Cursor में हम मॉडल गुणवत्ता की तुलना कैसे करते हैं
नोट: एजेंट क्षमताएँ विकसित होने के साथ CursorBench लगातार अपडेट होता रहता है। वर्तमान उत्पादन संस्करण CursorBench 3.1 है; नवीनतम leaderboard के लिए उस पेज को देखें।
डेवलपर्स अब कोडिंग एजेंट्स से ऐसे लंबे और अधिक जटिल कार्य करने को कह रहे हैं, जो कई फ़ाइलों, उपकरणों और चरणों में फैले होते हैं। जैसे-जैसे इन अनुरोधों का दायरा बढ़ता है, एजेंट के प्रदर्शन को मापने वाले evals को भी उसी के साथ विकसित होना पड़ता है।
Cursor में, हम मॉडल गुणवत्ता की अपनी समझ को डेवलपर्स के वास्तविक काम के अनुरूप बनाए रखने के लिए एक हाइब्रिड online-offline eval प्रक्रिया का उपयोग करते हैं।
offline हिस्सा CursorBench का उपयोग करता है, जो हमारी इंजीनियरिंग टीम के वास्तविक Cursor सेशंस पर आधारित हमारा आंतरिक eval सुइट है। चूँकि कार्य सार्वजनिक रिपॉज़िटरी के बजाय वास्तविक Cursor उपयोग से आते हैं, इसलिए CursorBench मॉडल्स के बीच अंतर पहचानने में बेहतर है और सार्वजनिक बेंचमार्क की तुलना में डेवलपर्स के वास्तविक परिणामों के अधिक अनुरूप है।
हमने CursorBench को एजेंट के प्रदर्शन के कई आयामों को मापने के लिए बनाया है, जिसमें solution correctness, कोड गुणवत्ता, efficiency, और interaction behavior शामिल हैं। यह ब्लॉग solution correctness के नतीजों पर केंद्रित है, लेकिन व्यवहार में हम एजेंट्स का मूल्यांकन इन सभी आयामों पर करते हैं।
