Cómo comparamos la calidad de los modelos en Cursor
Nota: CursorBench se actualiza continuamente a medida que evolucionan las capacidades de los agentes. La versión actual en producción es CursorBench 3.1; consulta esa página para ver la clasificación más reciente.
Los desarrolladores les están pidiendo a los agentes de programación que asuman tareas más largas y complejas, que abarcan múltiples archivos, herramientas y pasos. A medida que estas solicitudes aumentan en alcance, las evaluaciones que miden el rendimiento de los agentes también deben evolucionar.
En Cursor, usamos un proceso híbrido de evaluación online y offline para mantener nuestra comprensión de la calidad de los modelos alineada con lo que los desarrolladores realmente hacen.
La parte offline usa CursorBench, nuestra suite de evaluación interna basada en sesiones reales de Cursor de nuestro equipo de ingeniería. Como las tareas provienen del uso real de Cursor y no de repositorios públicos, CursorBench distingue mejor entre modelos y se alinea más estrechamente con los resultados reales de los desarrolladores que los benchmarks públicos.
Creamos CursorBench para medir múltiples dimensiones del rendimiento de los agentes, como la corrección de la solución, la calidad del código, la eficiencia y el comportamiento durante la interacción. Este blog se centra en los resultados de corrección de la solución, pero en la práctica evaluamos a los agentes en todos estos ejes.
Actualización, mayo de 2026: Desde entonces, hemos actualizado CursorBench a la versión 3.1 con problemas más difíciles. Como cambió la distribución de los problemas, las puntuaciones de CursorBench 3.1 pueden diferir de los números y gráficos de esta publicación y deben compararse dentro de la misma versión de la eval.


Complementamos CursorBench con análisis controlados sobre tráfico real. Estas evaluaciones online detectan regresiones que los conjuntos offline pasan por alto, como cuando el resultado del agente le parece correcto a un evaluador, pero ofrece una peor experiencia para un desarrollador que usa el producto.
En conjunto, este ciclo online-offline mantiene nuestra noción de calidad de los modelos anclada en producción a medida que cambian los flujos de trabajo, y nos permite diseñar la mejor experiencia posible con agentes en Cursor.
Las limitaciones de los benchmarks públicos
Un buen benchmark debe distinguir entre modelos que, en la práctica, rinden de forma diferente, y al mismo tiempo reflejar cómo los desarrolladores realmente los experimentan. Las evaluaciones públicas offline fallan en ambos aspectos.
El primer problema es la alineación. A medida que los desarrolladores afrontan trabajos cada vez más complejos y variados con agentes, los benchmarks estáticos o desalineados terminan evaluando cosas completamente equivocadas. La mayoría de los benchmarks de SWE, por ejemplo, siguen centrados en tareas de solución de errores. Del mismo modo, Terminal-Bench hace hincapié en tareas amplias de tipo rompecabezas, como encontrar la mejor jugada de ajedrez a partir de una posición en el tablero. Creemos que esto no se ajusta bien al trabajo de programación que los desarrolladores piden a los agentes.
El segundo es la evaluación. Muchas tareas de benchmarks públicos presuponen un conjunto limitado de soluciones correctas, pero la mayoría de las solicitudes de los desarrolladores están lo bastante poco especificadas como para admitir muchos enfoques válidos. Como resultado, los benchmarks tienden a penalizar enfoques alternativos correctos o a añadir requisitos sintéticos para eliminar esa ambigüedad. Ninguna de las dos opciones proporciona una evaluación precisa del rendimiento real.
El tercero es la contaminación. SWE-bench Verified, Pro y Multilingual extraen tareas de repositorios públicos que acaban en los datos de entrenamiento de los modelos, inflando las puntuaciones. OpenAI recientemente dejó de informar por completo los resultados de SWE-bench Verified tras descubrir que los modelos de vanguardia podían reproducir de memoria los parches de referencia y que casi el 60 % de los problemas no resueltos tenían pruebas defectuosas.
