Ein technischer Bericht zu Composer 2

Wir haben einen technischen Bericht zum Training von Composer 2 auf arXiv veröffentlicht, unserem Programmier-Modell für agentenbasierte Softwareentwicklung.
Der Bericht behandelt den gesamten Trainingsprozess, von fortgesetztem Pretraining auf einem offenen Basismodell, Kimi K2.5, bis hin zu groß angelegtem Reinforcement Learning, mit dem Ziel, die reale Cursor-Umgebung möglichst genau nachzubilden.
Fortgesetztes Pretraining und RL
Composer 2 wird in zwei Phasen trainiert: zunächst durch fortgesetztes Pretraining auf einem Datenmix mit Schwerpunkt auf Code, um das Programmier-Wissen des Basismodells zu vertiefen, gefolgt von groß angelegtem Reinforcement Learning, um die End-to-End-Performance des Agenten zu verbessern. Wir beobachten, dass eine Verringerung des Pretraining-Loss die nachgelagerte RL-Performance verbessert und dass sich besseres Basiswissen zuverlässig in einem leistungsfähigeren Agenten niederschlägt.
Das RL-Training von Composer 2 findet in realistischen Cursor-Sitzungen statt – mit denselben Tools und demselben Harness, die auch das eingesetzte Modell nutzt – und auf einer Aufgabenverteilung, die die gesamte Bandbreite dessen abbildet, worum Entwickler Composer bitten. Wir beobachten, dass RL-Training sowohl die durchschnittliche als auch die Best-of-K-Performance verbessert. Das deutet darauf hin, dass das Modell neue Lösungswege erlernt, statt bekannte nur stärker auszunutzen.
Praxisnahe Evaluierung mit CursorBench
Eine zentrale Herausforderung beim Entwickeln von Modellen fürs Programmieren ist, dass öffentliche Benchmarks die tatsächliche Arbeit von Entwicklern oft nicht widerspiegeln. Aufgaben sind zu stark spezifiziert, Lösungswege eng vorgegeben und die Codebasen klein.
