Iterar con shadow workspaces
Esta es una receta segura para el fracaso: pega unos cuantos archivos relevantes en un Google Doc, envía el enlace a tu ingeniero de software p60 favorito, que no sabe nada de tu codebase, y pídele que implemente completa y correctamente tu próxima PR dentro del doc.
Si le pides a una IA que haga lo mismo, también fallará, como era de esperar.
Ahora, si en cambio les das acceso remoto a tu entorno de desarrollo, con la capacidad de ver lints, ir a definiciones y ejecutar código, ya puedes esperar que sean bastante más útiles.
Creemos que una de las cosas que permitirá que las IA escriban más de tu código es la capacidad de iterar en tu entorno de desarrollo. Pero dejar ingenuamente que las IA se suelten en tu carpeta acaba en caos: imagina escribir una función que requiere mucho razonamiento solo para que una IA la sobrescriba, o intentar ejecutar tu programa solo para que una IA inserte código que no compila. Para ser realmente útil, la iteración de la IA tiene que ocurrir en segundo plano, sin afectar tu experiencia al programar.
Para lograr esto, implementamos lo que llamamos el shadow workspace (espacio de trabajo en sombra) en Cursor. En esta entrada de blog, primero expondré nuestros criterios de diseño y luego describiré la implementación que existe en Cursor en el momento de escribir esto (una ventana oculta de Electron) y hacia dónde queremos llevarla en el futuro (un proxy de carpetas a nivel de kernel).

Criterios de diseño
Queremos que el espacio de trabajo en sombra cumpla los siguientes objetivos:
-
Usabilidad del LSP: las IA deberían ver los lints de sus cambios, poder ir a las definiciones y, en general, poder interactuar con todas las partes del language server protocol (LSP).
-
Ejecución: las IA deberían poder ejecutar su código y ver el resultado.
Inicialmente nos enfocamos en la usabilidad del LSP.
Los objetivos deben cumplirse sujetos a los siguientes requisitos:
-
Independencia: la experiencia de programación del usuario no debe verse afectada.
-
Privacidad: el código del usuario debe estar seguro (por ejemplo, manteniéndolo todo local).
-
Concurrencia: varias IA deberían poder hacer su trabajo de forma concurrente.
-
Universalidad: debería funcionar para todos los lenguajes y todas las configuraciones de espacios de trabajo.
-
Mantenibilidad: debería estar escrito con la menor cantidad de código posible y con el código lo más aislado posible.
-
Velocidad: no debería haber retrasos de minutos en ningún punto, y debería haber suficiente capacidad para cientos de ramas de IA.
Muchos de estos criterios reflejan la realidad de crear un editor de código para más de cien mil usuarios. Realmente no queremos afectar negativamente la experiencia de programación de nadie.
Lograr la usabilidad con LSP
Permitir que las IA reciban lints sobre sus ediciones es una de las formas más impactantes de mejorar el rendimiento de generación de código cuando se mantiene fijo el modelo de lenguaje subyacente. Los lints no solo permiten pasar de un 90% de código funcional a un 100% de código funcional, sino que también son muy útiles en situaciones con contexto limitado, cuando la IA puede necesitar hacer una conjetura fundamentada sobre qué método o servicio llamar en el primer intento. Los lints pueden ayudar a identificar lugares donde la IA necesita pedir más información.

La usabilidad con LSP también es más sencilla que la capacidad de ejecución, porque casi todos los servidores de lenguaje pueden operar sobre archivos que no se han guardado en el sistema de archivos (y como veremos más adelante, involucrar el sistema de archivos hace las cosas bastante más difíciles). Así que empecemos aquí. En el espíritu de nuestro quinto requisito, la mantenibilidad, primero probamos las soluciones más simples posibles.
