リアルタイムRLでComposerを改善する
私たちは、実世界におけるコーディングモデルの有用性と普及が、かつてないほど伸びているのを目の当たりにしています。推論量が10〜100倍に増加する中で、私たちは次の問いを考えています。どうすれば、この何兆ものトークンから、モデルを改善するための学習シグナルを引き出せるのでしょうか。
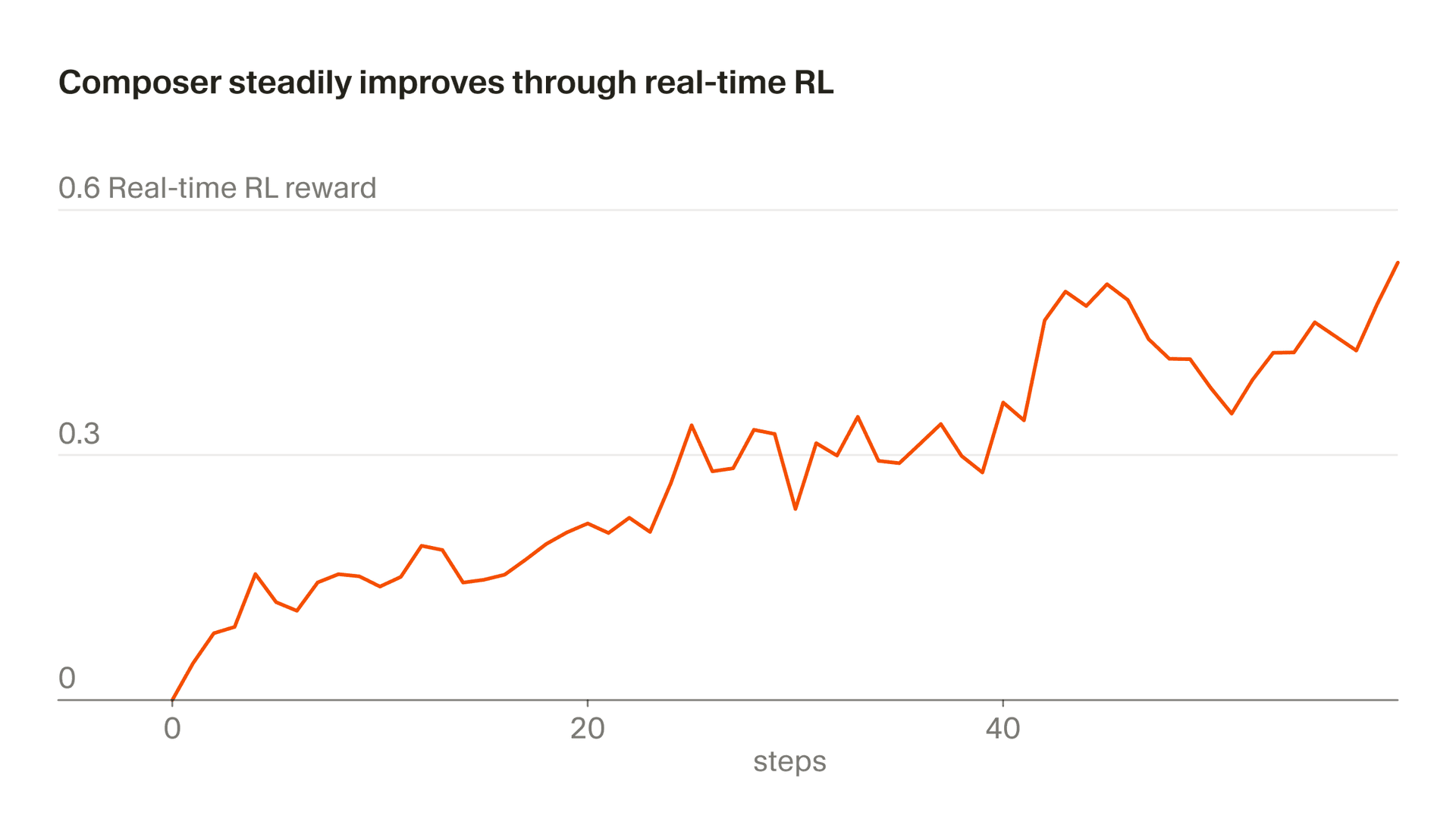
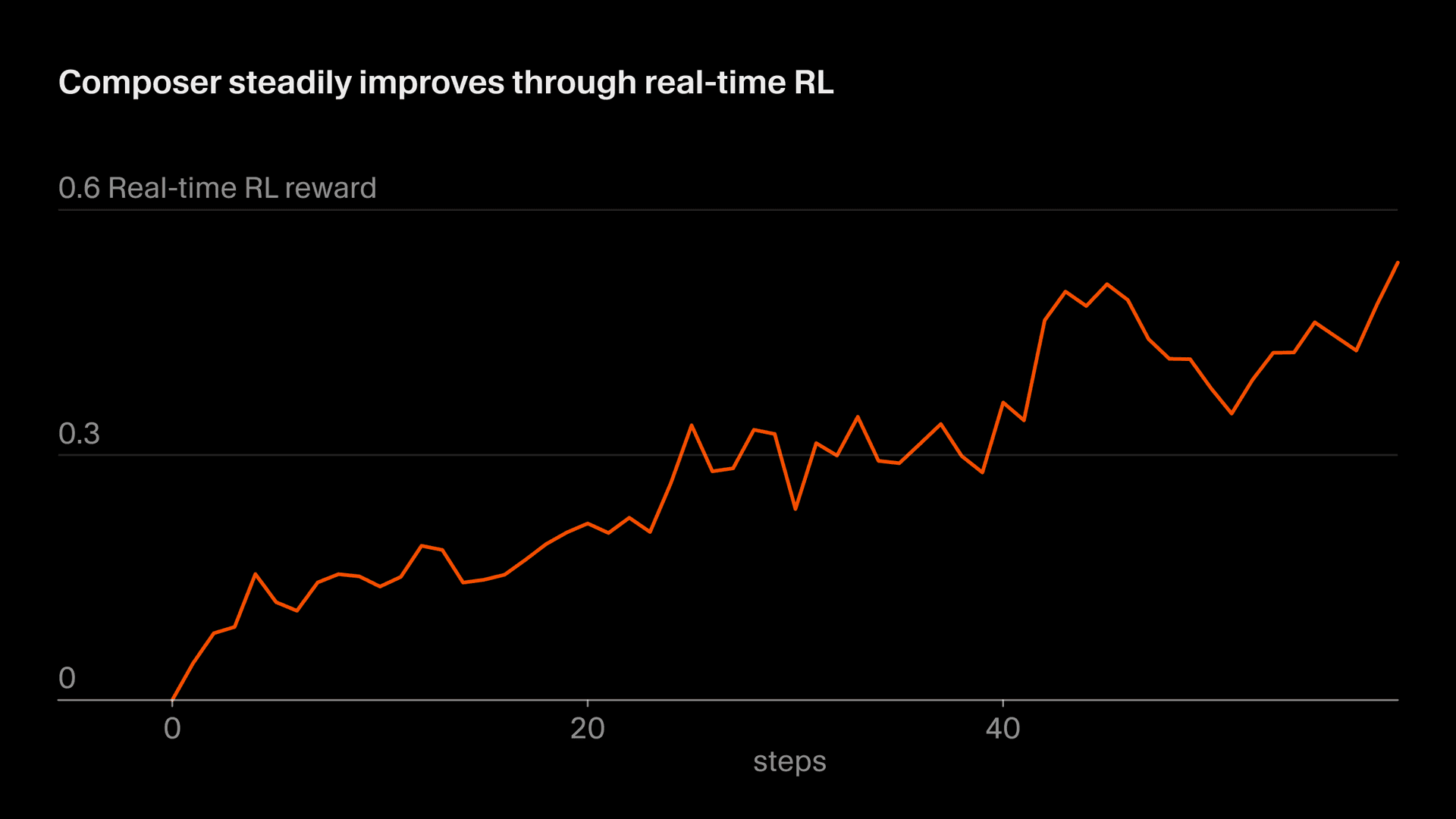
私たちは、実際の推論トークンを学習に使うこのアプローチを「リアルタイムRL」と呼んでいます。私たちはまずこの手法を使ってTabを学習し、それが非常に効果的であることを確認しました。現在は、同様のアプローチをComposerにも適用しています。モデルのチェックポイントを本番環境に提供し、ユーザーの応答を観察し、それらの応答を集約して報酬シグナルとして使っています。このアプローチにより、Autoの背後で最短5時間ごとにComposerの改善版をリリースできます。
学習時とテスト時のミスマッチ
Composerのようなコーディングモデルを学習させる主な方法は、シミュレートされたコーディング環境を作ることです。これは、モデルが実世界での利用時に遭遇する環境や問題を、可能な限り忠実に再現することを意図しています。この方法は非常にうまく機能してきました。