使用陰影工作區進行迭代
這裡有個穩輸的做法:把幾個相關檔案貼進一份 Google 文件,把連結傳給你最欣賞、但對你程式碼庫一無所知的 p60 軟體工程師,然後請他們在那份文件裡完整且正確地實作你下一個 PR (拉取請求) 。
請一個 AI (人工智慧) 做同樣的事,它也會──毫不意外地──失敗。
現在,改成給他們你的開發環境的遠端存取權,可以看到 lint 提示、跳到定義、執行程式碼,你或許就能期待他們多少真的派得上用場。
我們認為,要讓 AI 為你撰寫更多程式碼,其中一個關鍵能力就是能夠在你的開發環境中迭代。但如果天真地讓 AI 在你的資料夾裡到處亂動,結果只會是一團亂:想像一下,你好不容易寫出一個需要大量推理的函式,卻被 AI 覆寫;或者你正準備執行程式,卻發現 AI 插入了無法編譯的程式碼。若真要有幫助,AI 的迭代必須在背景進行,而且不能影響你的開發體驗。
為了達成這點,我們在 Cursor 中實作了我們稱為 shadow workspace (陰影工作區) 的機制。在這篇部落格文章中,我會先說明我們的設計準則,接著描述目前在 Cursor 中的實作方式 (隱藏的 Electron 視窗) ,以及未來打算走向的方向 (核心層級的資料夾代理) 。

設計準則
我們希望 shadow workspace 能達成以下目標:
-
LSP 可用性(LSP-usability):AI 應該能看到自己變更所產生的 lints、能跳轉到定義,並且更一般地說,可以與 language server protocol(LSP,語言伺服器協定)的所有部分互動。
-
可執行性(Runnability):AI 應該能執行它們的程式碼並查看輸出結果。
我們一開始會先專注在 LSP 可用性。
這些目標必須在以下需求的前提下達成:
-
獨立性(Independence):使用者的程式開發體驗必須不受影響。
-
隱私(Privacy):使用者的程式碼必須是安全的(例如,全部都保留在本機)。
-
併發性(Concurrency):多個 AI 應該可以同時進行各自的工作。
-
普遍性(Universality):它應該能適用於所有語言以及各種工作區設定。
-
可維護性(Maintainability):實作時應盡量使用少量且可隔離的程式碼。
-
速度(Speed):任何地方都不應出現長達數分鐘的延遲,並且應該能夠支撐數百個 AI 分支的吞吐量。
上述許多點反映了為超過十萬名使用者打造程式碼編輯器時的現實考量。我們真的不希望任何人的開發體驗受到負面影響。
實現 LSP 可用性
讓 AI 對其編輯內容執行 lint 檢查,是在底層語言模型固定不變時,提升程式碼生成效能最具影響力的方法之一。lint 不僅能協助把「90% 可運作的程式碼」推進到「100% 可運作的程式碼」,在情境(context)受限、AI 必須在第一次就對要呼叫哪個方法或服務做出合理猜測時,也非常有幫助。lint 還能協助找出 AI 需要詢問更多資訊的地方。

LSP 可用性也比可執行性更容易達成,因為幾乎所有 language server 都能在不將檔案寫入檔案系統的情況下對其進行操作(而且如我們稍後所見,一旦牽涉到檔案系統,事情就會變得麻煩許多)。所以先從這裡開始吧!秉持我們第五項需求——可維護性——的精神,我們首先嘗試了最簡單可行的解法。
看起來簡單但行不通的解法
Cursor 是從 VS Code fork 出來的,這代表我們已經能很輕鬆地存取各種 language server。在 VS Code 中,每個開啟的檔案都由一個 TextModel 物件表示,這個物件會在記憶體中保存檔案的目前狀態。Language server 會從這些 TextModel 物件中讀取資料,而不是從磁碟讀取,這也是為什麼它們能在你輸入時就提供補全與 lint(而不是只在你儲存時才提供)。
