Comment nous comparons la qualité des modèles dans Cursor
Remarque : CursorBench est continuellement mis à jour à mesure que les capacités des agents évoluent. La version actuelle en production est CursorBench 3.1 ; consultez cette page pour voir le dernier classement.
Les développeurs demandent aux agents de codage de prendre en charge des tâches plus longues et plus complexes, impliquant plusieurs fichiers, outils et étapes. À mesure que ces demandes gagnent en ampleur, les évaluations qui mesurent les performances des agents doivent évoluer elles aussi.
Chez Cursor, nous utilisons un processus d’évaluation hybride, en ligne et hors ligne, pour que notre compréhension de la qualité des modèles reste alignée sur ce que font réellement les développeurs.
La partie hors ligne s’appuie sur CursorBench, notre suite d’évaluation interne fondée sur de vraies sessions Cursor de notre équipe d’ingénierie. Comme les tâches proviennent d’une utilisation réelle de Cursor plutôt que de dépôts publics, CursorBench distingue mieux les modèles et reflète davantage les résultats réels des développeurs que les benchmarks publics.
Nous avons conçu CursorBench pour mesurer plusieurs dimensions des performances des agents, notamment la justesse des solutions, la qualité du code, l’efficacité et le comportement en interaction. Cet article de blog se concentre sur les résultats de justesse des solutions, mais en pratique, nous évaluons les agents sur l’ensemble de ces axes.
Mise à jour, mai 2026 : Nous avons depuis mis à jour CursorBench vers la version 3.1 avec des problèmes plus difficiles. Comme la distribution des problèmes a changé, les scores de CursorBench 3.1 peuvent différer des chiffres et graphiques de cet article et doivent être comparés au sein de la même version d’évaluation.


Nous complétons CursorBench par une analyse contrôlée sur le trafic réel. Ces évaluations en ligne détectent des régressions que les suites hors ligne ne repèrent pas, par exemple lorsque la sortie de l’agent semble correcte pour un évaluateur, mais paraît moins satisfaisante à un développeur qui utilise le produit.
Ensemble, cette boucle online-offline nous permet de garder une vision de la qualité des modèles ancrée dans la production à mesure que les workflows évoluent, et de concevoir la meilleure expérience d’agent possible dans Cursor.
Les limites des benchmarks publics
Un bon benchmark doit distinguer des modèles dont les performances diffèrent en pratique, tout en reflétant la manière dont les développeurs les utilisent réellement. Les évaluations publiques hors ligne peinent sur ces deux plans.
Le premier problème est l’alignement. À mesure que les développeurs confient aux agents des tâches de plus en plus complexes et variées, les benchmarks statiques ou mal alignés finissent par évaluer des choses qui n’ont plus grand-chose à voir avec la réalité. La plupart des benchmarks SWE, par exemple, restent centrés sur des tâches de correction de bugs. De même, Terminal-Bench met l’accent sur de grandes tâches de type puzzle, comme trouver le meilleur coup aux échecs à partir d’une position donnée. Nous constatons que ces tâches correspondent mal au travail de codage que les développeurs demandent aux agents d’effectuer.
Le deuxième problème est la notation. De nombreuses tâches de benchmarks publics supposent un ensemble restreint de solutions correctes, mais la plupart des demandes des développeurs sont suffisamment sous-spécifiées pour admettre de nombreuses approches valides. En conséquence, les benchmarks ont tendance soit à pénaliser des approches alternatives pourtant correctes, soit à ajouter des contraintes artificielles pour lever cette sous-spécification. Aucune de ces deux approches ne fournit une mesure fidèle des performances réelles.
Le troisième problème est la contamination. SWE-bench Verified, Pro et Multilingual tirent tous leurs tâches de dépôts publics qui se retrouvent ensuite dans les données d’entraînement des modèles, ce qui gonfle les scores. OpenAI a récemment cessé de publier des résultats pour SWE-bench Verified après avoir constaté que des modèles de pointe pouvaient reproduire de mémoire les correctifs de référence, et que près de 60 % des problèmes non résolus comportaient des tests défectueux.