Las soluciones simples que no funcionan
Que Cursor sea un fork de VS Code significa que ya tenemos acceso muy fácil a los language servers. En VS Code, cada archivo abierto está representado por un objeto TextModel, que almacena en memoria el estado actual del archivo. Los language servers leen de estos objetos TextModel en lugar de leer del disco, lo que les permite ofrecer autocompletado y lints mientras escribes (en lugar de solo cuando guardas).
Supongamos que una IA realiza un cambio en el archivo lib.ts. Obviamente no podemos modificar el objeto TextModel existente correspondiente a lib.ts, porque el usuario podría estar editándolo al mismo tiempo. No obstante, una idea que suena plausible es crear una copia del objeto TextModel, desvincular la copia de cualquier archivo real en disco y permitir que la IA edite y obtenga lints a partir de ese objeto. Esto se podría lograr con las siguientes 6 líneas de código.
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// crear el TextModel copiado en memoria y aplicarle la edición de IA
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// esperar 2 segundos para que los servidores de lenguaje procesen el nuevo objeto TextModel
await new Promise((resolve) => setTimeout(resolve, 2000));
// leer los lints del servicio de marcadores, que internamente redirige a la extensión correcta según el lenguaje
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}Esta solución es claramente destacada en cuanto a mantenibilidad. También es muy buena en cuanto a su carácter universal, porque la mayoría de la gente ya habrá instalado y configurado las extensiones específicas del lenguaje adecuadas para su proyecto. La concurrencia y la privacidad se satisfacen de forma trivial.
El problema es la independencia. Aunque al hacer una copia de TextModel conseguimos no modificar directamente el archivo que el usuario está editando, seguimos informando al servidor de lenguaje, el mismo servidor de lenguaje que está usando el usuario, de la existencia de nuestro archivo copiado. Esto provoca problemas: los resultados de “go to references” incluirán nuestro archivo copiado; lenguajes como Go, que tienen un ámbito de espacio de nombres predeterminado que abarca varios archivos, se quejarán de declaraciones duplicadas para todas las funciones tanto en el archivo copiado como en el archivo original que el usuario pueda estar editando; y lenguajes como Rust, donde los archivos solo se incluyen si se importan explícitamente en otro sitio, no te mostrarán ningún error. Probablemente haya muchos más problemas de este estilo.
Puede parecer que estos problemas son menores, pero la independencia es absolutamente fundamental para nosotros. Si degradamos aunque sea ligeramente la experiencia normal de edición de código, no importará lo buenas que sean nuestras funciones de IA: la gente, yo incluido, simplemente no usaría Cursor.
También consideramos algunas otras ideas que acabaron fallando: lanzar nuestras propias instancias de tsc o gopls o rust-analyzer fuera de la infraestructura de VS Code, duplicar el proceso host de extensiones donde se ejecutan todas las extensiones de VS Code para poder ejecutar dos copias de cada extensión de servidor de lenguaje, y hacer un fork de todos los servidores de lenguaje populares para que admitan múltiples versiones diferentes de archivos y luego empaquetar esas extensiones dentro de Cursor.
La implementación actual del espacio de trabajo sombra
Acabamos implementando el espacio de trabajo sombra como una ventana oculta: cada vez que una IA quiere ver los lints del código que escribió, generamos una ventana oculta para el espacio de trabajo actual y hacemos la edición en esa ventana en su lugar, para luego devolver los lints. Reutilizamos la ventana oculta entre solicitudes. Esto nos da (casi*) plena compatibilidad con LSP mientras satisfacemos todos los requisitos (casi*) por completo. Los asteriscos se abordan más adelante.
En la Figura 4 se muestra un diagrama de arquitectura simplificado.