El resultado es que, en niveles de vanguardia, estos benchmarks ya no distinguen entre modelos con utilidades muy distintas para los desarrolladores.
Cómo construimos CursorBench
Obtenemos tareas para CursorBench con Cursor Blame, que vincula el código confirmado con la solicitud del agente que lo produjo. Esto nos proporciona una correspondencia natural entre la consulta del desarrollador y la solución de referencia. Muchas tareas provienen de nuestra base de código interna y de fuentes controladas, lo que reduce el riesgo de que los modelos las hayan visto durante el entrenamiento. Actualizamos la suite cada pocos meses para seguir los cambios en la forma en que los desarrolladores usan agentes.
El alcance de los problemas en nuestras evaluaciones de corrección se ha duplicado aproximadamente desde la versión inicial hasta la actual, CursorBench-3, tanto en líneas de código como en el número medio de archivos. Las tareas de CursorBench-3 abarcan sustancialmente más líneas que las de SWE-bench Verified, Pro o Multilingual. Aunque las líneas de código son una medida imperfecta de la dificultad, el aumento en esa métrica refleja cómo hemos incorporado tareas más complejas a CursorBench, como gestionar entornos con múltiples espacios de trabajo y monorepos, investigar registros de producción y realizar experimentos de larga duración.
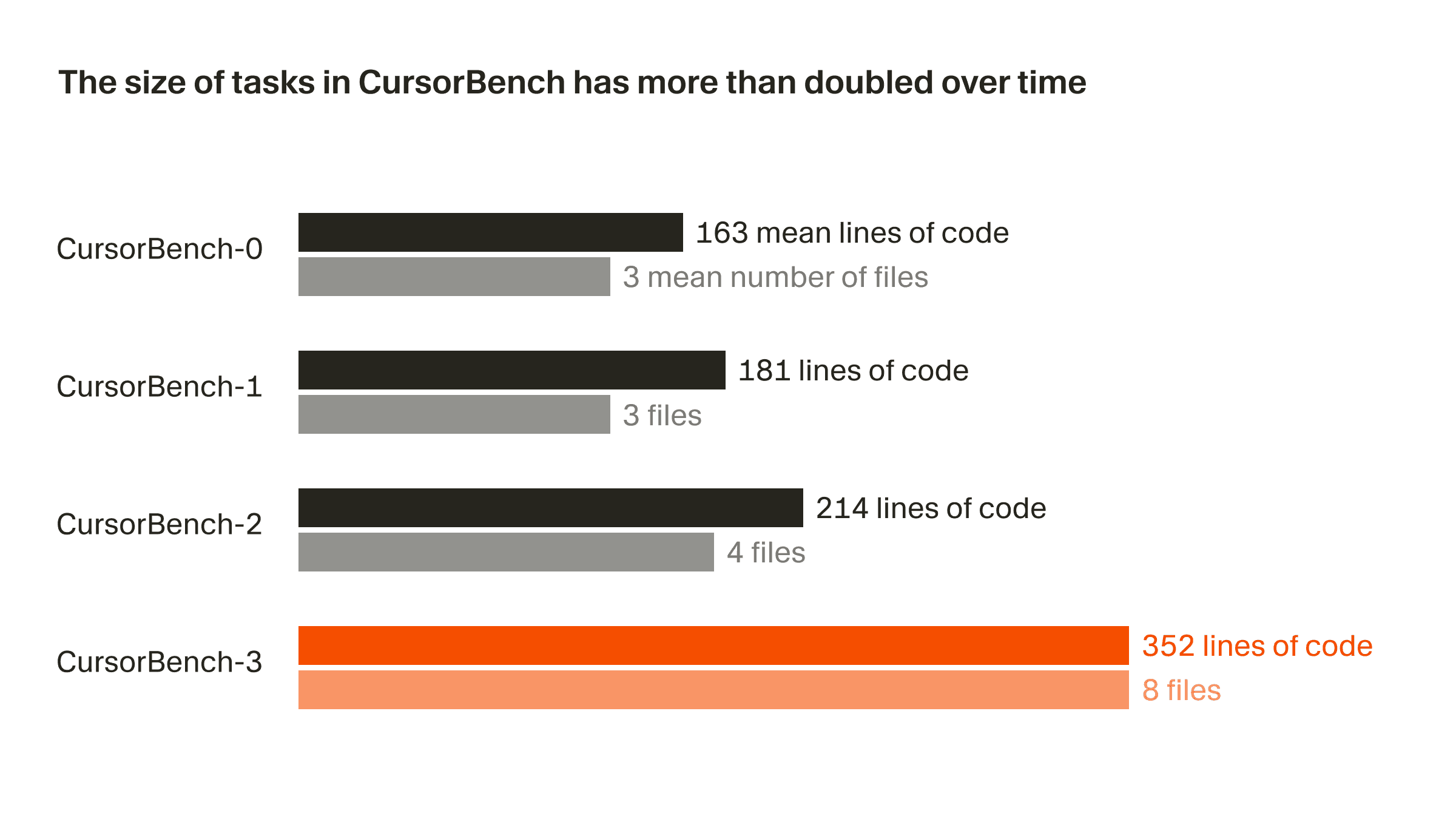
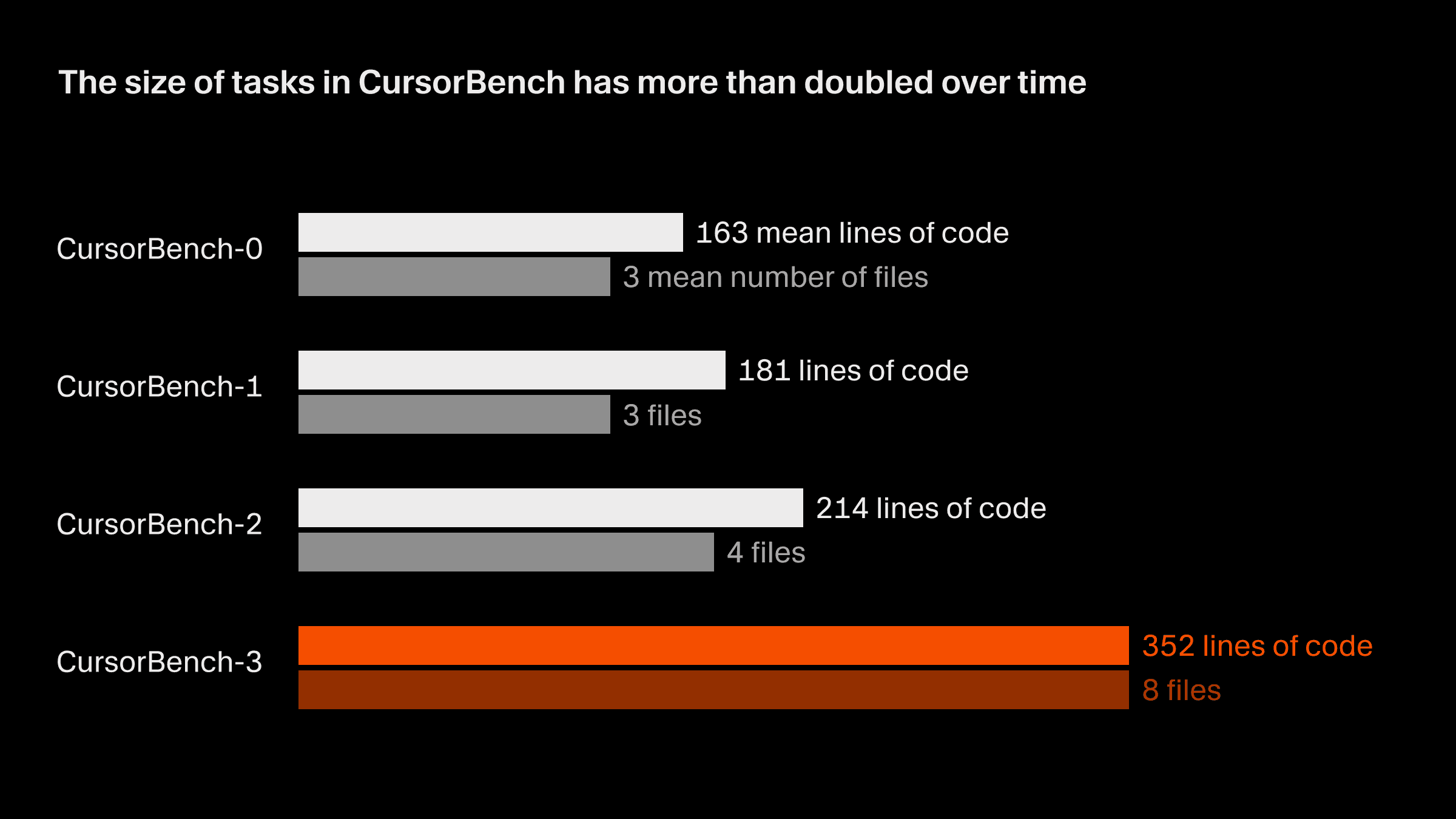
Las tareas de CursorBench también se ajustan a la forma poco especificada y a menudo ambigua en que los desarrolladores se comunican con los agentes. Nuestras descripciones de tareas son intencionalmente breves, en contraste con las detalladas incidencias de GitHub utilizadas en benchmarks públicos, y usamos evaluadores basados en agentes para puntuarlas de forma fiable.


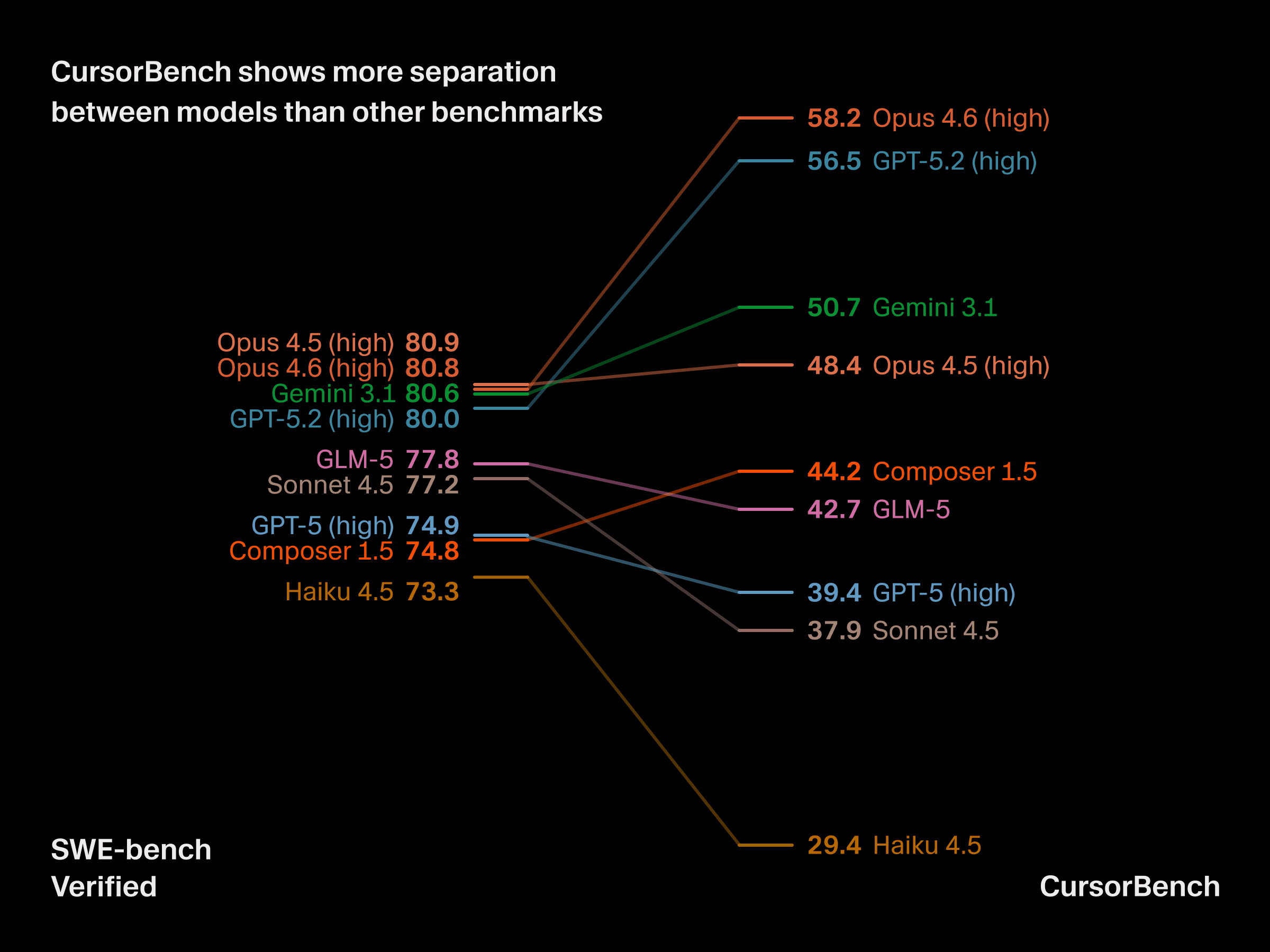
CursorBench muestra una mayor diferenciación entre modelos
Estas diferencias en la complejidad de las tareas y en la especificación tienen consecuencias prácticas para la utilidad de los benchmarks. CursorBench genera una mayor diferenciación entre modelos en los niveles más avanzados, donde los benchmarks públicos están cada vez más saturados, y, en algunos casos, modelos como Haiku pueden igualar o superar a GPT-5. CursorBench distingue de forma fiable entre modelos que los desarrolladores perciben como claramente diferentes.