Il en résulte qu’au niveau des modèles de pointe, ces benchmarks ne permettent plus de distinguer des modèles dont l’utilité pour les développeurs diffère pourtant fortement.
Créer CursorBench
Nous sélectionnons des tâches pour CursorBench à l’aide de Cursor Blame, qui relie le code validé à la demande adressée à l’agent qui l’a produit. Cela nous donne un appariement naturel entre la requête du développeur et la solution de référence. Beaucoup de tâches proviennent de notre base de code interne et de sources contrôlées, ce qui réduit le risque que les modèles les aient déjà vues pendant l’entraînement. Nous actualisons la suite tous les quelques mois afin de suivre l’évolution de la manière dont les développeurs utilisent les agents.
L’ampleur des problèmes dans nos évaluations de correction a globalement doublé entre la version initiale et la version actuelle, CursorBench-3, tant en nombre de lignes de code qu’en nombre moyen de fichiers. Les tâches de CursorBench-3 portent sur un volume de code nettement plus important que celles de SWE-bench Verified, Pro ou Multilingual. Même si le nombre de lignes de code est une mesure imparfaite de la difficulté, la progression de cette métrique reflète la façon dont nous avons intégré des tâches plus complexes dans CursorBench, comme la gestion d’environnements multi-workspace avec des monorepos, l’analyse de journaux de production et l’exécution d’expériences de longue durée.
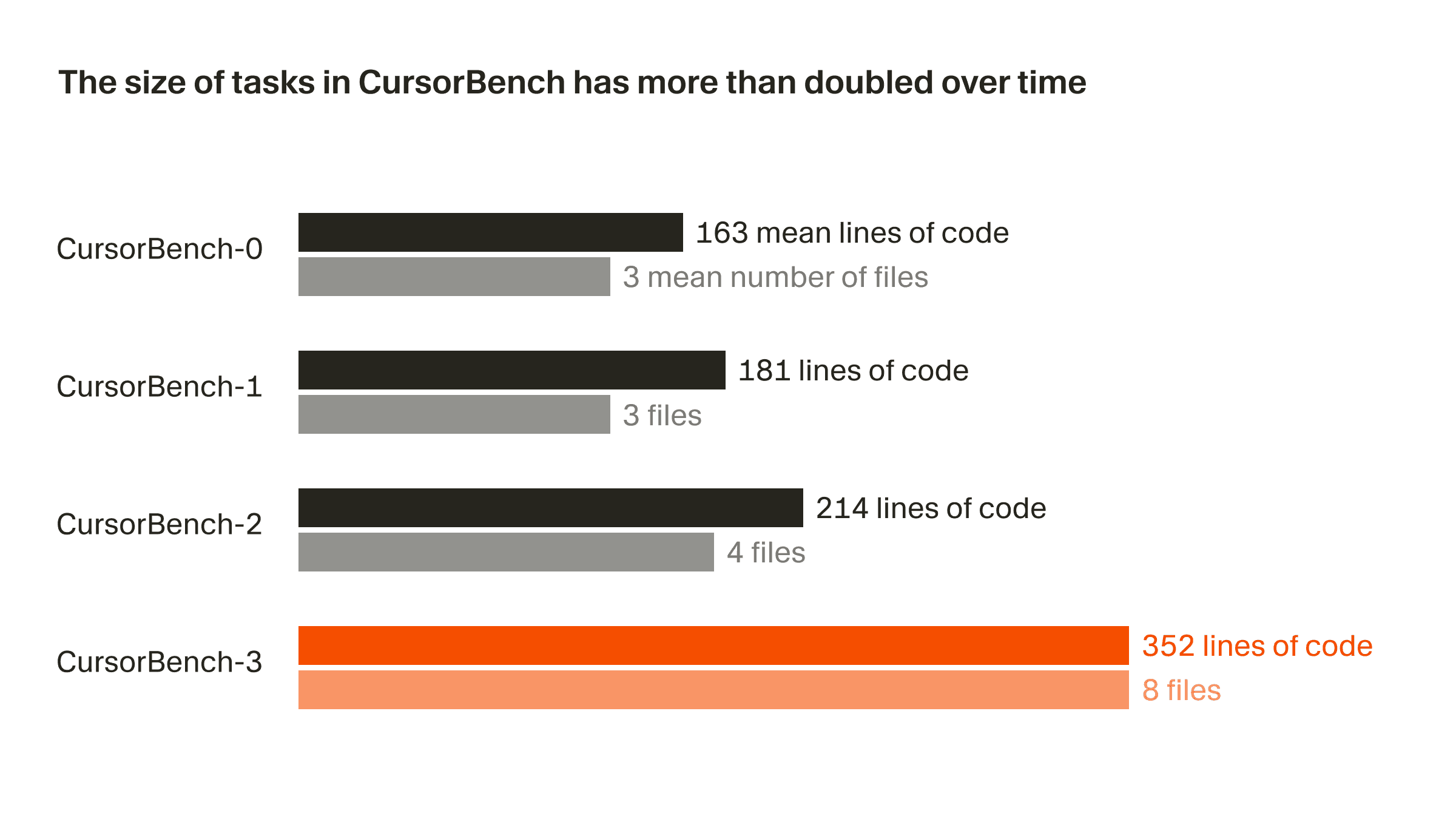
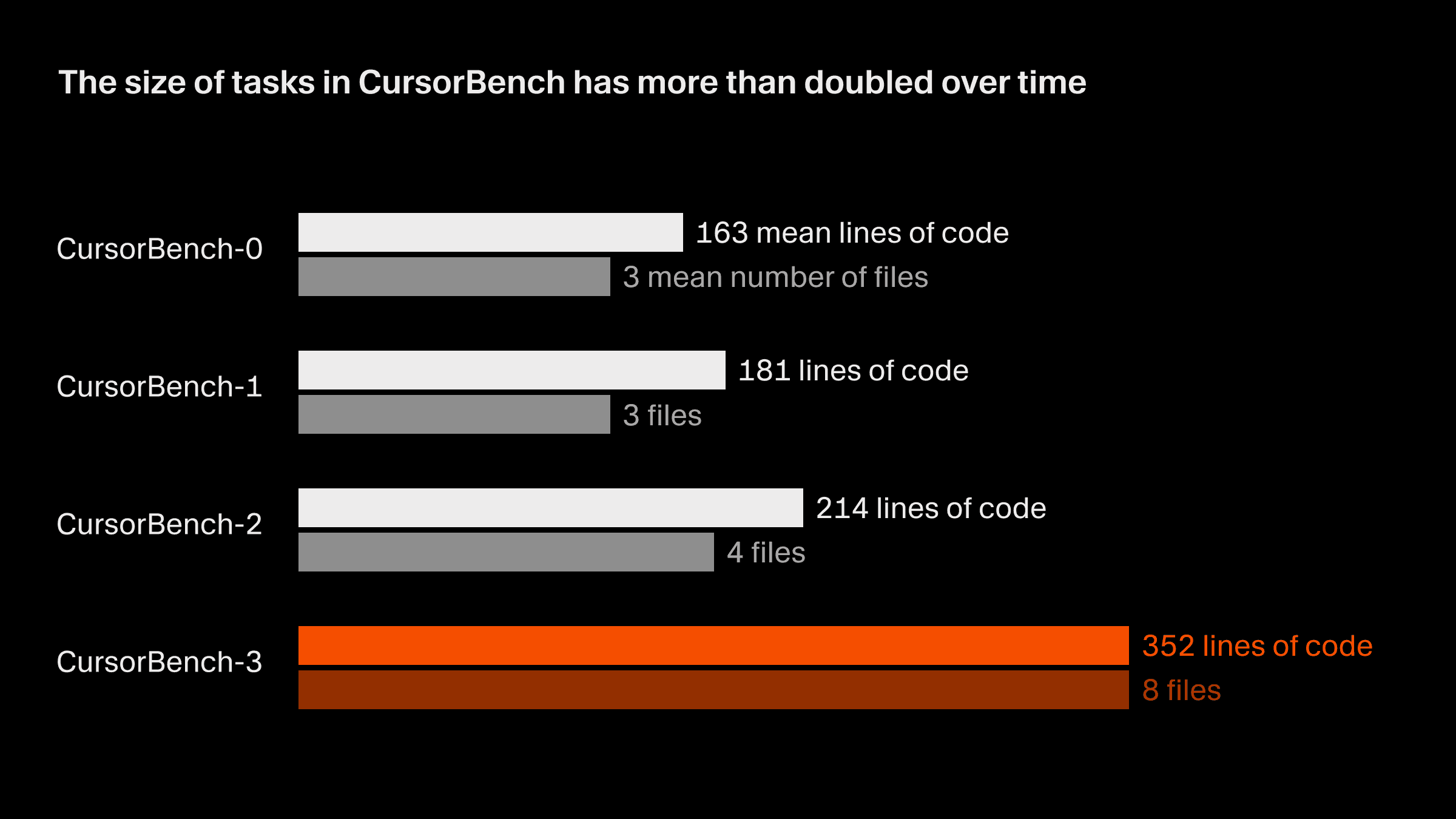
Les tâches de CursorBench reflètent aussi la manière souvent imprécise et ambiguë dont les développeurs s’adressent aux agents. Les descriptions de nos tâches sont volontairement courtes, contrairement aux issues GitHub détaillées utilisées dans les benchmarks publics, et nous utilisons des correcteurs agentiques pour les évaluer de manière fiable.


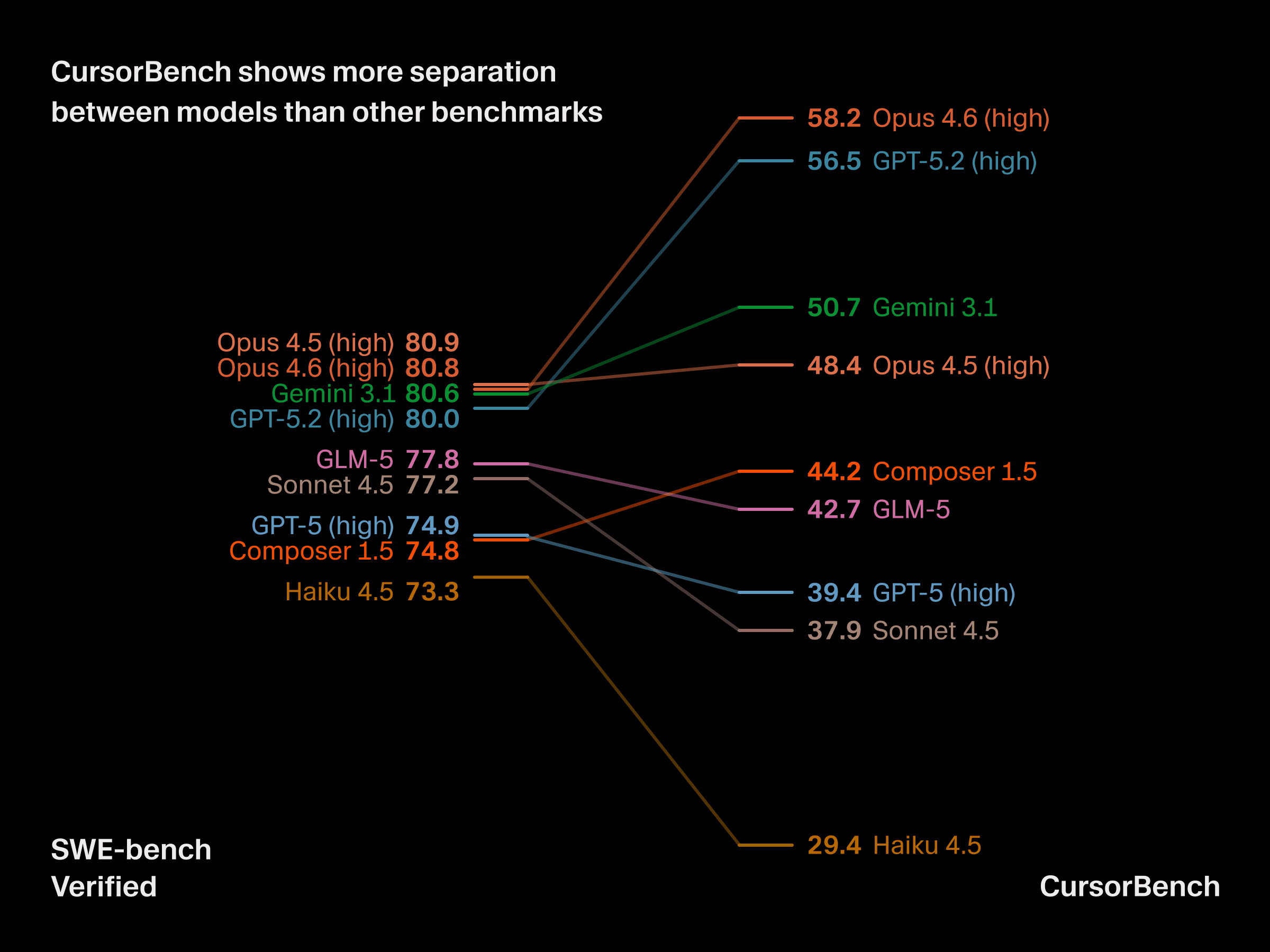
CursorBench met davantage en évidence les écarts entre les modèles
Ces différences de complexité des tâches et de spécification ont des conséquences concrètes sur l’utilité du benchmark. CursorBench met davantage en évidence les écarts entre les modèles de pointe, là où les benchmarks publics sont de plus en plus saturés, et, dans certains cas, des modèles comme Haiku peuvent égaler, voire dépasser, GPT-5. CursorBench distingue de manière fiable des modèles que les développeurs perçoivent comme véritablement différents.