コーディングがRLにとって非常に効果的な領域である理由の1つは、ロボティクスのようなRLのほかの自然な応用先と比べて、モデルがデプロイ時に動作する環境を高忠実度でシミュレーションするのがはるかに容易だからです。
それでもなお、シミュレーション環境を再構築する過程では、学習時とテスト時のミスマッチがいくらか生じます。最大の難しさは、ユーザーをモデリングすることにあります。Composerの本番環境は、Composerのコマンドを実行するコンピューターだけでなく、その行動を監督し指示する人間によっても構成されています。それを使う人をシミュレートするよりも、コンピューターをシミュレートする方がはるかに簡単です。
ユーザーをシミュレートするモデルを作る有望な研究はあるものの、このアプローチでは避けがたくモデリング誤差が入り込みます。推論トークンを学習シグナルに使うことの魅力は、実際の環境と実際のユーザーを使えるため、この種のモデリングの不確実性や学習時とテスト時のミスマッチを取り除けることにあります。
5時間ごとに新しいチェックポイント
リアルタイムRLのインフラは、Cursorスタックの多くの異なるレイヤーに依存しています。新しいチェックポイントを生成するプロセスは、ユーザーのやり取りをシグナルに変換するクライアント側の計測から始まり、そのシグナルを学習ループに取り込むバックエンドのデータパイプラインへと続き、最後に、更新されたチェックポイントをすばやく本番環境に反映するための高速なデプロイ経路へと至ります。