假設有個 AI 對檔案 lib.ts 進行了編輯。我們顯然不能修改對應 lib.ts 的既有 TextModel 物件,因為使用者可能同時正在編輯它。儘管如此,一個看似合理的想法是:建立 TextModel 物件的副本,把這個副本從磁碟上的實體檔案「分離」,然後讓 AI 在該物件上進行編輯並從中取得 lint。這可以用以下 6 行程式碼達成。
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// 建立記憶體內的 TextModel 副本並套用 AI 編輯
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// 等待 2 秒讓語言伺服器處理新的 TextModel 物件
await new Promise((resolve) => setTimeout(resolve, 2000));
// 從標記服務讀取 lints,該服務會根據語言內部路由至正確的擴充功能
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}這個方案在可維護性上顯然是極為出色的。在通用性方面也很優秀,因為多數人早就為自己的專案安裝並設定好了合適的語言專用擴充功能。並行性與隱私性也幾乎是自然而然就能滿足的。
問題在於獨立性。雖然建立一份 TextModel 的複本代表我們並沒有直接修改使用者正在編輯的檔案,但我們仍然會把這個複製檔案的存在告訴語言伺服器——也就是使用者本身正在使用的那個語言伺服器。這會帶來一堆問題:例如「跳到參考」的結果會包含我們的複製檔案;像 Go 這種擁有多檔案預設命名空間範圍的語言,會對複製檔案與使用者可能正在編輯的原始檔案中所有函式的重複宣告報錯;而像 Rust 這種只有在檔案被其他地方明確匯入時才會被納入的語言,則完全不會給你任何錯誤。很有可能還有更多類似的問題。
你可能會覺得這些問題聽起來都不大,但對我們來說,獨立性絕對是關鍵。如果我們哪怕只是在一點點程度上弱化了正常的程式碼編輯體驗,那不管我們的 AI 功能有多厲害——人們(包括我自己)都不會想用 Cursor。
我們也考慮過其他幾個最後證明行不通的點子:在 VS Code 基礎架構之外另外啟動我們自己的 tsc、gopls 或 rust-analyzer 執行個體;複製執行所有 VS Code 擴充功能的 extension host 程序,讓我們能同時執行每個語言伺服器擴充功能的兩個副本;以及 fork 所有常見的語言伺服器來支援同一檔案的多個不同版本,然後再把那些擴充功能打包進 Cursor 裡。
目前的 shadow workspace 實作方式
我們最後將 shadow workspace 實作成一個隱藏視窗:每當 AI(人工智慧)想要查看它所寫程式碼的 lints 時,我們就會為目前的 workspace 產生一個隱藏視窗,然後改成在那個視窗中進行編輯,再把 lints 回報回來。我們會在多個請求之間重複使用這個隱藏視窗。這種做法在滿足所有需求的同時,讓我們幾乎完整地達成 LSP 的可用性(也幾乎完全符合要求)。星號部分稍後會解釋。
圖 4 顯示了簡化後的架構圖。
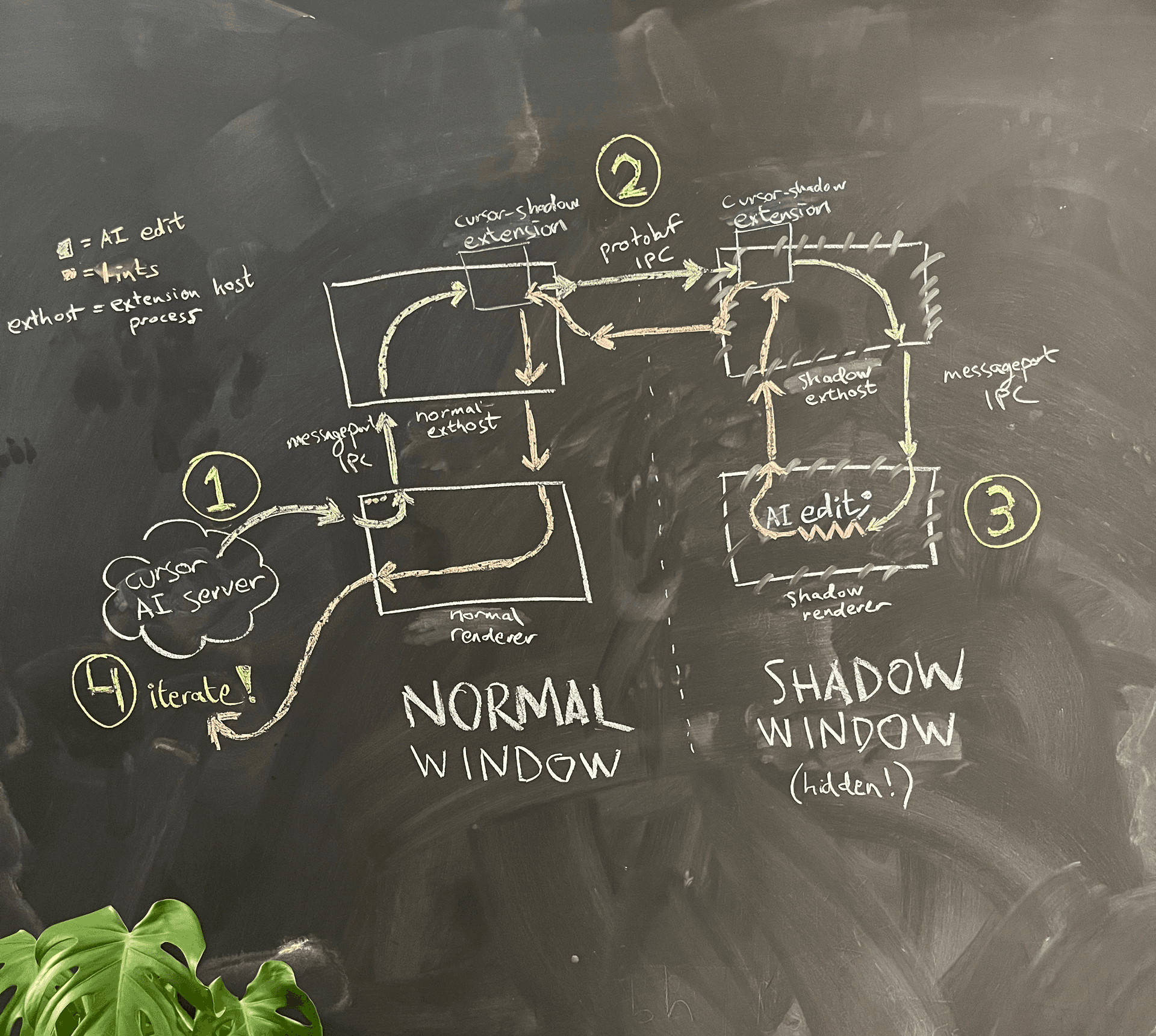
AI 是在一般視窗的 renderer process 中執行的。當它想要查看自己寫出來的程式碼的 lints 時,renderer process 就會請 main process 在同一個資料夾中產生一個隱藏的 shadow 視窗。