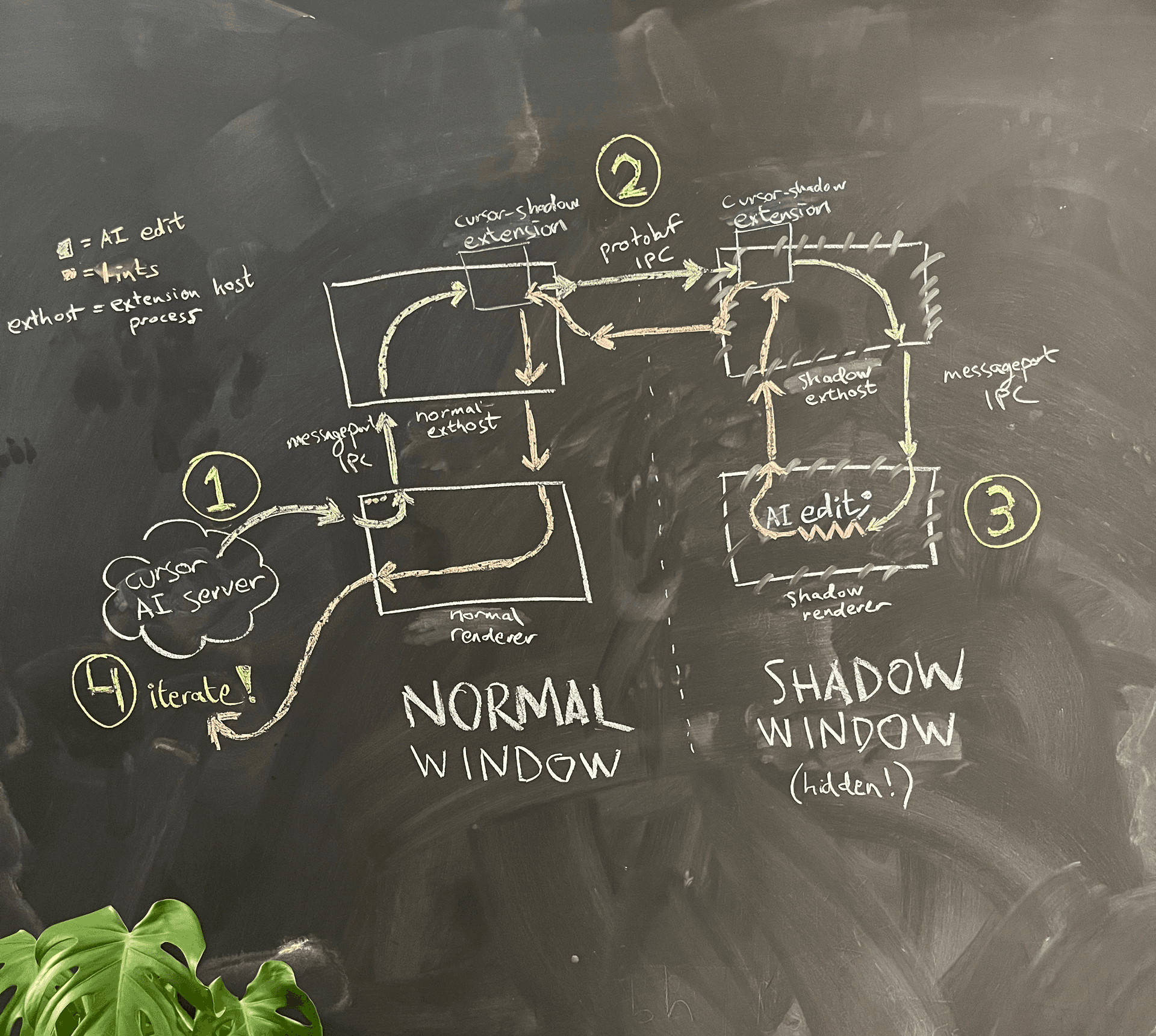
La IA se ejecuta en el proceso de renderizado de la ventana normal. Cuando quiere ver los lints del código que escribió, el proceso de renderizado le pide al proceso principal que genere una ventana sombra oculta en la misma carpeta.
