Composer für längere Horizonte trainieren
Wir trainieren Composer für Aufgaben mit langem Horizont mithilfe eines Reinforcement-Learning-Prozesses namens Selbstzusammenfassung. Indem wir Selbstzusammenfassung zu einem Teil des Trainings von Composer machen, können wir Trainingssignale aus Trajektorien holen, die weit über das maximale Kontextfenster des Modells hinausgehen. Dadurch kann Composer lernen, anspruchsvolle Coding-Aufgaben zu bewältigen, die Hunderte von Aktionen erfordern.
Die Grenzen von Komprimierungstechniken
In CursorBench, unserer internen Benchmark-Suite, beobachten wir, dass bessere Leistung bei anspruchsvollen realen Coding-Aufgaben direkt mit mehr Nachdenken und intensiverer Erkundung der Codebase korreliert. Wenn Benutzer mit Agenten an schwierigeren und ambitionierteren Aufgaben arbeiten, erwarten wir, dass der Ertrag von Nachdenken und Erkundung noch weiter steigt.
Eine zentrale Herausforderung ist jedoch, dass Agent-Trajektorien schneller wachsen als die Kontextlänge von Modellen. Viele Agent-Harnesses versuchen, dieses Problem zu umgehen, indem sie Komprimierung als Zwischenschritt im Workflow des Agenten nutzen. Wenn ein Agent an seine Kontextgrenze stößt, verdichtet das Harness den Kontext auf eine kürzere Länge und setzt die Generierung des Agenten an der Stelle fort, an der sie unterbrochen wurde.
In der Praxis wird Komprimierung vom Harness typischerweise auf eine von zwei Arten umgesetzt: entweder im Textraum durch ein per Prompt gesteuertes Zusammenfassungsmodell oder über ein gleitendes Kontextfenster, bei dem das Modell älteren Kontext verwirft. Forschende haben außerdem begonnen, Komprimierungsmethoden im latenten Raum zu erforschen, bei denen das Modell sich Kontext als Vektoren statt als Text merkt, obwohl diese Ansätze derzeit deutlich langsamer sind als textbasierte Methoden.