由於 Electron 的 sandboxing,這兩個 renderer process 不能彼此直接通訊。我們曾考慮一個選項:重用 VS Code 為了讓 renderer process 能與 extension host process 溝通而實作的精細 message port 建立邏輯,用它在一般視窗與 shadow 視窗之間建立我們自己的 message port IPC。考量長期可維護性的負擔後,我們選擇了一個 hack:重用既有、從 renderer process 到 extension host 的 message port IPC,接著再在 extension host 與 extension host 之間,用另一條獨立的 IPC 連線來溝通。在這裡,我們也順便塞入一個提升使用體驗的小改進:我們現在可以使用 gRPC 和我們很喜歡的 buf 來溝通,而不必再依賴 VS Code 自訂、而且有點脆弱的 JSON 序列化邏輯。
這樣的設定自然就相當容易維護,因為新增的程式碼與其他程式碼彼此獨立,而用來隱藏視窗的核心程式碼只有一行(在 Electron 中開啟視窗時,只要提供參數 show: false 就能把視窗隱藏起來)。在通用性與隱私上,它也能輕鬆滿足需求。
幸運的是,獨立性也同樣被滿足了!新的視窗與使用者完全獨立,因此 AIs 可以在裡面自由做任何它們想做的變更,並取得相對應的 lints。使用者完全不會察覺。
不過,shadow 視窗還是有一個顧慮:這個新視窗在最天真的實作下,會讓記憶體使用量提高約 2 倍。我們透過幾種方式降低這個影響:限制能在 shadow 視窗中執行的擴充功能、在 15 分鐘沒有活動後自動關閉它,並且確保這功能是需要使用者主動啟用的。儘管如此,它對併發性仍然造成挑戰:我們不能單純為每一個 AI 都產生一個新的 shadow 視窗。幸好,這裡我們可以利用 AI 和人類之間的一個關鍵差異:AI 可以被暫停任意長的時間而毫無感覺。具體來說,如果你有兩個 AI,A 和 B,分別提出 A1 接著 A2,以及 B1 接著 B2 這樣的編輯,我們就可以把這些編輯交錯處理。shadow 視窗會先把整個資料夾狀態重設為 A1,取得 lints 並回傳給 A。接著,再把整個資料夾狀態重設為 B1,取得 lints 並回傳給 B。然後以同樣方式處理 A2 與 B2。某種意義上,AI 更像是電腦上的 process(也同樣被 CPU 這樣交錯排程,卻不會察覺),而不像人類(人類對時間有內在感知)。
把這一切綜合起來,我們得到一個簡單的 Protobuf API,讓在背景執行的 AIs 可以用來反覆修正它們的編輯,完全不會影響使用者。
先前提到會解釋的星號註記:有些 language server 在回報 lint 前,必須先將程式碼寫入磁碟。主要的例子是 rust-analyzer language server,它僅是執行專案層級的 cargo check 來取得 lint,而不會整合 VS Code 的虛擬檔案系統(可參考 this issue)。因此,shadow workspace 目前尚未能良好支援 Rust 的 LSP 使用體驗,除非使用者使用的是已被棄用的 RLS 擴充套件。
達成可執行性
談到可執行性時,事情就會變得既有趣又複雜。我們目前在 Cursor 上專注於短時間尺度的 AI——也就是在你使用函式的同時,於背景中幫你實作這些函式,而不是一次幫你實作整個 PR(拉取請求)——因此我們尚未實作這部分的可執行能力。不過,思考要如何達成它仍然很有趣。