Debido al sandboxing de Electron, los dos procesos de renderizado no pueden comunicarse directamente entre sí. Una opción que consideramos fue reutilizar la lógica cuidadosa de creación de message ports que VS Code implementó para permitir que el proceso de renderizado se comunique con el proceso extension host, y usarla para crear nuestro propio IPC de message port entre la ventana normal y la ventana sombra. Recelosos de la carga de mantenimiento, optamos por un truco: reutilizamos el IPC de message port existente desde el proceso de renderizado al extension host y luego nos comunicamos de extension host a extension host usando una conexión IPC independiente. Allí también colamos una mejora de calidad de vida: ahora podíamos usar gRPC y buf (que nos encanta) para comunicarnos, en lugar de la lógica personalizada de serialización JSON de VS Code, algo frágil.
Esta configuración es, de entrada, bastante fácil de mantener, ya que el código añadido es independiente del resto del código, y el código central requerido para ocultar la ventana es solo una línea (cuando abres una ventana en Electron, puedes proporcionar el parámetro show: false para ocultarla). Satisface de forma trivial la universalidad y la privacidad.
Afortunadamente, ¡la independencia también se cumple! La ventana nueva es completamente independiente del usuario, así que las IA pueden hacer libremente cualquier cambio que quieran y obtener los lints correspondientes. El usuario no notará nada.
Hay una preocupación con la ventana sombra: la nueva ventana, de forma directa, conlleva un aumento de 2x en el uso de memoria. Reducimos el impacto de esto limitando las extensiones que pueden ejecutarse en la ventana sombra, matándola automáticamente tras 15 minutos de inactividad y asegurándonos de que sea opcional. Aun así, plantea un desafío para la concurrencia: no podemos simplemente generar una nueva ventana sombra para cada IA. Por suerte, aquí podemos aprovechar uno de los factores clave que distinguen a las IA de los humanos: las IA pueden ser pausadas por un tiempo indefinido sin siquiera notarlo. En particular, si tienes dos IA, A y B, que proponen ediciones A1 seguida de A2 y B1 seguida de B2, respectivamente, puedes entrelazar esas ediciones. La ventana sombra primero restablece todo el estado de la carpeta a A1, obtiene los lints y se los devuelve a A. Luego restablece todo el estado de la carpeta a B1, obtiene los lints y se los devuelve a B. Y así sucesivamente con A2 y B2. En este sentido, las IA se parecen más a los procesos de computadora (que también se entrelazan así por la CPU sin darse cuenta) que a los humanos (que tienen un sentido intrínseco del tiempo).
Tomado todo esto en conjunto, obtenemos una API Protobuf sencilla que nuestras IA en segundo plano pueden usar para refinar sus ediciones, sin afectar en absoluto al usuario.
Los asteriscos prometidos: Algunos servidores de lenguaje dependen de que el código se escriba en disco antes de informar los lints. El ejemplo principal es el servidor de lenguaje rust-analyzer, que simplemente ejecuta un cargo check a nivel de proyecto para obtener los lints y no se integra con el sistema de archivos virtual de VS Code (consulta este issue como referencia). Por lo tanto, el shadow workspace todavía no es compatible con LSP para Rust, a menos que el usuario esté usando la extensión obsoleta RLS.
Lograr la capacidad de ejecución
La capacidad de ejecución es donde las cosas se vuelven a la vez interesantes y complicadas. Actualmente nos estamos centrando en IA de horizonte temporal corto para Cursor — por ejemplo, implementar funciones por ti en segundo plano mientras las usas, en lugar de implementar PRs completas — así que todavía no hemos implementado la capacidad de ejecución. No obstante, es interesante pensar cómo lograrla.
Ejecutar código requiere guardarlo en el sistema de archivos. Muchos proyectos también tendrán efectos secundarios en disco (piensa en cachés de compilación y archivos de registro). Por lo tanto, ya no podemos lanzar la ventana sombra en la misma carpeta que el usuario. Para una capacidad de ejecución perfecta de todos los proyectos, también necesitamos aislamiento a nivel de red, pero por ahora vamos a centrarnos en lograr el aislamiento a nivel de disco.