Diese Komprimierungsansätze haben den gemeinsamen Nachteil, dass sie dazu führen können, dass das Modell kritische Informationen aus dem Kontext vergisst, was seine Wirksamkeit bei lang laufenden Aufgaben verringert.
Selbstzusammenfassung als trainiertes Verhalten
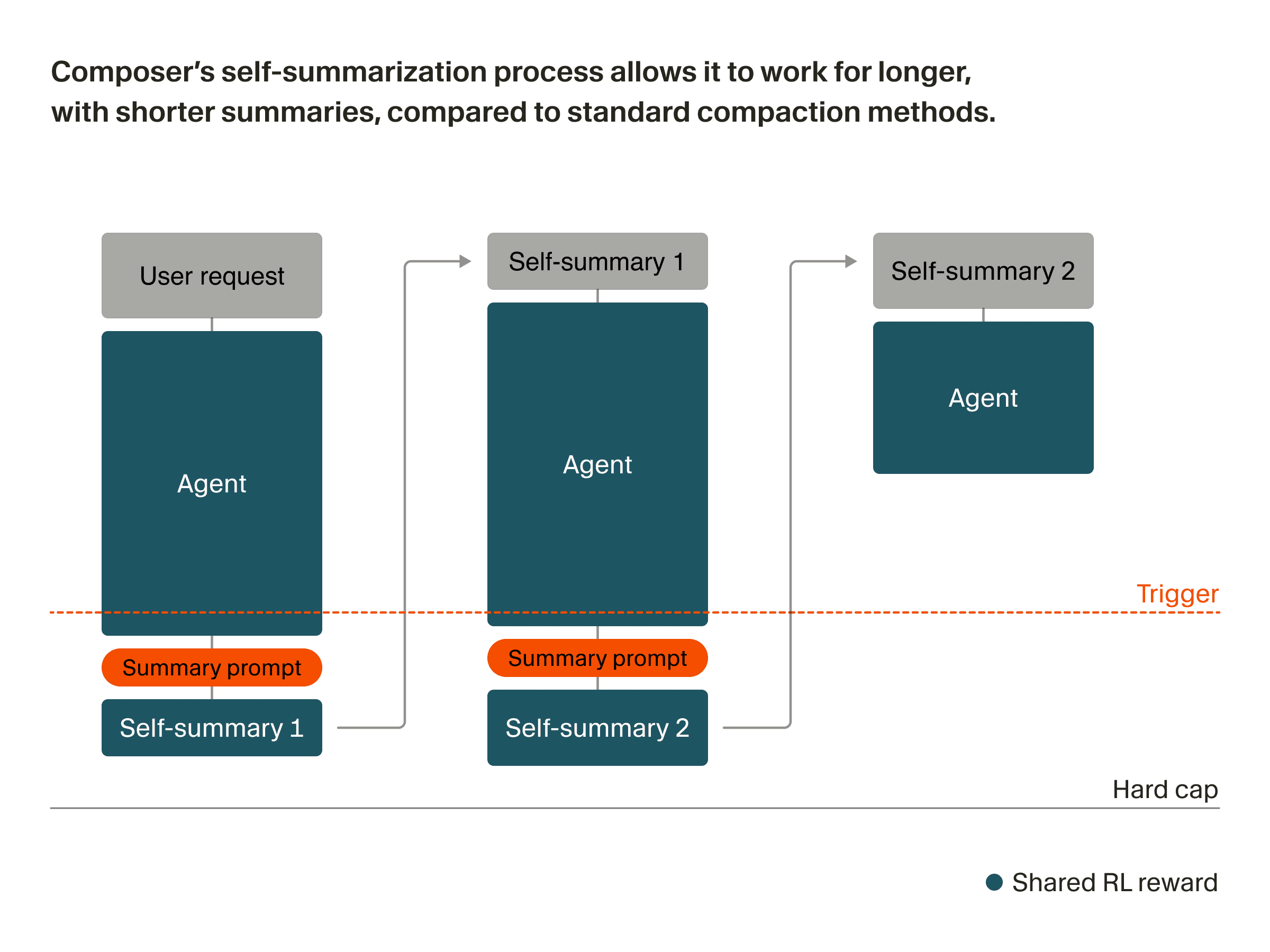
Composer ist ein spezialisiertes Modell, das für agentenbasiertes Coding entwickelt und durch Reinforcement Learning im Cursor-Agent-Harness trainiert wurde. Dadurch kann es mit Compaction-in-the-loop trainiert werden, was seine Fähigkeit verbessert, die wichtigsten Informationen zu bestimmen, die zusammengefasst und erhalten werden sollen.
Während Composer eine Aufgabe bearbeitet, nähert es sich einem festen Schwellenwert für die Kontextlänge. An diesem Punkt pausiert es, um seinen eigenen Kontext zusammenzufassen, bevor es fortfährt. Genauer gesagt funktioniert die Selbstzusammenfassung so:
-
Composer generiert von einem Prompt aus, bis ein fester Schwellenwert für die Tokenlänge erreicht ist.
-
Wir fügen eine synthetische Anfrage ein, die das Modell auffordert, den aktuellen Kontext zusammenzufassen.
-
Das Modell erhält einen Scratchpad-Bereich, um über die beste Zusammenfassung nachzudenken, und erzeugt dann einen verdichteten Kontext.
-
Composer startet mit dem verdichteten Kontext, der die Zusammenfassung plus den Konversationszustand enthält (Planstatus, verbleibende Aufgaben, Anzahl vorheriger Zusammenfassungen usw.), wieder bei Schritt 1.
Damit Composer dies bei der Inferenz gut beherrscht, integrieren wir dasselbe Zusammenfassungsverfahren in das Training. Jeder Trainings-Rollout kann mehrere durch Zusammenfassungen verkettete Generierungen umfassen, statt nur aus einem einzelnen Prompt-Antwort-Paar zu bestehen. Das bedeutet, dass die Selbstzusammenfassungen selbst Teil dessen sind, was belohnt wird.