अपडेट, मई 2026: इसके बाद हमने CursorBench को अधिक कठिन समस्याओं के साथ 3.1 पर अपडेट किया है। चूँकि समस्या वितरण बदल गया है, CursorBench 3.1 के स्कोर इस पोस्ट के अंकों और चार्ट्स से अलग हो सकते हैं और उनकी तुलना उसी eval version के भीतर की जानी चाहिए।


हम CursorBench को live traffic पर नियंत्रित विश्लेषण के साथ पूरक करते हैं। ये online evals उन रिग्रेशन को पकड़ते हैं जो offline सुइट्स से छूट जाते हैं, जैसे ऐसी स्थितियाँ जहाँ एजेंट का आउटपुट grader को सही लगता है, लेकिन उत्पाद का उपयोग कर रहे डेवलपर को वह कमतर महसूस होता है।
मिलकर, यह online-offline लूप वर्कफ़्लो बदलने पर भी मॉडल गुणवत्ता की हमारी समझ को production से जुड़ा रखता है, और हमें Cursor में सर्वोत्तम संभव एजेंट अनुभव तैयार करने में मदद करता है।
सार्वजनिक बेंचमार्क की सीमाएँ
एक अच्छे benchmark को उन मॉडल्स के बीच फर्क कर पाना चाहिए जो व्यवहार में अलग तरह से प्रदर्शन करते हैं, और साथ ही यह भी दिखाना चाहिए कि डेवलपर्स वास्तव में उन मॉडल्स का अनुभव कैसे करते हैं। सार्वजनिक offline evals इन दोनों ही मामलों में कमजोर पड़ते हैं।
पहली समस्या alignment की है। जैसे-जैसे डेवलपर्स एजेंट्स के साथ अधिक जटिल और विविध काम करते हैं, static या misaligned benchmarks अंततः पूरी तरह गलत चीज़ों को परखने लगते हैं। उदाहरण के लिए, ज़्यादातर SWE benchmarks अभी भी बग ठीक करने वाले कार्यों पर केंद्रित हैं। इसी तरह, Terminal-Bench बोर्ड की किसी स्थिति से सर्वश्रेष्ठ chess move खोजने जैसे व्यापक, puzzle-style tasks पर ज़ोर देता है। हमें लगता है कि ये उन कोडिंग कार्यों के अनुरूप नहीं हैं, जिन्हें डेवलपर्स एजेंट्स से कराना चाहते हैं।