La idea más simple: cp -r
La idea más simple es copiar de forma recursiva la carpeta del usuario a una ubicación en /tmp, y luego aplicar las ediciones de la IA, guardar los archivos y ejecutar el código allí. Para la siguiente edición por otra IA, haríamos un rm -rf seguido de una nueva llamada a cp -r, para asegurarnos de que el espacio de trabajo sombra se mantenga sincronizado con el espacio de trabajo del usuario.
El problema es la velocidad: cp -r es muy lento. Lo importante que hay que recordar es que, para poder ejecutar un proyecto, no solo necesitamos copiar el código fuente, sino también todos los archivos auxiliares relacionados con el proceso de compilación. Concretamente, necesitamos copiar los node_modules en proyectos de JavaScript, el venv en proyectos de Python y el target en proyectos de Rust. Estas suelen ser carpetas enormes, incluso para proyectos de tamaño medio, lo que marca el fin del enfoque ingenuo de cp -r.
Symlinks, hardlinks, copy-on-writes
Copiar y crear estructuras de carpetas grandes no tiene por qué ser superlento. Un ejemplo de que es posible es bun, que a menudo tarda menos de un segundo en instalar dependencias en caché dentro de node_modules. En Linux usan hardlinks, que son rápidos porque no hay movimiento real de datos. En macOS usan la syscall clonefile, que es una incorporación relativamente reciente y realiza un copy-on-write de un archivo o carpeta.
Por desgracia, para nuestro monorepo de tamaño moderado, incluso un clon con cp -c tarda 45 segundos en finalizar. Esto es demasiado lento para ejecutarse antes de cada solicitud de shadow workspace. Los hardlinks dan miedo porque cualquier cosa que ejecutes en la carpeta shadow puede modificar accidentalmente los archivos reales del repositorio original. Con los symlinks pasa algo parecido y, además, tienen el problema adicional de que no se tratan de forma transparente, lo que significa que a menudo requieren configuración adicional (por ejemplo, la opción --preserve-symlinks de Node.js).
Se podría imaginar que clonefile (o incluso un simple cp -r) funcionara si se combinara con algún mecanismo ingenioso de seguimiento para evitar tener que volver a copiar la carpeta antes de cada solicitud. Para garantizar la corrección, tendríamos que monitorizar todos los cambios de archivos en la carpeta del usuario desde la última copia completa, y todos los cambios de archivos en la carpeta copiada, y antes de cada solicitud deshacer los segundos y reproducir los primeros. Siempre que el historial de cambios en cualquiera de los lados se vuelva demasiado grande como para hacerle seguimiento, podríamos hacer una nueva copia completa y restablecer el estado. Esto podría funcionar, pero parece propenso a errores, frágil y, francamente, un poco feo para conseguir algo que suena tan sencillo.
Lo que realmente queremos: un proxy de carpeta a nivel de kernel
Lo que realmente queremos es sencillo: queremos que una carpeta sombra A′ parezca idéntica a la carpeta A del usuario para todas las aplicaciones que usan las API habituales del sistema de archivos, con la capacidad de configurar rápidamente un pequeño conjunto de archivos de reemplazo, cuyos contenidos se leen desde la memoria en lugar del disco. También queremos que cualquier escritura en la carpeta A′ se guarde en el almacén en memoria de reemplazos en lugar de en el disco. En resumen, queremos una carpeta proxy con reemplazos configurables, y estamos conformes con mantener la tabla de reemplazos completamente en memoria. Luego podemos lanzar nuestra ventana sombra dentro de esta carpeta proxy y lograr una independencia perfecta a nivel de disco.
Es crucial que tengamos soporte a nivel de kernel para el proxy de carpeta, de modo que cualquier código en ejecución pueda seguir llamando a las llamadas al sistema (read y write) sin ningún cambio. Un enfoque es crear una extensión del kernel 13 que se registre a sí misma como backend de la carpeta sombra en el sistema de archivos virtual del kernel y que implemente el comportamiento sencillo descrito arriba.