Aus technischer Sicht erfordert dies keine wesentlichen Änderungen am Training. Wir verwenden die abschließende Belohnung für alle Tokens, die das Modell in der Kette erzeugt. Dadurch werden sowohl die Agent-Antworten in guten Trajektorien als auch die Selbstzusammenfassungen, die diese ermöglicht haben, höher gewichtet. Gleichzeitig werden schlechte Zusammenfassungen, bei denen kritische Informationen verloren gingen, niedriger gewichtet. Während Composer trainiert, lernt es, diesen Prozess der Selbstzusammenfassung zu nutzen, um längere Kontexte aufzubauen. Bei schwierigen Beispielen fasst es seinen Kontext oft mehrfach selbst zusammen.
Token-effiziente Komprimierung
Um die Selbstzusammenfassung zu testen, vergleichen wir sie mit einer stark optimierten, promptbasierten Baseline für die Komprimierung. Wir untersuchen das Problem anhand einer Reihe anspruchsvoller Softwareentwicklungsaufgaben, wobei wir den Komprimierungs-Trigger variieren.
Beim Baseline-Ansatz für die Komprimierung umfasst der Prompt für die Zusammenfassung Tausende von Token und enthält fast ein Dutzend sorgfältig formulierter Abschnitte, die beschreiben, welche Inhalte in der Zusammenfassung erhalten bleiben sollen. Auch der kompaktierte Ausgabekontext ist im Durchschnitt mehr als 5.000 Token lang und enthält viele strukturierte Abschnitte mit kritischen Informationen aus dem Kontext.
Im Gegensatz dazu benötigt Composer, da es auf Selbstzusammenfassung trainiert ist, nur einen sehr kurzen Prompt, der kaum mehr enthält als „Bitte fasse die Unterhaltung zusammen“. Die von Composer erzeugten Zusammenfassungen sind im Durchschnitt nur etwa 1.000 Token lang, da das Modell kontextabhängig lernt zu entscheiden, welche besonders wertvollen Informationen erhalten bleiben sollen.
Wir testen Composer in zwei Testumgebungen mit eingeschränktem Kontext, um die Wirkung der Selbstzusammenfassung zu messen: eine mit einem 80k-Token-Trigger und eine weitere mit einem 40k-Trigger (was häufigere Zusammenfassungen bedeutet). In beiden Szenarien liefert die Selbstzusammenfassung auf CursorBench deutlich bessere Ergebnisse bei wesentlich token-effizienteren Komprimierungen. Sie reduziert den durch die Komprimierung verursachten Fehler konsistent um 50 % – selbst im Vergleich zum gezielten Baseline-Ansatz – und nutzt dabei nur ein Fünftel der Token sowie die Wiederverwendung des KV-Caches (der gespeicherten Zwischenberechnungen aus vorherigen Token).


Schwierige Probleme lösen
Das zentrale Versprechen der Komprimierung ist, es Modellen zu ermöglichen, schwierige Probleme in einem Anlauf zu lösen, die lange Schlussfolgerungsketten erfordern. Beim aktuellen Training von Composer 2 sehen wir oft, dass dies geschieht. Als Fallstudie betrachten wir ein Problem aus Terminal-Bench 2.0 mit dem Namen make-doom-for-mips. Das Problem ist ebenso knapp beschrieben wie anspruchsvoll:
Ich habe /app/doomgeneric/ bereitgestellt, den Quellcode von Doom. Ich habe außerdem eine spezielle doomgeneric_img.c geschrieben, die du nutzen sollst und die jedes gerenderte Bild nach /tmp/frame.bmp schreibt. Außerdem habe ich vm.js bereitgestellt, das eine Datei namens doomgeneric_mips erwartet und ausführt. Bitte kümmere dich um den Rest …
Dieses Problem lässt sich zwar leicht beschreiben, ist aber anspruchsvoll genug, dass mehrere leistungsstarke Modelle es in den offiziell berichteten Ergebnissen nicht korrekt lösen können.