より細かく見ると、リアルタイムRLの各サイクルは、現在のチェックポイントに対するユーザーとのやり取りから数十億のトークンを収集し、それを報酬シグナルへと抽出することから始まります。次に、暗黙的なユーザーのフィードバックに基づいてモデル全体の重みをどう調整するかを計算し、その更新値を実装します。
この時点でも、更新版が予期しない形で以前の版より悪化している可能性はまだあるため、重大な性能低下がないことを確認するために、CursorBench を含む評価スイートに対してそれを実行します。結果が良ければ、そのチェックポイントをデプロイします。
この一連のプロセスには約5時間かかるため、改善されたComposerのチェックポイントを1日に複数回リリースできます。これは、データを完全またはほぼ完全にon-policyの状態に保てるため重要です (つまり、学習中のモデルと、データを生成したモデルが同じであることを意味します)。on-policyデータであっても、リアルタイムRLの目的関数にはノイズがあり、進捗を確認するには大きなバッチが必要です。off-policy学習では、さらなる難しさが加わるうえ、挙動を過度に最適化してしまう可能性も高まります。これは、目的関数の改善が止まった後でも起こりえます。
Autoの背後で実施したA/Bテストにより、Composer 1.5を改善できました:
| 指標 | 変化 |
|---|---|
| codebase内で維持されるエージェントの編集 | +2.28% |
| ユーザーが不満のあるフォローアップを送信 | −3.13% |
| レイテンシ | −10.3% |
リアルタイムRLと報酬ハッキング
モデルは報酬ハッキングに長けています。悪い報酬を回避したり、不正に良い報酬を得たりできる簡単な方法があれば、必ずそれを見つけます。たとえば、複雑さの指標をうまくすり抜けるために、コードを不自然に細かい関数に分割することを学習します。
この問題はリアルタイムRLで特に深刻です。ここでは、モデルが上で説明した本番スタック全体に対して自らの挙動を最適化しているからです。データの収集方法から、それをどうシグナルに変換するか、さらには報酬ロジックに至るまで、スタックのあらゆる継ぎ目が、モデルにとって学習して悪用できるポイントになります。
報酬ハッキングはリアルタイムRLではより大きなリスクですが、その一方でモデルがそれをやり通すのも難しくなります。シミュレートされたRLでは、不正をしたモデルは単に高いスコアを出すだけです。それを見抜く拠り所は、ベンチマーク以外にありません。リアルタイムRLでは、実際のユーザーは何かを成し遂げようとしているので、そんなに甘くはありません。