En Linux podemos hacer esto a nivel de usuario, con FUSE (“Filesystem in Userspace”). FUSE es un módulo del kernel que ya existe de forma predeterminada en la mayoría de las distribuciones de Linux y redirige las llamadas al sistema de archivos a un proceso en espacio de usuario. Esto hace que implementar el proxy de carpeta sea aún más sencillo. Una implementación mínima de ejemplo del proxy de carpeta podría verse como lo siguiente, aquí presentada en C++.
Primero, importamos la biblioteca FUSE de espacio de usuario, que es responsable de comunicarse con el módulo FUSE del kernel. También definimos la carpeta objetivo (la carpeta del usuario) y el mapa en memoria de los reemplazos.
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// otras inclusiones...
using namespace std;
// la carpeta proxy que no queremos modificar
string target_folder = "/path/to/target/folder";
// las sobreescrituras en memoria que se aplicarán
unordered_map<string, vector<char>> overrides;Luego definimos nuestra función personalizada read para comprobar si los overrides incluyen la ruta y, si no, simplemente leer desde la carpeta de destino.
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// verificar si la ruta está en los overrides
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// si es así, devolver el contenido del override
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// de lo contrario, abrir y leer el archivo desde la carpeta proxy
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}Nuestra función write personalizada simplemente escribe en el mapa de overrides.
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// siempre escribir en las sobreescrituras
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}Por último, registramos nuestras funciones personalizadas en FUSE.
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}Una implementación real tendría que implementar toda la API de FUSE, incluyendo readdir, getattr y lock, pero las funciones serían muy similares a las anteriores. Para cada nueva solicitud de lints, podemos simplemente restablecer el mapa de overrides para que contenga solo las ediciones de esa IA específica, lo cual es instantáneo. Si quisiéramos garantizar que no haya un crecimiento descontrolado de memoria, también podríamos mantener el mapa de overrides en disco (con algo de trabajo extra de gestión).
Con un control perfecto sobre el entorno, probablemente querríamos implementar esto como un módulo nativo del kernel, para evitar la sobrecarga de los cambios de contexto adicionales entre espacio de usuario y kernel de FUSE. 14
...Pero: jardines amurallados
En Linux, el proxy de carpeta FUSE funciona muy bien, pero la mayoría de nuestros usuarios usan macOS o Windows, ninguno de los cuales tiene una implementación de FUSE integrada. Lamentablemente, distribuir una extensión de kernel también está descartado: en las Mac con Apple Silicon, la única manera de que un usuario instale una extensión de kernel es reiniciar el equipo mientras mantiene presionada una tecla especial para entrar en modo de recuperación y luego reducir el nivel de seguridad a “Seguridad reducida”. ¡Imposible de distribuir!
Dado que FUSE necesita ejecutarse parcialmente dentro del kernel, implementaciones FUSE de terceros como macFUSE sufren del mismo problema: es prácticamente imposible conseguir que los usuarios lo instalen.
Ha habido intentos de ser creativos para esquivar esta restricción. Un enfoque es tomar un sistema de archivos basado en red que macOS sí admite de forma nativa (p. ej., NFS o SMB) y poner una API de FUSE por debajo. Existe un servidor local de prueba de concepto de código abierto con una API tipo FUSE construida sobre NFS alojado en xetdata/nfsserve, y el proyecto de código cerrado macOS-FUSE-t admite backends construidos tanto sobre NFS como sobre SMB.
¿Problema resuelto? No exactamente... ¡Los sistemas de archivos son más complicados que simplemente leer, escribir y listar archivos! Aquí, Cargo se queja porque las versiones anteriores de NFS, sobre las que está construida la implementación xetdata/nfsserve, no admiten bloqueo de archivos.