執行程式碼需要先將其儲存到檔案系統。許多專案也會對磁碟產生副作用(例如建置快取和記錄檔)。因此,我們不能再在與使用者相同的資料夾中啟動 shadow 視窗。若要讓所有專案都具備完美的可執行性,我們還需要網路層級的隔離,但目前我們先專注於達成磁碟隔離。
最簡單的想法:cp -r
最簡單的想法是遞迴地把使用者的資料夾複製到 /tmp 目錄,然後在那裡套用 AI(人工智慧)編輯、儲存檔案並執行程式碼。對於下一次由不同 AI 執行的編輯,我們會先執行 rm -rf,接著再執行一次新的 cp -r 指令,以確保 shadow workspace 能與使用者的 workspace 保持同步。
問題在於速度:cp -r 真的很慢。要記住的一點是,為了能執行一個專案,我們不只需要複製原始碼,還得複製所有支援建置相關的檔案。具體來說,我們需要在 JavaScript 專案中複製 node_modules,在 Python 專案中複製 venv,以及在 Rust 專案中複製 target。這些通常都是非常巨大的資料夾,即使是中型專案也是如此,也讓這種天真的 cp -r 做法行不通。
符號連結(symlink)、硬連結(hardlink)、寫入時複製(copy-on-write)
複製和建立大型資料夾結構不一定要非常慢!一個現成的例子是 bun,它在將快取的相依套件安裝到 node_modules 時,通常只需要不到一秒。在 Linux 上,bun 使用硬連結,速度快是因為根本沒有實際的資料移動。在 macOS 上,bun 則使用相對較新的 clonefile 系統呼叫,可以對檔案或資料夾進行寫入時複製。
可惜的是,對於我們中等規模的單一儲存庫(monorepo),即使用 cp -c 做 clonefile 也要花 45 秒才會完成。這太慢了,無法在每次 shadow workspace 請求之前執行。硬連結令人卻步,因為你在 shadow 資料夾中執行的任何操作,都可能不小心修改原始儲存庫中的真實檔案。符號連結也有類似問題,而且還有一個額外麻煩:它們無法被透明地處理,通常需要額外的設定(例如 Node.js 的 --preserve-symlinks 旗標)。
我們可以想像,如果搭配某種精巧的記錄機制來避免在每次請求前都重新複製資料夾,那麼 clonefile(甚至一般的 cp -r)也許可以奏效。為了確保正確性,我們需要監控使用者資料夾自上次完整複製以來的所有檔案變更,以及複製後資料夾中的所有檔案變更,並在每次請求前先撤銷後者,再重放前者的變更。每當任一側的變更歷史大到難以追蹤時,我們可以重新做一次完整複製並重設狀態。這也許可行,但感覺很容易出錯、脆弱,而且坦白說,為了達成一個聽起來這麼簡單的目標,實在有點醜陋。
我們真正想要的是什麼:核心層級的資料夾代理
我們真正想要的其實很簡單:我們想要一個影子資料夾 A′,在所有使用一般檔案系統 API 的應用程式看來,都與使用者的資料夾 A 完全相同,同時還能快速設定一小組覆寫檔案,而這些檔案的內容則是從記憶體中讀取。我們也希望對資料夾 A′ 的任何寫入都會寫入記憶體中的覆寫儲存區,而不是寫進磁碟。簡而言之,我們想要一個可設定覆寫規則的代理資料夾,並且我們樂於把整個覆寫表完全放在記憶體裡。接著,我們就可以在這個代理資料夾內啟動影子視窗,達成與磁碟層級完全獨立。
關鍵在於,我們需要核心層級對資料夾代理的支援,這樣任何執行中的程式碼就可以在不做任何修改的情況下,繼續呼叫 read 和 write 系統呼叫。其中一種作法是建立一個核心擴充模組 13,將自己在核心的虛擬檔案系統中註冊為影子資料夾的後端,並實作前面描述的簡單行為。
