 5회씩 실행했으며, 평균값을 보고합니다. 벤치마크에 대한 자세한 정보는 공식 Terminal Bench 웹사이트에서 확인할 수 있습니다. Composer 2를 제외한 다른 모델의 경우, 공식 leaderboard 점수와 저희 인프라에서 실행해 기록한 점수 중 더 높은 값을 사용했습니다. ↩
- 모든 모델의 초당 토큰 수(TPS)는 2026년 3월 18일 Cursor 트래픽의 스냅샷을 기준으로 합니다. Composer와 GPT 모델의 토큰 크기는 비슷합니다. Anthropic 토큰은 약 15% 더 작으며, TPS 수치는 이를 반영해 정규화되었습니다. 마찬가지로 Anthropic이 아닌 모델의 출력 토큰 가격도 동일한 약 15% 변화에 맞게 조정되었습니다. 속도는 provider의 용량과 시간에 따른 개선에 따라 달라질 수 있습니다. ↩