दूसरी समस्या grading की है। कई सार्वजनिक बेंचमार्क tasks यह मानकर चलते हैं कि सही समाधानों का दायरा बहुत सीमित होगा, लेकिन ज़्यादातर डेवलपर अनुरोध इतने कम निर्दिष्ट होते हैं कि उनमें कई वैध तरीके संभव होते हैं। नतीजतन, benchmarks या तो दूसरे सही तरीकों को दंडित करते हैं, या फिर इस अस्पष्टता को हटाने के लिए कृत्रिम requirements जोड़ देते हैं। इनमें से कोई भी वास्तविक प्रदर्शन का सटीक आकलन नहीं देता।
तीसरी समस्या contamination की है। SWE-bench Verified, Pro, और Multilingual सभी सार्वजनिक रिपॉज़िटरी से कार्य लेते हैं, जो अंततः मॉडल के प्रशिक्षण डेटा में पहुँच जाते हैं, जिससे स्कोर बढ़ जाते हैं। OpenAI ने हाल ही में SWE-bench Verified के नतीजों की रिपोर्टिंग पूरी तरह बंद कर दी, क्योंकि उसने पाया कि अत्याधुनिक मॉडल्स memory से gold patches को पुनरुत्पन्न कर सकते थे, और लगभग 60% unsolved समस्याओं में tests त्रुटिपूर्ण थे।
नतीजा यह है कि फ्रंटियर स्तरों पर ये benchmarks अब उन मॉडल्स के बीच फर्क नहीं बता पाते, जिनकी डेवलपर्स के लिए उपयोगिता बहुत अलग होती है।
CursorBench का निर्माण