Beim Testen eines frühen Forschungs-Checkpoints von Composer stellten wir fest, dass es dieses Problem korrekt lösen konnte. Die Lösung erforderte die Entwicklung und das Testen einer erheblichen Menge an Code sowie die Erkundung einiger alternativer Implementierungen. Hier ist ein im Verlauf der Lösung des Problems gerendertes Bild:

Insgesamt arbeitete Composer 170 Turns lang, um eine präzise Lösung zu finden, und erstellte dabei Selbstzusammenfassungen in einer kompakten, menschenlesbaren und strukturierten Form. Es verdichtete mehr als 100.000 Tokens auf die 1.000, von denen es glaubte, dass sie ihm am meisten dabei helfen würden, das Problem zu lösen:
## Zusammenfassung der Unterhaltung
### Ziel des Benutzers
Ein MIPS-Little-Endian-ELF namens doomgeneric_mips erstellen, damit `node vm.js` es ausführen kann: stdout soll funktionieren, und Frames sollen mit der bereitgestellten doomgeneric_img.c (und doomgeneric-Quellen unter `/app/doomgeneric/`) nach `/tmp/frame.bmp` geschrieben werden.
### Was implementiert wurde
1. Freestanding libc für die JS-VM (`/app/mips_freestanding/`)
- Die VM implementiert Linux-artige Open-Flags, aber die Syscall-Nummern entsprechen keinem echten MIPS-Linux (0=read, 1=write, 2=open, 3=close, 8=lseek, 201=time, 38=rename, 39=mkdir). Normales mipsel-linux-gnu-gcc + glibc würde Nummern im 4003+-Stil verwenden und würde nicht funktionieren.
- `my_libc.c` + `vm_syscall.h`: diese Syscalls, plus minimales `malloc`/`free`/`realloc`, `stdio` (`fopen`/`fread`/`fwrite`/…), Strings, `printf`-Teilmenge, `qsort`, `sin`/`atan`/`fabs`, `strdup`, `abs`, `system`-Stub usw.
2. `doomgeneric_img.c` (unter `/app/doomgeneric/doomgeneric/`)
- Nutzt `my_stdlib.h`.
- `DG_DrawFrame`: schreibt jeden Frame nach `/tmp/frame.bmp` (32-Bit-BMP).
- `main`: sicheres `argc`/`argv` (Fallback-argv bei null), dann `doomgeneric_Create` → unendliche `doomgeneric_Tick()`-Schleife (gleiches Muster wie andere doomgeneric-Frontends).
3. Build — `/app/doomgeneric/doomgeneric/Makefile.mips`
- `mipsel-linux-gnu-gcc`, `-fno-pic -mno-abicalls`, `-static -nostdlib`, `-Wl,-e,main`, Link `libgcc`.
- Non-PIC war erforderlich, um Folgendes zu vermeiden: Einstieg bei `main` mit nicht gesetztem `$t9` brach den GP-relativen GOT; non-PIC hat das behoben.
- Objekte: vollständige Doom-Liste mit `doomgeneric_img.o` statt xlib; kein `deh_str.o` (nur Header).
- `i_system.c`: `DEFAULT_RAM` / `MIN_RAM` über `-D` überschreibbar; Build verwendete `-DDEFAULT_RAM=4 -DMIN_RAM=4`, um die Zone für die VM zu verkleinern.
- Ausgabe: `/app/doomgeneric_mips`. Nicht strippen — die VM löst `main` aus `.symtab` auf.
4. Änderungen an `vm.js` (wichtig für den anderen Assistenten)
- OOM: Einfacher `{}`-Speicher ließ V8 abstürzen, wenn Doom viele Words berührte.
- `runElf`: allokiert jetzt `Uint32Array` Low-RAM (96 MB ab `0x400000`) + Stack (~8 MB ab `0x7f800000`), lädt `.text`/`.data`/`.rodata` in den Low-Buffer, gibt `{ lowMem, stkMem, memLowBase, …, entry_point }` statt eines riesigen `memory`-Objekts zurück.