macOS-FUSE-t está construido sobre NFSv4, que sí admite bloqueo de archivos, pero el repositorio de GitHub no contiene más que tres archivos que no son código fuente (Attributions.txt, License.txt, README.md) y fue creado por una cuenta de GitHub con el sospechosamente específico nombre de usuario macos-fuse-t sin más información. Obviamente, no podemos distribuir binarios aleatorios a nuestros usuarios... Los issues abiertos también indican algunos problemas más fundamentales con el enfoque basado en NFS/SMB, principalmente relacionados con errores del kernel de Apple.
¿Con qué nos quedamos? O bien un nuevo enfoque creativo, 15 o... ¡política! La travesía de una década de Apple para eliminar gradualmente las extensiones de kernel les ha llevado a abrir cada vez más APIs de nivel de usuario (como DriverKit), y su compatibilidad integrada con sistemas de archivos antiguos se ha trasladado recientemente al espacio de usuario. Su código abierto de MS-DOS hace referencia a un framework privado llamado FSKit aquí, ¡lo cual suena muy prometedor! Da la sensación de que, con un poco de política, podríamos conseguir que lo finalicen y publiquen FSKit para desarrolladores externos (¿o quizás ya lo están planeando?), en cuyo caso podríamos tener también una solución al problema de ejecutabilidad en macOS.
Preguntas abiertas
Como hemos visto, el problema en apariencia simple de dejar que las IA iteren sobre código en segundo plano es en realidad bastante complejo. El shadow workspace fue un proyecto de 1 semana y 1 persona para crear una implementación que resolviera la necesidad inmediata que teníamos de mostrar lints a la IA. En el futuro, planeamos ampliarlo para resolver también el problema de la capacidad de ejecución. Algunas preguntas abiertas:
-
¿Hay alguna otra forma de implementar la carpeta proxy sencilla que estamos considerando sin crear una extensión de kernel o usar la API de FUSE? FUSE intenta resolver un problema más grande (cualquier tipo de sistema de archivos), por lo que parece plausible que pueda haber algunas APIs poco conocidas en macOS y Windows que funcionen para nuestro proxy de carpeta pero que no servirían para una implementación general de FUSE.
-
¿Cómo sería exactamente la historia de la carpeta proxy en Windows? ¿Algo como WinFsp simplemente funcionaría, o habría problemas de instalación, rendimiento o seguridad con eso? Pasé la mayor parte de mi tiempo investigando cómo hacer el proxy de carpeta en macOS.
-
¿Quizás haya alguna forma de usar DriverKit en macOS y simular un dispositivo USB falso que actúe como carpeta proxy? Lo dudo, pero no he analizado la API con suficiente detalle como para afirmar con confianza que es imposible.
-
¿Cómo podemos lograr independencia a nivel de red? Una situación particular a considerar es cuando la IA quiere depurar una prueba de integración donde el código está dividido entre tres microservicios. Es posible que queramos hacer algo más parecido a una máquina virtual, aunque eso requerirá más trabajo para garantizar la equivalencia de toda la configuración del entorno y de todo el software instalado.
-
¿Hay alguna forma de crear un entorno de trabajo remoto idéntico a partir del entorno de trabajo local del usuario con la menor configuración posible por parte del usuario? En la nube, podríamos usar FUSE directamente (o incluso un módulo de kernel si se desea por razones de rendimiento) sin tener que lidiar con cuestiones políticas, y también podríamos garantizar que no haya uso adicional de memoria para el usuario y una independencia total. Para los usuarios que se preocupan menos por la privacidad, esta podría ser una buena alternativa. Una idea preliminar es algún tipo de contenedor de Docker inferido automáticamente observando el sistema (quizás usando una combinación de escribir scripts para detectar qué se está ejecutando en la máquina y usar modelos de lenguaje para escribir un Dockerfile).
Si tienes buenas ideas para cualquiera de estas preguntas, envíame un correo electrónico a arvid@cursor.com. Además, si te gustaría trabajar en cosas como esta, estamos contratando.