Composer 2 vorgestellt
Composer 2 ist jetzt in Cursor verfügbar.
Beim Programmieren erreicht es Frontier-Niveau und kostet 2.50/M Ausgabe-Token, was es zu einer neuen, optimalen Kombination aus Intelligenz und Kosten macht. Wir haben außerdem einen technischen Bericht dazu veröffentlicht, wie wir es trainiert haben.


Programmierintelligenz auf Frontier-Niveau
Wir verbessern die Qualität unseres Modells rasant. Composer 2 liefert große Verbesserungen bei allen von uns gemessenen Benchmarks, einschließlich Terminal-Bench 2.01 und SWE-bench Multilingual:
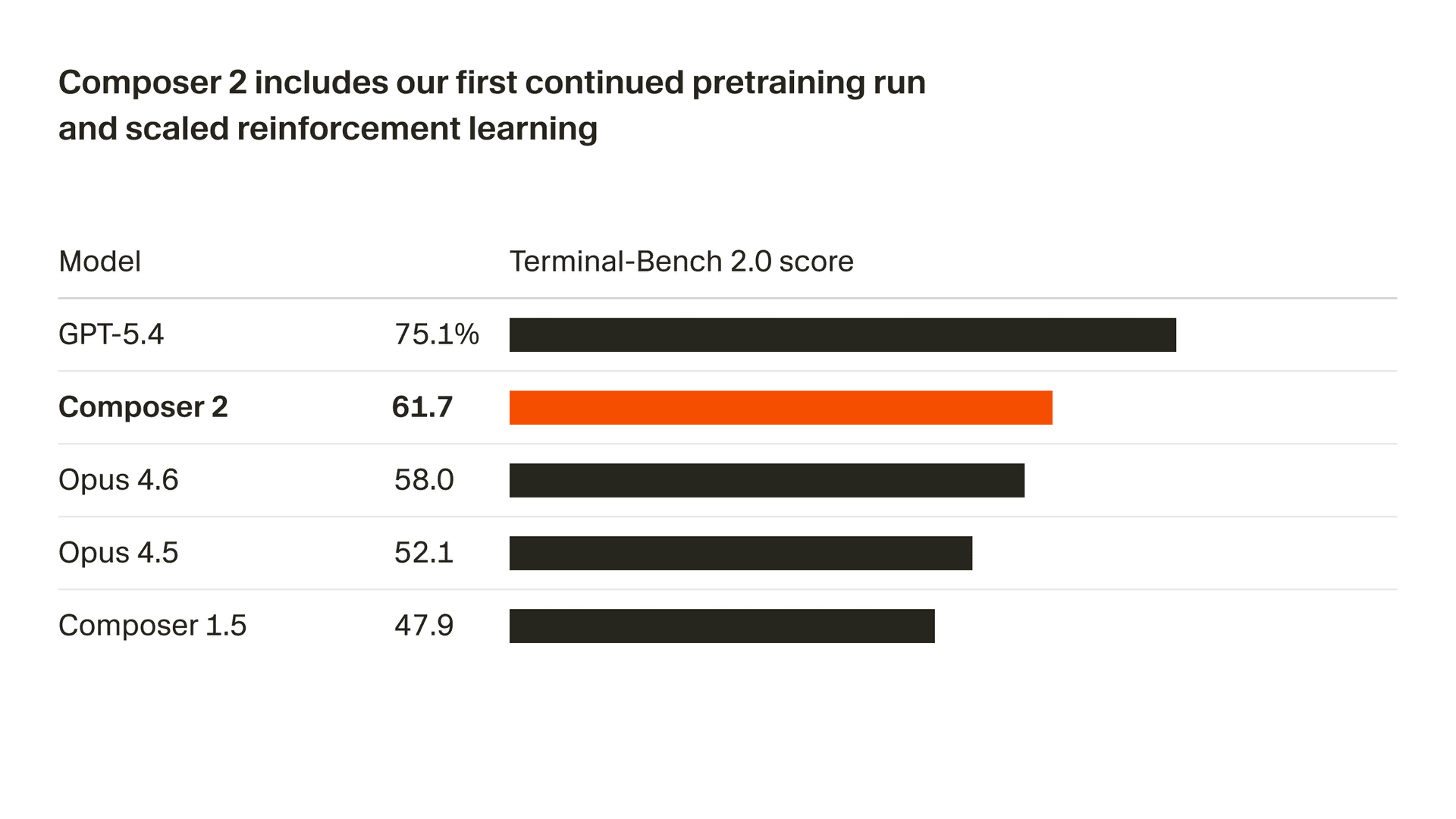
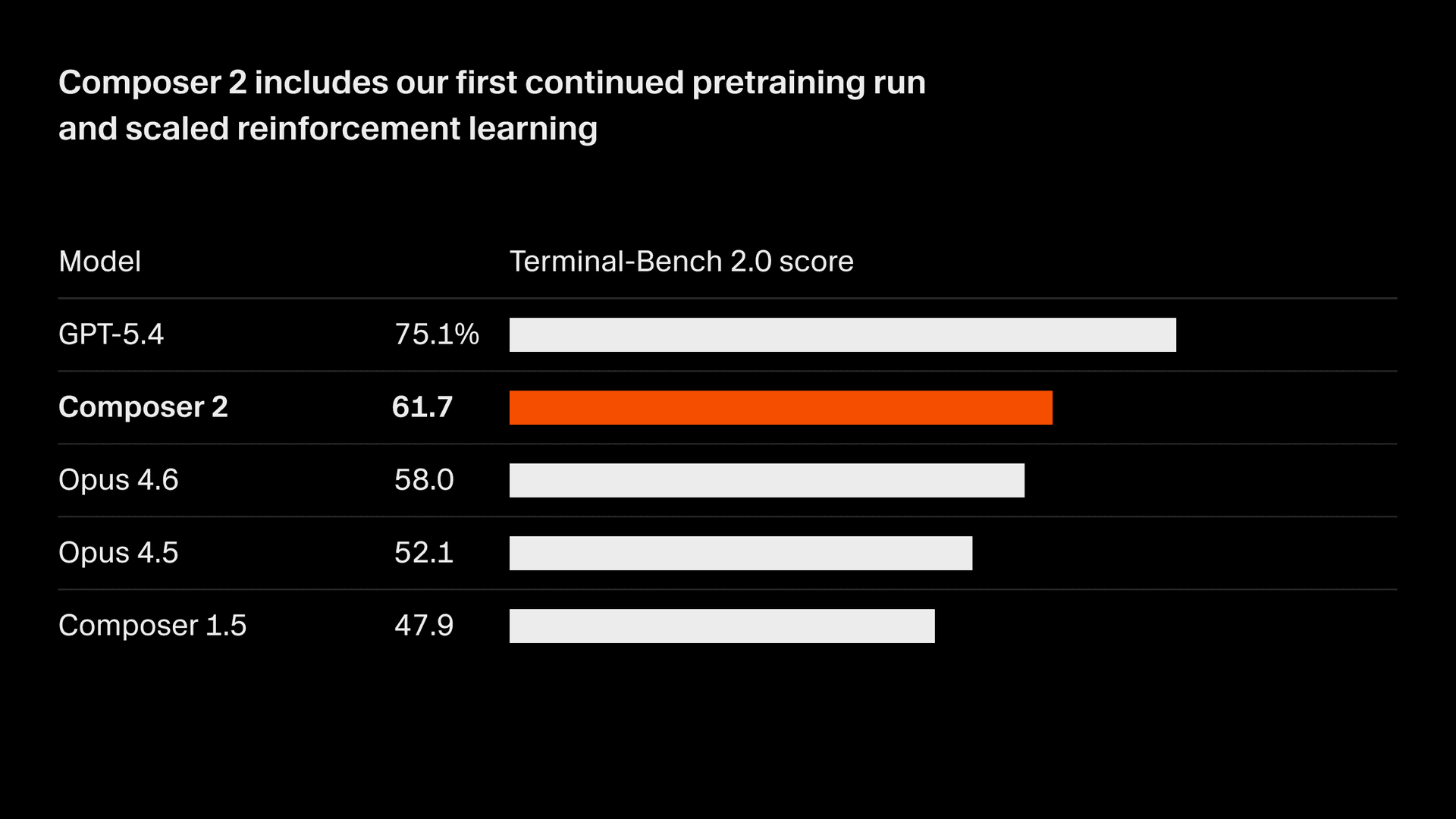
| Modell | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Diese Qualitätsverbesserungen gehen auf unseren ersten fortgesetzten Pretraining-Lauf zurück, der eine deutlich stärkere Grundlage für die Skalierung unseres Reinforcement Learning schafft.
Auf dieser Grundlage trainieren wir mit Reinforcement Learning an Programmieraufgaben mit langem Horizont. Composer 2 ist in der Lage, anspruchsvolle Aufgaben zu lösen, die Hunderte von Aktionen erfordern.