हम Cursor Blame का इस्तेमाल करके CursorBench के लिए कार्य जुटाते हैं। यह कमिट किए गए कोड को उस एजेंट अनुरोध तक ट्रेस करता है, जिससे वह उत्पन्न हुआ था। इससे हमें डेवलपर के प्रश्न और ग्राउंड-ट्रुथ समाधान की एक स्वाभाविक जोड़ी मिलती है। कई कार्य हमारे आंतरिक कोडबेस और नियंत्रित स्रोतों से आते हैं, जिससे यह जोखिम घटता है कि मॉडल्स ने उन्हें प्रशिक्षण के दौरान पहले ही देखा हो। डेवलपर्स एजेंट्स का उपयोग कैसे करते हैं, इसमें होने वाले बदलावों को ट्रैक करने के लिए हम हर कुछ महीनों में इस सुइट को रीफ़्रेश करते हैं।
हमारे correctness evals में समस्याओं का दायरा शुरुआती संस्करण से मौजूदा संस्करण CursorBench-3 तक, कोड की पंक्तियों और फ़ाइलों की औसत संख्या—दोनों के हिसाब से—लगभग दोगुना हो गया है। CursorBench-3 के कार्यों में SWE-bench Verified, Pro, या Multilingual की तुलना में काफ़ी अधिक कोड पंक्तियाँ शामिल होती हैं। हालांकि कोड की पंक्तियाँ कठिनाई का एक अपूर्ण माप हैं, इस मेट्रिक पर हुई वृद्धि यह दिखाती है कि हमने CursorBench में अधिक चुनौतीपूर्ण कार्य शामिल किए हैं, जैसे मोनोरेपोज़ वाले बहु-कार्यस्थान परिवेशों को संभालना, उत्पादन लॉग्स की जाँच करना, और लंबे समय तक चलने वाले प्रयोग करना।
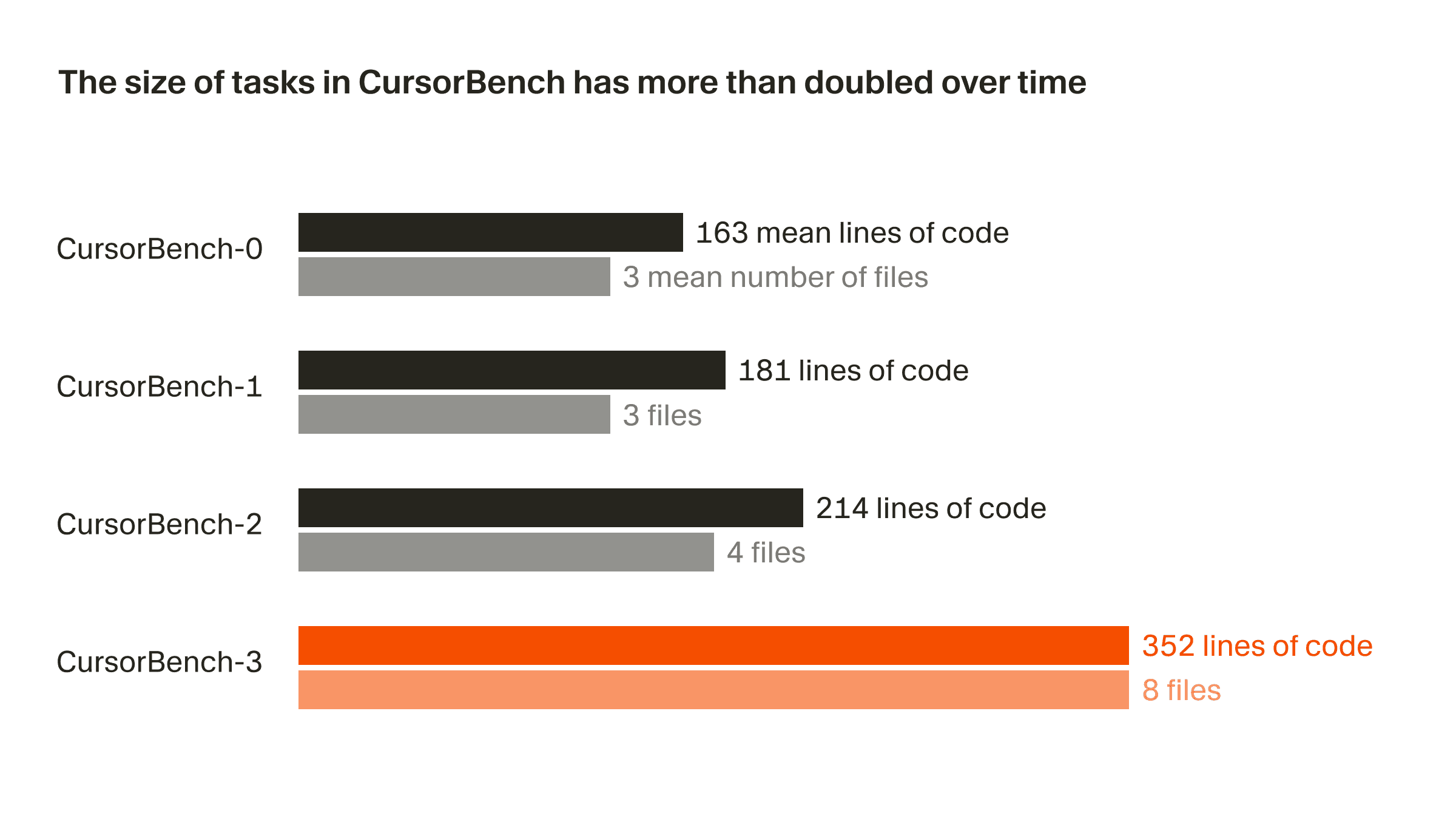
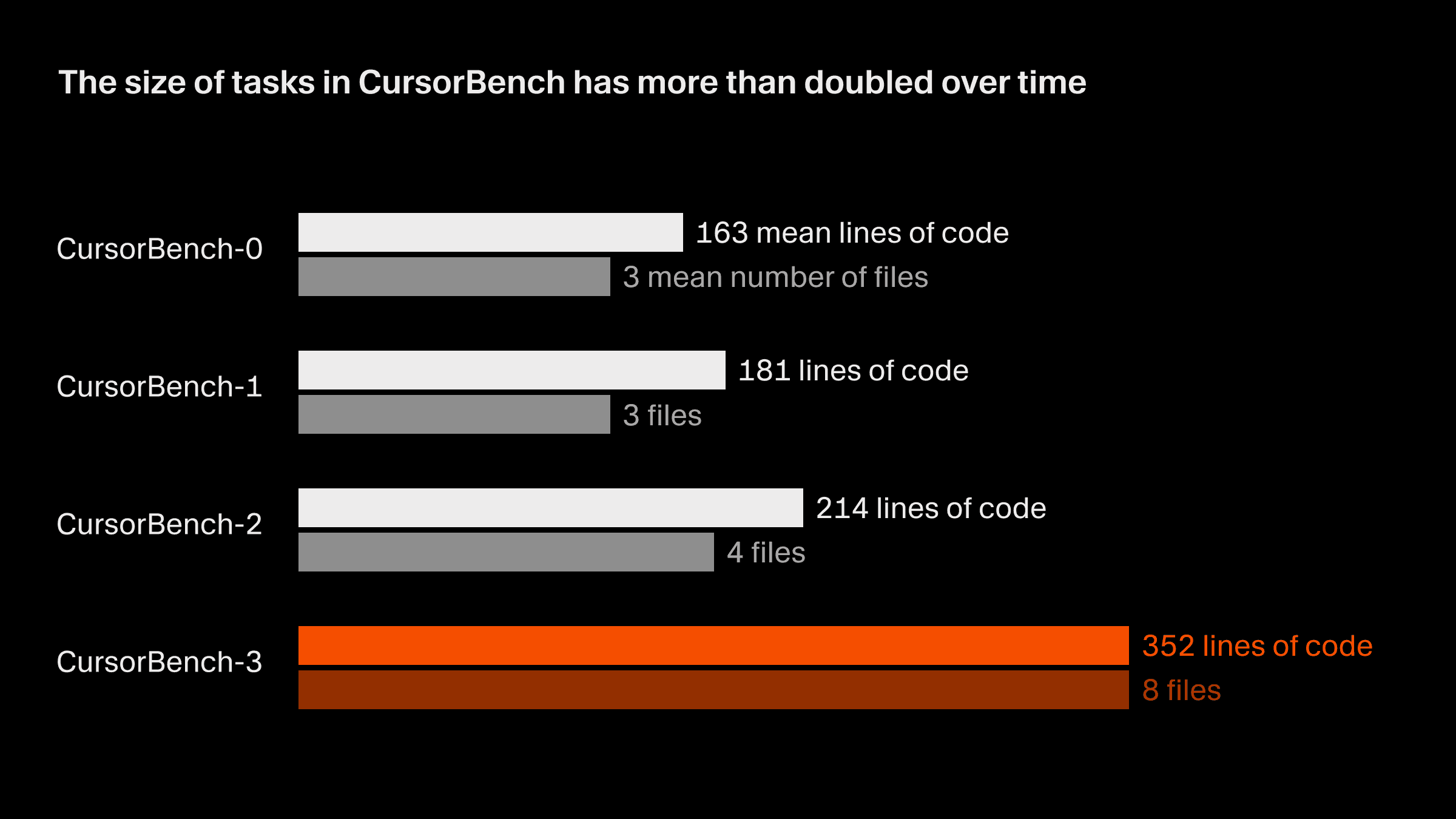
CursorBench के कार्य इस बात से भी मेल खाते हैं कि डेवलपर्स एजेंट्स से अक्सर कम-विशिष्ट और अस्पष्ट तरीके से बात करते हैं। सार्वजनिक benchmarks में इस्तेमाल किए गए विस्तृत GitHub issues के विपरीत, हमारे कार्य-विवरण जानबूझकर छोटे रखे जाते हैं, और हम उन्हें विश्वसनीय रूप से स्कोर करने के लिए एजेंटिक ग्रेडर्स का उपयोग करते हैं।


