Maior uso para agentes
Aumentamos os limites para Auto e Composer 1.5 em todos os planos individuais.
Agora há dois pools de uso:
- Saldo de modelos próprios: No lançamento, incluímos um volume de uso significativamente maior para Auto e Composer 1.5.
- API: Cobramos o preço de API do modelo (inalterado com esta atualização).
O Composer 1.5 agora tem 3x o limite de uso do Composer 1. Por tempo limitado (até 16 de fevereiro), estamos aumentando esse limite para 6x mais.
De autocomplete a agentes
Nos últimos meses, vimos uma grande mudança em direção à programação com agentes.
Desenvolvedores estão pedindo para o Cursor fazer mudanças ambiciosas em toda a sua base de código. Queremos que o Cursor ofereça suporte à programação orientada a agentes no dia a dia e reconhecemos que desenvolvedores têm prioridades diferentes.
Alguns se sentem à vontade pagando sempre pelos modelos mais novos, enquanto outros buscam o equilíbrio certo entre velocidade, inteligência e custo. Ao introduzir dois pools de uso e aumentar os limites para modelos próprios, estamos dando suporte às duas abordagens.
Um novo modelo para programação orientada a agentes
Treinar nossos próprios modelos, como o Composer-1.5, nos permite oferecer um volume de uso significativamente maior de forma sustentável.
Constatamos que o Composer 1.5 é um modelo altamente capaz, com pontuação acima do Sonnet 4.5 no Terminal-Bench 2.0, embora ainda abaixo dos melhores modelos de ponta.1


Esperamos continuar encontrando maneiras de oferecer modelos cada vez mais inteligentes e econômicos, além dos mais recentes modelos de ponta.
Visibilidade de uso aprimorada
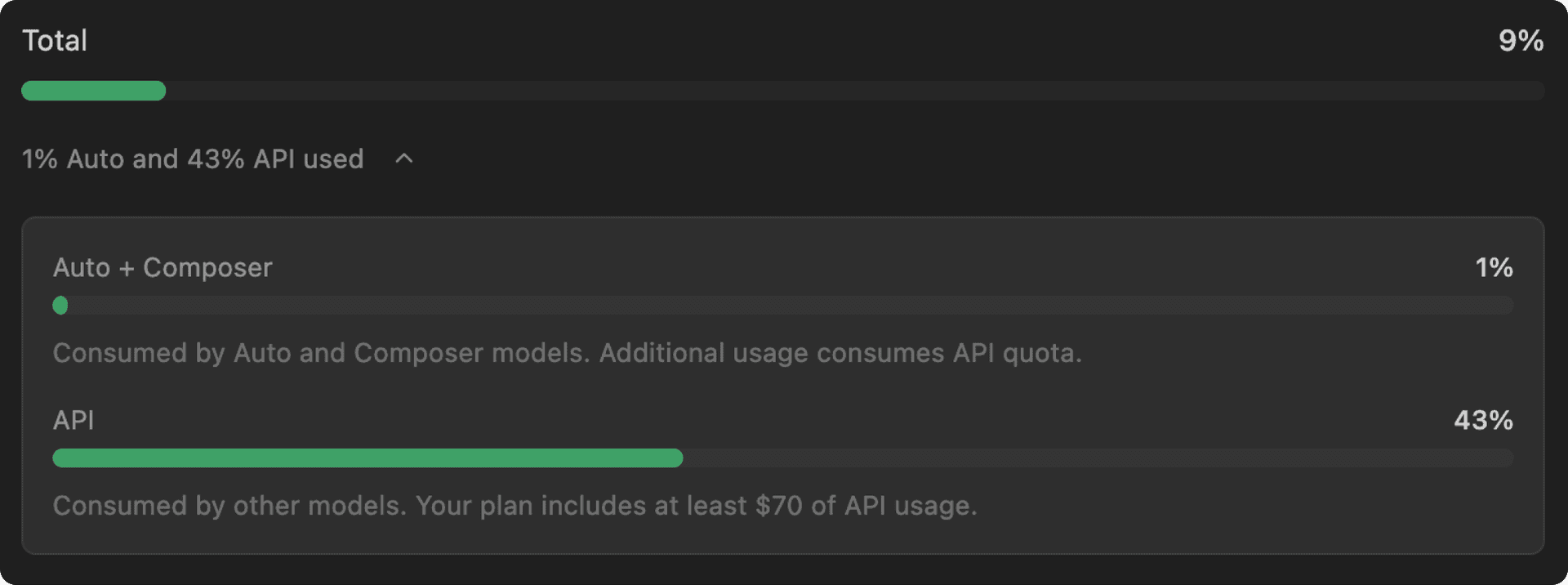
Para melhorar ainda mais a visibilidade de uso, adicionamos uma nova página no editor onde você pode monitorar seus limites em dois pools de uso diferentes:
- Saldo de modelos próprios: No lançamento, incluímos significativamente mais limite de uso quando Auto ou
composer-1.5estava selecionado. - API: Planos individuais incluem pelo menos US$ 20 de uso por mês (mais nos planos superiores), com a opção de pagar por uso adicional conforme necessário. Esses limites de uso não mudaram com esta atualização.

Experimente nosso modelo mais recente
Recomendamos que você experimente o Composer 1.5 com nossos limites de uso atualizados.
Ambos os pools de uso são reiniciados a cada ciclo mensal. Esses limites já estão ativos para todos os planos individuais (Pro, Pro Plus e Ultra).
- Terminal-Bench 2.0 é um benchmark de avaliação de agentes para uso em terminal, mantido pelo Laude Institute. As pontuações dos modelos da Anthropic usam o harness Claude Code e as pontuações dos modelos da OpenAI usam o harness Simple Codex. Nossa pontuação do Cursor foi calculada usando o framework de avaliação Harbor oficial (o harness designado para o Terminal-Bench 2.0), com as configurações padrão do benchmark. Executamos 2 iterações por par modelo-agente e apresentamos a média. Mais detalhes sobre o benchmark podem ser encontrados no site oficial do Terminal Bench. Para outros modelos além do Composer 1.5, usamos a maior pontuação entre o ranking oficial e a pontuação registrada em nossa infraestrutura. ↩