Composer 2 のご紹介
読了時間 2分
Composer 2 が Cursor で利用可能になりました。
コーディング性能はフロンティアレベルで、価格は入力トークン 2.50/M であり、知能とコストの新たな最適な組み合わせとなっています。また、そのトレーニング方法についての技術レポートも公開しました。


フロンティアレベルのコーディング知能
私たちは、モデルの品質を急速に向上させています。Composer 2 は、Terminal-Bench 2.01 と SWE-bench Multilingual を含む、当社が測定しているすべてのベンチマークで大幅な改善を実現しています。
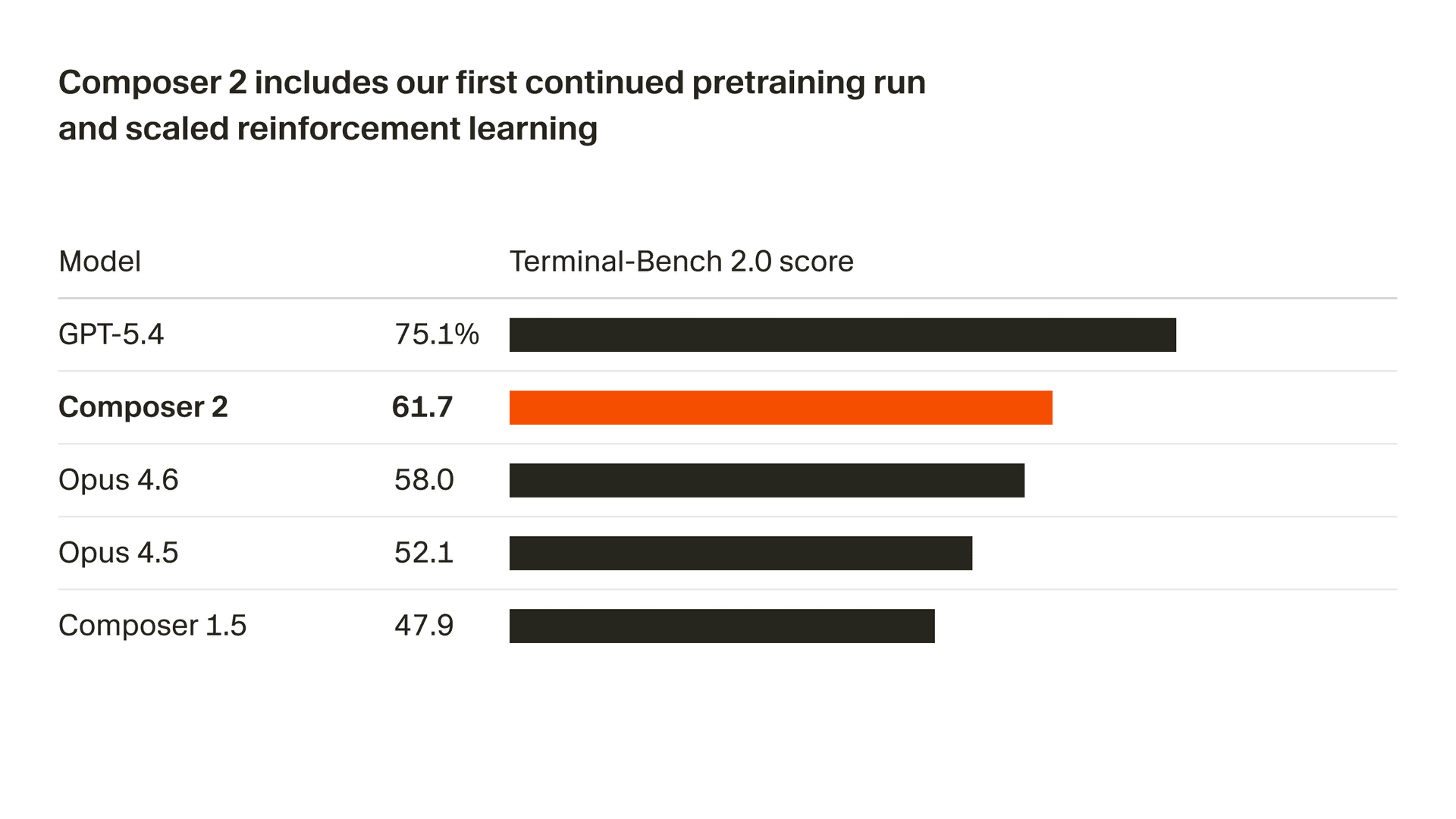
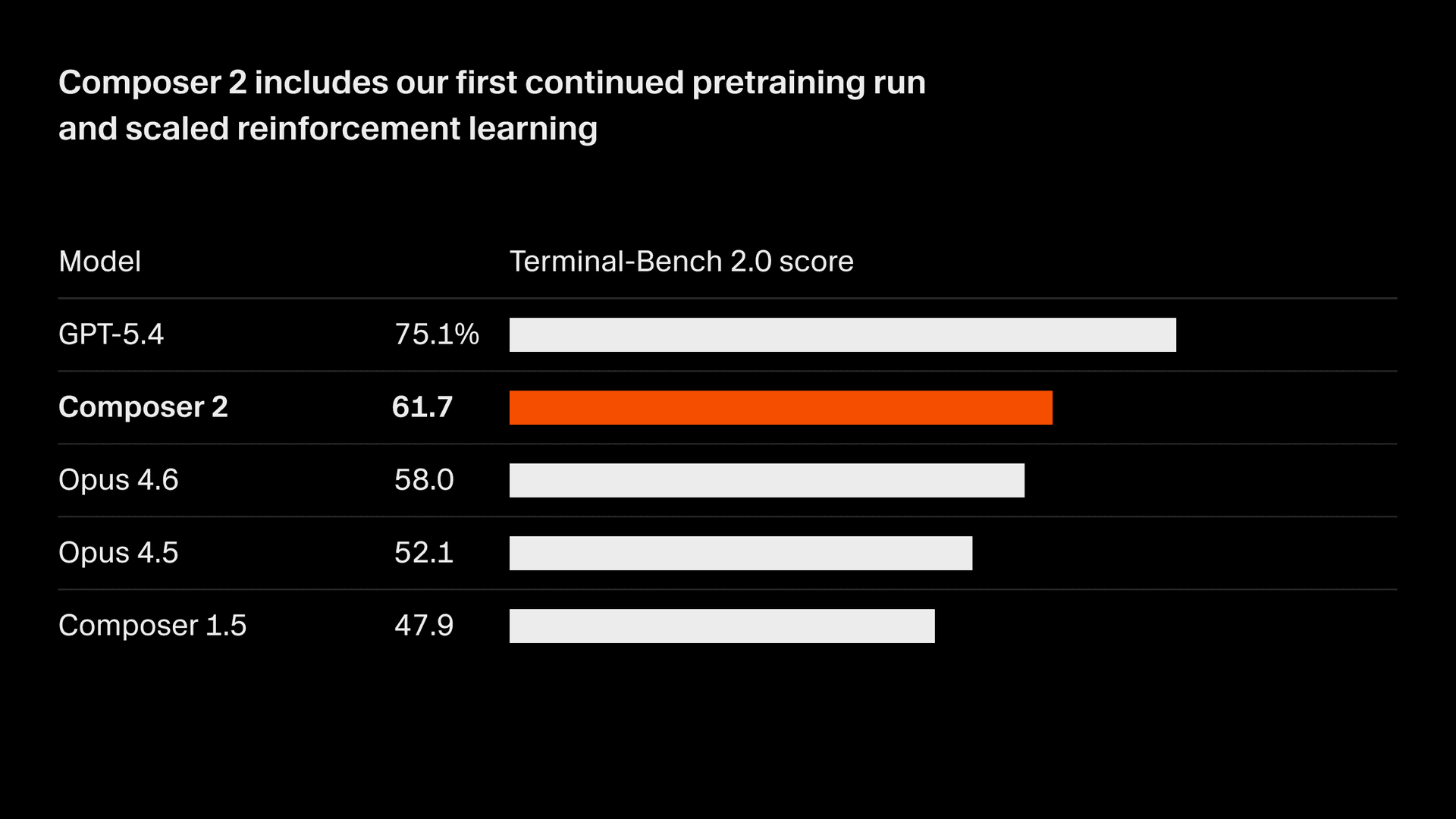
| モデル | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
これらの品質向上は、初めて行った継続事前学習によるもので、強化学習をさらにスケールさせるための、はるかに強力な土台を提供しています。