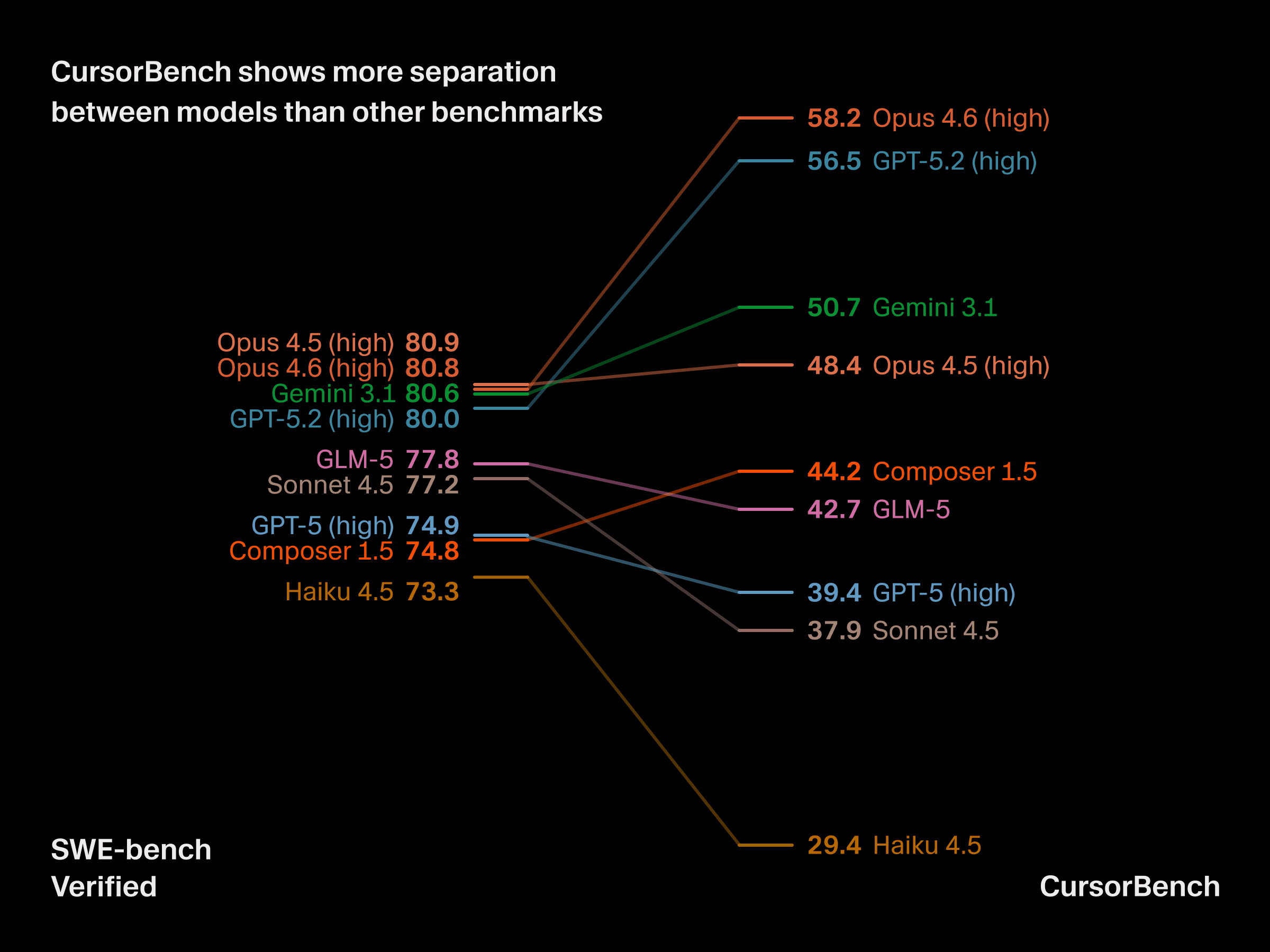
CursorBench मॉडलों के बीच अधिक अंतर दिखाता है
कार्य की जटिलता और विशिष्टताओं में ये अंतर बेंचमार्क की उपयोगिता पर व्यावहारिक असर डालते हैं। CursorBench फ्रंटियर स्तरों पर मॉडलों के बीच अधिक अंतर पैदा करता है, जहाँ सार्वजनिक बेंचमार्क तेज़ी से संतृप्त हो रहे हैं, और कुछ मामलों में Haiku जैसे मॉडल GPT-5 की बराबरी कर सकते हैं या उससे बेहतर प्रदर्शन कर सकते हैं। CursorBench उन मॉडलों के बीच भी भरोसेमंद तरीके se अंतर करता है, जिन्हें डेवलपर्स अनुभव के आधार पर वास्तव में अलग मानते हैं।

CursorBench स्कोर online evals के अनुरूप हैं
Online evaluation यह मापता है कि हमारे एजेंट में किए गए सुधार वास्तव में डेवलपर्स के लिए व्यवहार में मददगार हैं या नहीं। हम एजेंट के नतीजों के कुछ उच्च-स्तरीय प्रॉक्सी ट्रैक करते हैं, जिनमें इंटरैक्शन और आउटपुट गुणवत्ता संकेत दोनों शामिल होते हैं, और किसी एक मेट्रिक पर अनुकूलन करने के बजाय इनमें सुसंगत बदलाव देखते हैं। इन्हें एक साथ देखने से हम उन रिग्रेशन को पकड़ पाते हैं, जहाँ एजेंट का आउटपुट किसी offline grader पर अच्छा स्कोर करता है, लेकिन वास्तव में डेवलपर्स के लिए उतना अच्छा काम नहीं करता।