Probieren Sie Composer 2 aus
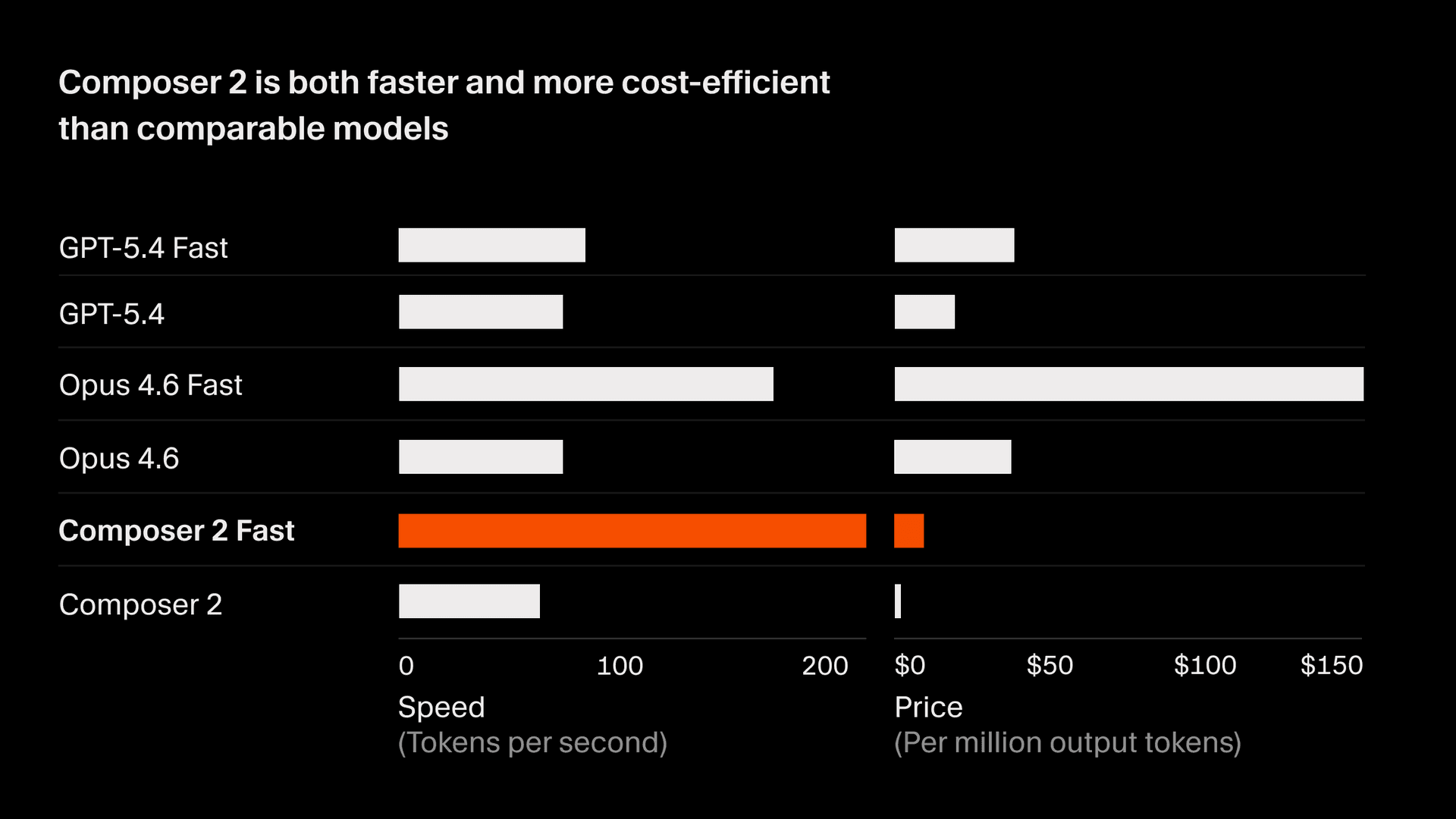
Composer 2 kostet 2.50/M Ausgabe-Token.
Es gibt auch eine schnellere Variante mit derselben Leistungsfähigkeit für 7.50/M Ausgabe-Token, die niedrigere Kosten als andere schnelle Modelle hat2. Wir machen die schnelle Variante zur Standardoption. Ausführliche Details finden Sie in der aktuellen Composer-Modelldokumentation.

Bei Individual-Plänen ist die Composer-Nutzung Teil des Pools für First-Party-Modelle mit großzügigem Inklusivkontingent. Probieren Sie Composer 2 noch heute in Cursor oder in der frühen Alpha-Version unserer neuen Oberfläche aus.
- Terminal-Bench 2.0 ist ein Benchmark zur Bewertung von Agenten bei der Terminal-Nutzung, der vom Laude Institute gepflegt wird. Für Anthropic-Modelle werden die Bewertungen mit dem Claude Code Harness ermittelt, für OpenAI-Modelle mit dem Simple Codex Harness. Unser Cursor-Wert wurde mit dem offiziellen Harbor-Evaluierungsframework (dem vorgesehenen Harness für Terminal-Bench 2.0) mit den Standard-Benchmark-Einstellungen berechnet. Wir haben pro Modell-Agent-Paar 5 Iterationen ausgeführt und den Durchschnitt angegeben. Mehr Details zum Benchmark finden Sie auf der offiziellen Terminal-Bench-Website. Für andere Modelle außer Composer 2 haben wir den Maximalwert aus dem Ergebnis auf dem offiziellen Leaderboard und dem bei Ausführung in unserer Infrastruktur gemessenen Wert verwendet. ↩
- Die Token pro Sekunde (TPS) für alle Modelle stammen aus einer Momentaufnahme des Cursor-Traffics vom 18. März 2026. Die Token-Größe für Composer- und GPT-Modelle ist ähnlich. Anthropic-Token sind etwa 15 % kleiner, und die TPS-Zahl wurde entsprechend normalisiert. Entsprechend wurde der Preis pro Ausgabe-Token für Nicht-Anthropic-Modelle skaliert, um dieselbe Änderung von etwa 15 % zu berücksichtigen. Die Geschwindigkeit kann je nach Kapazität des Anbieters und Verbesserungen im Laufe der Zeit variieren. ↩