- `MIPSVM`: `memGetWord` / `memSetWord` leiten durch diese Buffer; spärliches `this.memory` für Stores effektiv entfernt (OOM-Fix); `memGetWord` OOB → 0 (kann Bugs verbergen).
- Alle `lw`/`sw`/Byte-Helfer und der `runProgram`-Instruction-Fetch nutzen `memGetWord`/`memSetWord`. Das Ende des Skripts verdrahtet `vm._lowMem` usw. aus `runElf`.
### Fehler / Fixes (Kurzfassung)
- Falsche Syscalls → eigene libc + VM-Syscall-Nummern.
- Link-Fehler → `strdup`, `strstr`, `abs`, `putchar`, `puts`, `atof`, `system`, `remove`/`rename` hinzugefügt; nicht vorhandenes `deh_str.o` entfernt.
- Sofortiger Absturz beim Einstieg → `-fno-pic -mno-abicalls`.
- Node OOM → ArrayBuffer-gestützter VM-Speicher; unbegrenzte `this.memory`-Schreibvorgänge entfernt.
- `r_segs.c`: `SHRT_MAX` → zu `limits.h` hinzugefügt.
### Was noch defekt ist / für den nächsten Assistenten zu tun ist
- `/tmp/frame.bmp` erschien in Tests nie: Ausführung endet mit `Program terminated at PC=0x400151`, `Executed 626581578` instructions. `0x400150` ist das `abort`-Symbol (enger Branch-to-self). Irgendetwas springt also letztendlich in `abort` — kein sauberer Game-Loop, der Frames zeichnet.
- 4-MB-Zone (`DEFAULT_RAM=4`) ist möglicherweise zu klein für echtes IWAD-Gameplay → `Z_Malloc` / OOM-artige Fehler oder anderes undefiniertes Verhalten; es lohnt sich, `DEFAULT_RAM=6` und ein größeres `HEAP_SIZE` in `my_libc.c` (wurde auf 14 MB reduziert) auszuprobieren und sicherzustellen, dass `memGetWord` OOB keine echten Fehler maskiert.
- Konkrete nächste Schritte: herausfinden, wer `abort` aufruft (z. B. Trap, libgcc-Pfad, fehlgeschlagene Allokation); I_Error-Pfad auf Nicht-Win beheben (ruft derzeit möglicherweise `ZenityErrorBox` / ungewöhnliche Pfade auf); `doomgeneric_Create` → `D_DoomMain` → … → `doomgeneric_Tick`/`D_Display` → `DG_DrawFrame` bestätigen; `fopen("/tmp/frame.bmp","wb")` + `SYS_close`-Flush in der VM verifizieren; erneut ausführen, bis `/tmp/frame.bmp` existiert und stdout plausibel aussieht.
### Pfade
- ELF: `/app/doomgeneric_mips`
- Build: `/app/doomgeneric/doomgeneric/Makefile.mips`
- Frontend: `/app/doomgeneric/doomgeneric/doomgeneric_img.c`
- Libc: `/app/mips_freestanding/my_libc.c`, `/app/mips_freestanding/include/*`
- VM: `/app/vm.js` (gepatchtes Speichermodell)
- Lokal verwendetes IWAD: `/app/doom1.wad` (zum Testen)Auf dem Weg in eine Zukunft mit langem Horizont
Durch die Einbindung der Komprimierung in die Trainingsschleife lernt Composer einen expliziten Mechanismus, um wichtige Informationen effizient weiterzutragen, und wird bei anspruchsvollen Aufgaben leistungsfähiger. Unsere Arbeit an der Selbstzusammenfassung ist ein Schritt hin zu unserem übergeordneten Ziel, Composer für noch längere und komplexere Prozesse wie die Koordination mehrerer Agenten zu trainieren. Wir sehen weiterhin, dass besseres Modelltraining den Funktionsumfang und die Intelligenz dieser agentenbasierten Systeme verbessert.
Wir werden außerdem in Kürze mehr über die nächste Version von Composer bekannt geben.