हम प्रभाव को स्पष्ट रूप से मापने के लिए नियंत्रित online experiments का उपयोग करते हैं। उदाहरण के लिए, सिमैंटिक खोज और पुनर्प्राप्ति पर काम करते समय, हमने एक ablation चलाया, जिसमें सिमैंटिक खोज टूल को पूरी तरह हटा दिया गया। इससे हम ठीक-ठीक पहचान सके कि किन स्थितियों में सिमैंटिक खोज सबसे ज़्यादा मायने रखती है, जैसे बड़े कोडबेस पर रिपॉज़िटरी-आधारित प्रश्न-उत्तर।
CursorBench रैंकिंग इस बात को भी अधिक नज़दीकी से ट्रैक करती है कि डेवलपर्स Cursor में मॉडल गुणवत्ता का अनुभव कैसे करते हैं, जैसा कि हमारे online evaluation मेट्रिक्स से मापा जाता है।


अगला eval सुइट
हालाँकि CursorBench-3 के कार्य सार्वजनिक बेंचमार्क के कार्यों की तुलना में लंबे हैं, फिर भी वे एक ही सत्र में पूरे हो जाते हैं। हमें उम्मीद है कि अगले एक वर्ष में विकास का अधिकांश काम अपने-अपने कंप्यूटरों पर काम करने वाले लंबे समय तक चलने वाले एजेंटों की ओर शिफ्ट हो जाएगा, और हम CursorBench को भी उसी के अनुसार अनुकूलित करने की योजना बना रहे हैं। ऐसा करने के लिए मूल्यांकन की लागत कम करने के तरीके खोजने, बाहरी सेवाओं के साथ इंटरैक्ट करने वाले कार्यों के लिए reproducibility की समस्या सुलझाने, और offline assessment तथा डेवलपर अनुभव के बीच की दूरी कम करने की आवश्यकता होगी।
online-offline लूप हमें वह आधार देता है जिसे हम सही मानते हैं, और जैसे-जैसे हम इस पर आगे काम करेंगे, हम और जानकारी साझा करेंगे।
अगर आप कोडिंग के भविष्य से जुड़ी गहरी तकनीकी समस्याओं पर काम करने में रुचि रखते हैं, तो hiring@cursor.com पर संपर्क करें।