Les scores de CursorBench s’alignent sur les évaluations en ligne
L’évaluation en ligne mesure si les améliorations apportées à notre agent aident réellement les développeurs dans la pratique. Nous suivons un ensemble d’indicateurs indirects de haut niveau des performances de l’agent, couvrant à la fois l’interaction et la qualité des résultats, et nous recherchons des évolutions cohérentes entre eux plutôt que d’optimiser un seul indicateur. Leur agrégation nous permet de détecter des régressions où les résultats de l’agent obtiennent un bon score auprès d’un évaluateur hors ligne, sans pour autant bien fonctionner pour les développeurs.
Nous utilisons des expériences en ligne contrôlées pour isoler l’impact. Par exemple, lors de nos itérations sur la recherche sémantique et la récupération, nous avons mené un test d’ablation en supprimant entièrement l’outil de recherche sémantique. Cela nous a permis d’identifier précisément les scénarios dans lesquels la recherche sémantique comptait le plus, comme la question-réponse fondée sur le dépôt dans des bases de code de grande taille.
Les classements de CursorBench suivent aussi plus étroitement la façon dont les développeurs perçoivent la qualité des modèles dans Cursor, telle qu’elle est mesurée par nos métriques d’évaluation en ligne.


La prochaine suite d’évaluation
Bien que les tâches de CursorBench-3 soient plus longues que celles des benchmarks publics, elles se bouclent encore en une seule session. Nous prévoyons qu’au cours de l’année à venir, la grande majorité du travail de développement basculera vers des agents de longue durée s’exécutant sur leurs propres machines, et nous comptons adapter CursorBench en conséquence. Cela nécessitera de trouver des moyens de réduire le coût de l’évaluation, d’assurer la reproductibilité des tâches qui interagissent avec des services externes et de combler l’écart entre l’évaluation hors ligne et l’expérience des développeurs.
La boucle online-offline nous semble constituer la bonne base, et nous prévoyons d’en dire plus à mesure que nous la développerons.
Si vous souhaitez travailler sur des problèmes techniques complexes liés à l’avenir du codage, contactez-nous à hiring@cursor.com.