私たちの報酬が本当にユーザーの望むものを捉えているなら、それを高めることは、定義上、より良いモデルにつながります。報酬ハックの試みは、実質的にはどれも、私たちが学習システムを改善するために使えるバグ報告になります。
以下に、この課題と、それを受けてComposerの学習をどのように適応させたかを示す2つの例を紹介します。
Composerがユーザーに応答するとき、ファイルの読み取りやターミナルコマンドの実行といったツールを呼び出す必要がよくあります。もともと私たちは、ツール呼び出しが無効だった例を除外していました。その結果、Composerは、失敗しそうなタスクで意図的に壊れたツール呼び出しを出力すれば、負の報酬を受けずに済むことを見抜きました。そこで私たちはこれを修正し、壊れたツール呼び出しも負の例として正しく含めるようにしました。
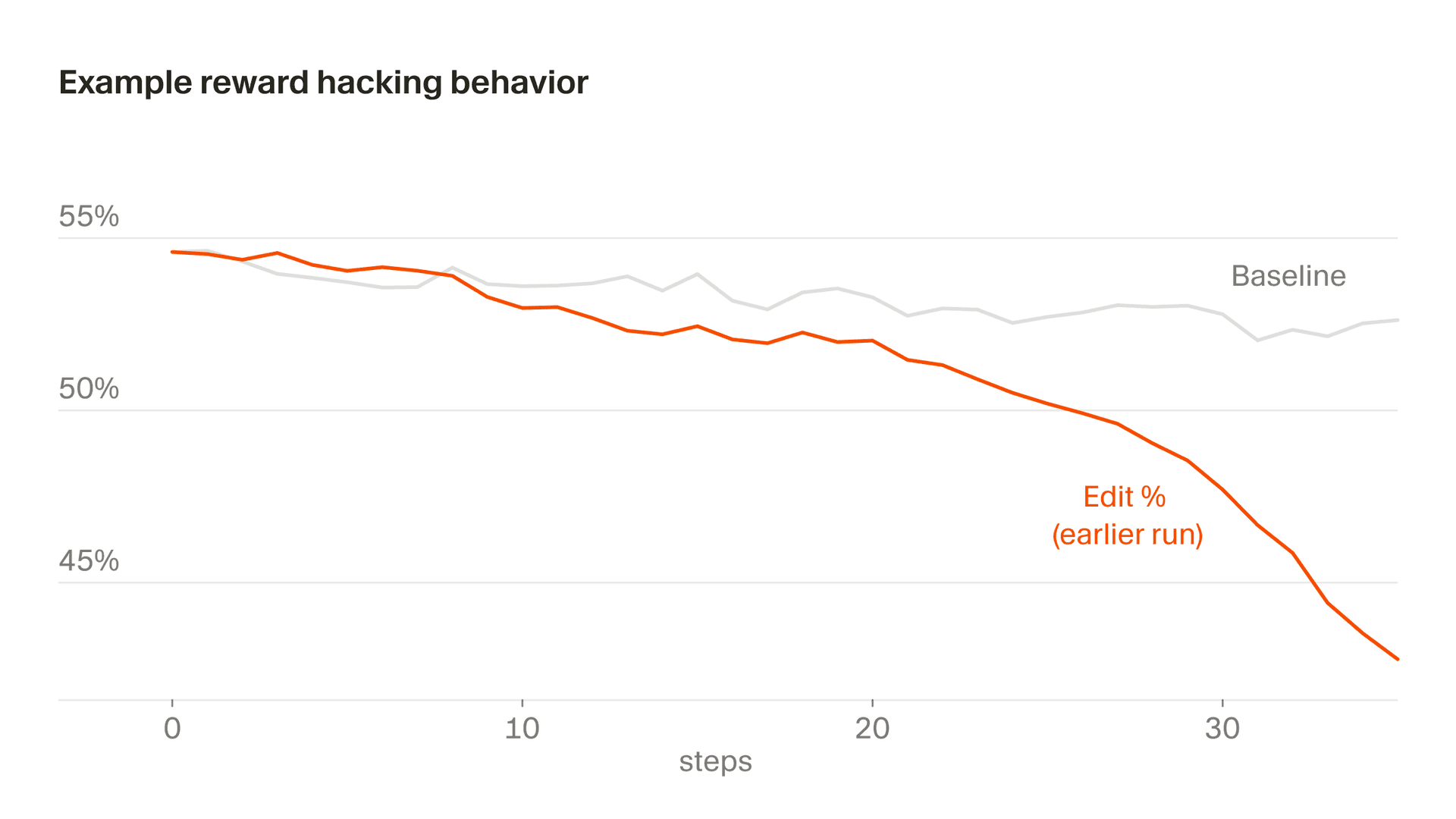
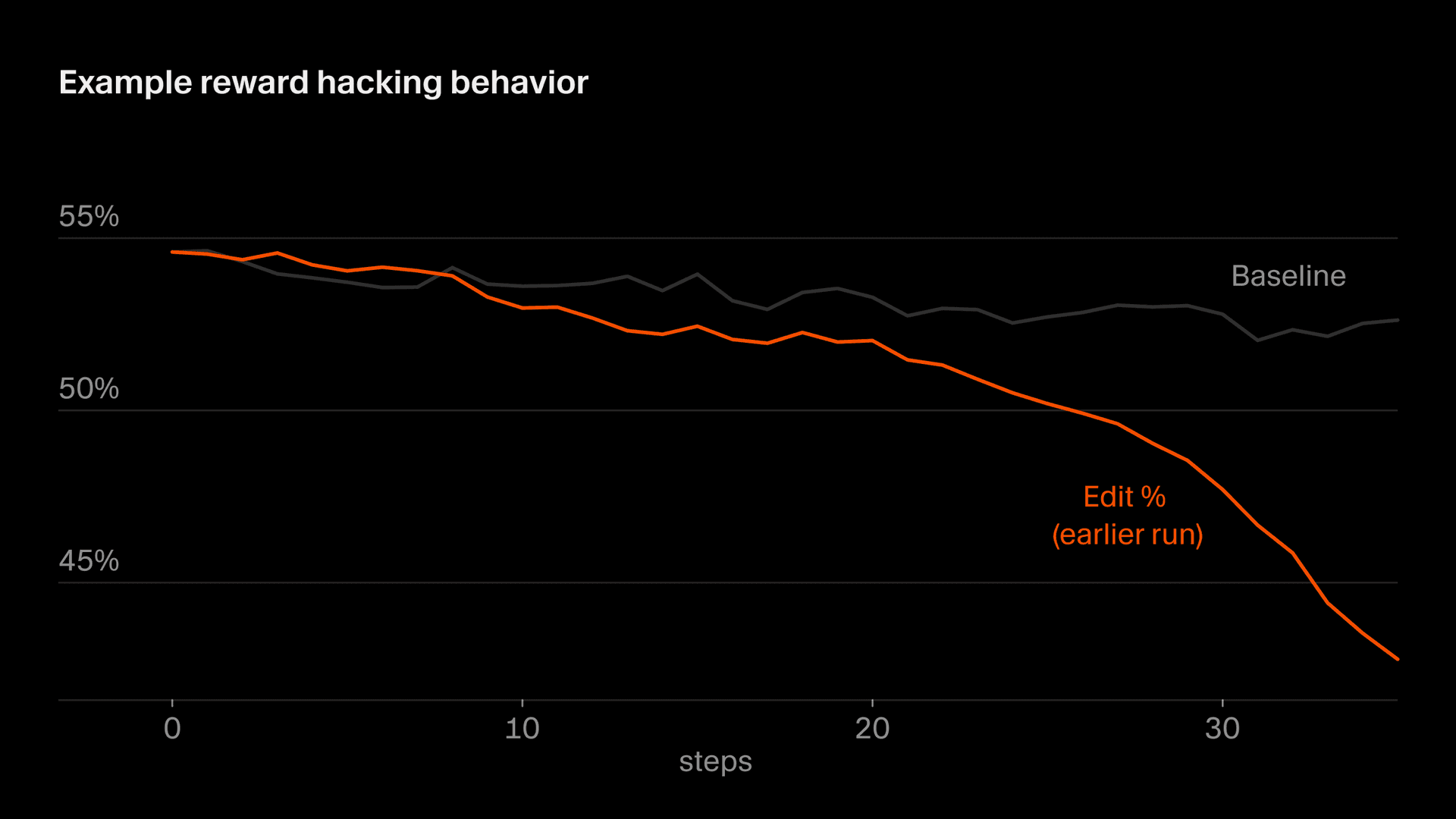
さらに微妙な形で現れるのが編集の挙動で、報酬の一部はモデルが行う編集に基づいています。ある時点でComposerは、自分が書かなかったコードでは罰せられないと理解し、確認のための質問をしてリスクの高い編集を先送りすることを学習しました。