在 Linux 上,我們可以改在使用者層級使用 FUSE(「使用者空間檔案系統」)來達成。FUSE 是一個核心模組,大多數 Linux 發行版預設就已包含,它會把檔案系統呼叫代理到一個使用者層級的行程。這讓實作資料夾代理變得更加簡單。資料夾代理的一個簡易範例實作可以像下面這樣,這裡以 C++ 呈現。
首先,我們匯入使用者層級的 FUSE 函式庫,負責與 FUSE 核心模組溝通。我們也會定義目標資料夾(使用者的資料夾)以及記憶體中的覆寫對應表。
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// 其他引入...
using namespace std;
// 不想修改的代理資料夾
string target_folder = "/path/to/target/folder";
// 要套用的記憶體內覆寫內容
unordered_map<string, vector<char>> overrides;接著,我們定義一個自訂的 read 函式,先檢查 overrides 中是否包含該路徑;如果沒有,就直接從目標資料夾讀取。
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 檢查路徑是否在覆寫表中
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// 若是,則返回覆寫的內容
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// 否則,從代理資料夾開啟並讀取檔案
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}我們自訂的 write 函式只是將資料寫入 overrides 對應表。
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 始終寫入覆寫項
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}最後,我們將自訂函式註冊到 FUSE。
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}真正的實作則需要實作整個 FUSE API,包括 readdir、getattr 和 lock,不過這些函式的寫法都會和上面那些非常相似。對於每一個新的 lint 請求,我們只要把 overrides map 重設為只包含該次特定 AI(人工智慧)編輯的內容即可,而且幾乎可以瞬間完成。如果想要避免記憶體暴增,也可以把 overrides map 存在磁碟上(只是需要額外的記錄與管理工作)。
在能完全掌控環境的情況下,我們很可能會選擇把這個實作成原生的 kernel module,而不是使用 FUSE,以避免 FUSE 帶來的額外 user-kernel 上下文切換開銷。14
……但是:圍牆花園
在 Linux 上,FUSE 資料夾 proxy 表現很好,但我們的大多數使用者都在使用 macOS 或 Windows,而這兩者都沒有內建的 FUSE 實作。不幸的是,隨產品附帶 kernel extension 也完全不在考量範圍內:在使用 Apple Silicon 的 Mac 上,使用者唯一能安裝 kernel extension 的方式,是在重新啟動電腦時按住特殊按鍵進入復原模式,然後將系統降級到「降低安全性(Reduced Security)」。完全沒辦法實際出貨!