この土台の上で、私たちは長いホライズンのコーディングタスクについて、強化学習を通じて学習を行っています。Composer 2 は、何百ものアクションを必要とする難しいタスクをこなせます。
Composer 2を試す
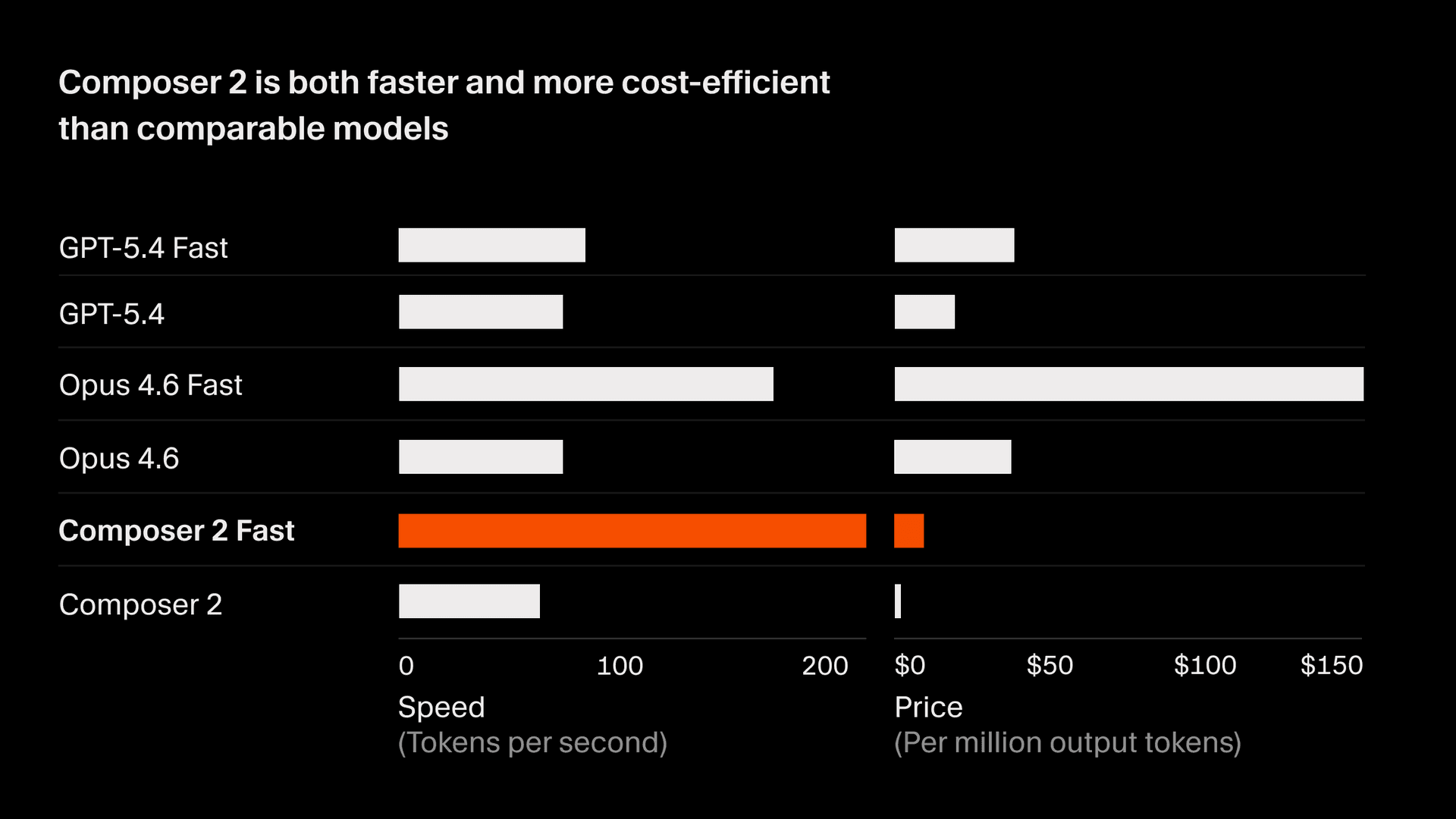
Composer 2 の価格は、入力トークン 2.50/M です。
さらに、同等の知能を備えた、より高速なバリアントもあり、価格は入力トークン 7.50/M で、他の高速モデルよりも低価格です2。fast はデフォルトのオプションとなります。詳しくは、現在の Composer モデルドキュメントをご覧ください。

個人プランでは、Composer の使用量は、十分な利用枠を含む First-party models pool に含まれます。今すぐ Cursor または当社の新しいインターフェースの初期アルファ版で Composer 2 をお試しください。
- Terminal-Bench 2.0 は、Laude Institute が管理する、ターミナル利用向けのエージェント評価ベンチマークです。Anthropic モデルのスコアには Claude Code harness を使用し、OpenAI モデルのスコアには Simple Codex harness を使用しています。Cursor のスコアは、デフォルトのベンチマーク設定で、公式の Harbor evaluation framework(Terminal-Bench 2.0 用に指定されている harness)を使用して算出しました。モデルとエージェントの各ペアについて 5 回ずつ実行し、その平均を報告しています。ベンチマークの詳細は、公式の Terminal Bench website で確認できます。Composer 2 以外のモデルについては、official leaderboard のスコアと、当社インフラ上で実行して記録したスコアのうち、高い方を採用しました。↩
- すべてのモデルの 1 秒あたりのトークン数(TPS)は、2026 年 3 月 18 日時点の Cursor トラフィックのスナップショットに基づいています。Composer と GPT モデルのトークンサイズはほぼ同じです。Anthropic のトークンは約 15% 小さいため、TPS の数値はそれを反映するよう正規化されています。同様に、Anthropic 以外のモデルの出力トークン価格も、同じ約 15% の変化に合わせてスケーリングされています。速度は、プロバイダーの処理能力や時間の経過に伴う改善によって変動する場合があります。↩