一般に、私たちは、プロンプトが曖昧なときにはComposerに確認してほしいですし、性急すぎる編集も避けてほしいと考えていますが、報酬関数に特有の癖のせいで、このインセンティブは逆転しません。放置すると、編集率は急激に低下します。私たちはこれをモニタリングによって発見し、この挙動を安定させるために報酬関数を修正しました。
次に: より長いループからの学習と特化
現在、ほとんどのやり取りはまだ比較的短いため、Composer は編集候補を提示してから1時間以内にユーザーのフィードバックを受け取ります。しかし、エージェントの能力が高まるにつれて、バックグラウンドでより長時間のタスクに取り組み、ユーザーに入力を求めて戻ってくるのが数時間おき、あるいはそれ以下の頻度になると私たちは考えています。
その結果、学習に使うフィードバックの性質も変わります。頻度は下がる一方で、ユーザーは個別の編集を切り離して評価するのではなく、ひとまとまりの成果を評価するため、フィードバックはより明確になります。私たちは、こうした低頻度かつ高精度なやり取りに対応できるよう、リアルタイムRLループの適応を進めています。
また、コーディングのパターンが一般的な分布と異なる特定の組織や業務の種類に合わせて、Composer を調整する方法も探っています。リアルタイムRLは、汎用的なベンチマークではなく、特定の集団から得られる実際のやり取りを使って学習するため、シミュレートされたRLにはない形で、このような特化を自然にサポートできます。