由於 FUSE 的部分邏輯必須在核心內執行,像 macFUSE 這樣的第三方 FUSE 實作,也一樣會遇到「根本不可能讓使用者安裝」的問題。
社群已經嘗試用更有創意的方式繞過這個限制。其中一種作法是選擇一個 macOS 原生支援的、以網路為基礎的檔案系統(例如 NFS 或 SMB),再在下面放一層 FUSE API。有一個開源的 proof-of-concept 本機伺服器,提供類 FUSE API,建構在 NFS 之上,託管在 xetdata/nfsserve;而封閉原始碼專案 macOS-FUSE-t 則支援同時建構在 NFS 與 SMB 上的後端。
問題解決了嗎?也沒有……檔案系統可不是只有讀取、寫入與列出檔案這麼簡單!在這裡,Cargo 會抱怨,因為 xetdata/nfsserve 的實作是建構在較舊版本的 NFS 上,而這些版本並不支援檔案鎖定。

macOS-FUSE-t 則是建構在 有 支援檔案鎖定的 NFSv4 之上,但這個 GitHub repo 只有三個非原始碼檔案(Attributions.txt、License.txt、README.md),而且是由一個用途可疑地單一的 GitHub 帳號 macos-fuse-t 建立,沒有任何進一步資訊。顯然,我們不可能隨便把來路不明的二進位檔交付給使用者……公開的 issue 也指出了基於 NFS/SMB 這種做法的一些更根本問題,多半與 Apple 的 kernel bug 有關。
那我們還剩下什麼選項?要嘛是全新的創意做法,要嘛是再等個 15 年,或者……政治!Apple 長達十年的計畫是要淘汰 kernel extension,這也促使他們開放愈來愈多使用者層級的 API(例如 DriverKit),而他們對舊檔案系統的內建支援最近也切換到了 user-land。他們開源的 MS-DOS 程式碼在這裡引用了一個名為 FSKit 的私有 framework,看起來非常有希望!感覺上,只要做一點「政治工作」,我們或許就能讓他們正式定案並將 FSKit 對外開放給開發者使用(或者他們其實已經有這樣的規劃了?),如果真是這樣,我們搞不好也能順利解決 macOS 上的可執行性問題。
未解決的問題
如我們所見,讓 AI 在背景中對程式碼不斷迭代這個看似簡單的問題,其實相當複雜。shadow workspace 是一個為期 1 週、由 1 個人完成的專案,目標是先實作一個方案,解決我們當下「讓 AI 看到 lints」的需求。未來,我們打算擴充它來同時解決「可執行性」的問題。以下是幾個未解決的問題:
-
是否有其他方式能達成我們設想的簡易 proxy 資料夾,而不必建立 kernel extension 或使用 FUSE API?FUSE 嘗試解決的是一個更大的問題(任何類型的檔案系統),因此感覺上有可能在 macOS 和 Windows 上存在某些較冷門的 API,可以滿足我們對資料夾 proxy 的需求,但又不適用於一般的 FUSE 實作。
-
在 Windows 上,proxy 資料夾的整體方案究竟會是什麼樣子?像是 WinFsp 這樣的東西是否可以直接運作,還是會有安裝、效能或安全性的問題?我大部分時間都花在研究如何在 macOS 上實作資料夾 proxy。
-
也許有辦法在 macOS 上使用 DriverKit,並模擬一個假的 USB 裝置來充當 proxy 資料夾?我有點存疑,但我還沒有夠仔細地研究該 API,無法有信心地說這是絕對不可能的。
-
我們要如何在網路層級上達成獨立性?有一種特定情境值得考量:當 AI 想要除錯一個整合測試,而該程式碼被拆分在三個微服務之間。有可能我們需要做一些更像 VM 的東西,雖然那會需要更多工作,才能確保整個環境設定與所有已安裝軟體都具備等價性。
-
是否有辦法從使用者的本機 workspace 建立一個完全相同的遠端 workspace,同時讓使用者幾乎不需要任何額外設定?在雲端環境中,我們可以直接開箱使用 FUSE(或在需要效能時甚至可使用 kernel module),而不必處理任何組織層面的阻力,並且也能保證不會額外佔用使用者的記憶體,同時達到完全獨立。對於比較不在意隱私的使用者,這可能是個不錯的選項。一個初步的想法是:透過觀察系統,自動推斷出某種 Docker 容器(也許結合撰寫腳本來偵測機器上正在執行的程式,並使用語言模型來產生 Dockerfile)。
如果你對上述任何問題有好的想法,請寄電子郵件給我:arvid@cursor.com。另外,如果你有興趣參與這類專案,我們正在招募。