Las puntuaciones de CursorBench se alinean con las evaluaciones en línea
La evaluación en línea mide si las mejoras de nuestro agente realmente ayudan a los desarrolladores en la práctica. Hacemos seguimiento de un conjunto de indicadores de alto nivel que sirven como aproximaciones de los resultados del agente, incluidas señales tanto de la interacción como de la calidad de los resultados generados, y buscamos movimientos consistentes entre ellos en lugar de optimizar una sola métrica. Al agregarlos, podemos detectar regresiones en las que los resultados del agente obtienen una buena puntuación con un evaluador offline, pero en realidad no funcionan bien para los desarrolladores.
Usamos experimentos en línea controlados para atribuir el impacto. Por ejemplo, al iterar sobre la búsqueda semántica y la recuperación, ejecutamos una ablación eliminando por completo la herramienta de búsqueda semántica. Esto nos permitió identificar con precisión los escenarios en los que la búsqueda semántica era más importante, como las preguntas y respuestas basadas en el repositorio en bases de código más grandes.
Las clasificaciones de CursorBench también reflejan más de cerca cómo los desarrolladores perciben la calidad del modelo en Cursor, según lo medido por nuestras métricas de evaluación en línea.


La próxima suite de evaluación
Aunque las tareas de CursorBench-3 son más largas que las de los benchmarks públicos, siguen resolviéndose dentro de una sola sesión. Anticipamos que, durante el próximo año, la gran mayoría del trabajo de desarrollo pasará a agentes de larga duración que trabajen en sus propios equipos, y estamos planeando adaptar CursorBench en consecuencia. Para ello, será necesario encontrar formas de abaratar la evaluación, resolver la reproducibilidad en tareas que interactúan con servicios externos y cerrar la brecha entre la evaluación offline y la experiencia de los desarrolladores.
El ciclo online-offline nos da lo que creemos que es la base adecuada, y planeamos compartir más a medida que sigamos construyendo sobre ella.
Si te interesa trabajar en problemas técnicos complejos relacionados con el futuro de la programación, contáctanos en hiring@cursor.com.