Wir haben CursorBench aus realen Programmiersitzungen unseres Engineering-Teams erstellt. Es umfasst Aufgaben, bei denen der Prompt knapp und mehrdeutig ist und deren Lösung Änderungen über Hunderte von Zeilen in vielen Dateien erfordert. Wir nutzen CursorBench im gesamten Training und in der Evaluierung, damit das Modell auf reale Probleme ausgerichtet bleibt.
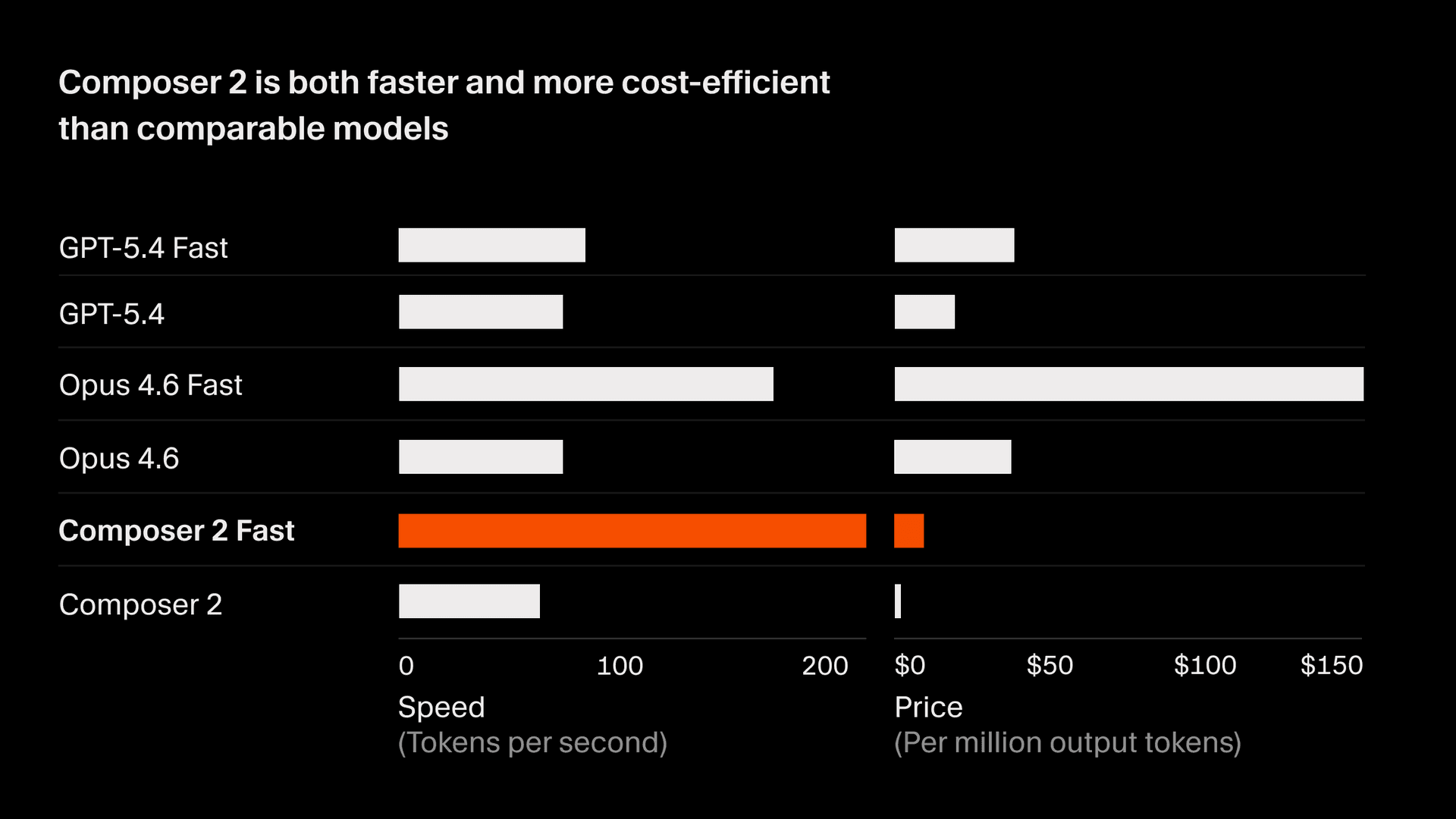
Performance
Auf CursorBench erreicht Composer 2 einen Score von 61,3 – eine Verbesserung um 37 % gegenüber Composer 1.5 – und ist damit konkurrenzfähig mit den stärksten Frontier-Modellen. In öffentlichen Benchmarks erzielt Composer 2 73,7 auf SWE-bench Multilingual und 61,7 auf Terminal-Bench. Das gelingt bei deutlich geringeren Inferenzkosten als bei vergleichbaren Modellen und sorgt für einen Pareto-optimalen Trade-off zwischen Genauigkeit und Kosten für interaktive Entwickler-Workflows.



Infrastruktur
Das Training von Composer 2 erforderte einen erheblichen Ausbau der Infrastruktur: mit maßgeschneiderten Low-Precision-Kernels für effizientes MoE-Training auf Blackwell-GPUs, einer vollständig asynchronen RL-Pipeline über mehrere Regionen hinweg und Anyrun, unserer internen Compute-Plattform zum Ausführen von Hunderttausenden isolierten Programmier-Umgebungen. Der Bericht behandelt den gesamten Stack, einschließlich unseres Ansatzes für Gewichtssynchronisierung, Fehlertoleranz und Umgebungsfidelität.
Der Bericht geht auf all das noch deutlich ausführlicher ein, einschließlich Ablationsstudien zur Trainingsrezeptur, unseres Ansatzes zur Steuerung des Agentenverhaltens und des Designs unserer Evaluierungssuite.
Vielen Dank an die Teams hinter Kimi K2.5, Ray, ThunderKittens, PyTorch und die breitere Open-Source-Community. Außerdem möchten wir Fireworks und Colfax für ihre Zusammenarbeit und Partnerschaft danken.
Lies den vollständigen technischen Bericht hier.