シャドウワークスペースによる反復
典型的な失敗パターンを紹介します。いくつか関連するファイルを Google Doc に貼り付け、そのリンクをあなたのコードベースについて何も知らないお気に入りの p60 ソフトウェアエンジニアに送り、そのドキュメントの中で次の PR を完全かつ正確に実装してほしいと頼むのです。
同じことを AI に頼んでも、予想どおり失敗します。
では代わりに、その人たちにあなたの開発環境へのリモートアクセスを与え、lint の結果を見たり、定義へジャンプしたり、コードを実行したりできるようにしたらどうでしょうか。そうすれば、ある程度は役に立つことを期待できるかもしれません。
私たちは、AI がより多くのコードを書けるようにする要素の 1 つは、開発環境の中で反復できることだと考えています。しかし、単純に AI をあなたのフォルダ内で好き放題にさせると、結果はカオスになります。たとえば、思考を要する関数を書き上げたばかりなのに AI に上書きされてしまったり、あなたがプログラムを実行しようとした瞬間に AI がコンパイルできないコードを挿入してしまったりするかもしれません。本当に役に立つためには、AI の反復作業はバックグラウンドで行われ、あなたのコーディング体験に影響を与えない形で進む必要があります。
これを実現するために、私たちは Cursor に シャドウワークスペース と呼んでいる仕組みを実装しました。このブログ記事では、まずデザイン上の要件を説明し、続いて執筆時点で Cursor に存在している実装 (隠し Electron ウィンドウ) と、今後目指している方向性 (カーネルレベルのフォルダプロキシ) について述べます。

設計上の条件
shadow workspace には、次の目標を達成させたいと考えています。
-
LSP 対応性: AI が自分の変更に対する lint を確認でき、定義ジャンプができ、より一般的には language server protocol (LSP) のあらゆる機能と連携して操作できること。
-
実行可能性: AI が自分で書いたコードを実行し、その出力を確認できること。
まずは LSP 対応性に重点を置きます。
これらの目標は、次の要件を満たしつつ達成される必要があります。
-
独立性: ユーザーのコーディング体験が一切影響を受けないこと。
-
プライバシー: ユーザーのコードが安全であること(例: すべてローカルに保持するなど)。
-
同時実行性: 複数の AI が同時に作業できること。
-
汎用性: すべての言語とあらゆるワークスペース構成で動作すること。
-
保守性: できる限り少ない、かつ分離しやすいコードで実装されていること。
-
速度: どこにも数分単位の遅延がなく、何百もの AI のブランチを処理できるスループットがあること。
これらの多くは、10 万人を超えるユーザー向けのコードエディタを構築する現実を反映しています。私たちは本当に誰のコーディング体験も損ねたくありません。
LSP のユーザビリティを実現する
AI に自身の行った編集に対して lint を走らせることは、基盤となる言語モデルを固定したままコード生成性能を高めるうえで、最も効果の大きい手段の 1 つです。lint によって、9 割動くコードを 10 割動くコードに仕上げられるだけでなく、コンテキストが限られた状況でも非常に役立ちます。そのような状況では、AI は最初の試行でどのメソッドやサービスを呼び出すべきかについて、ある程度当たりを付けて決めなければならないことがあります。lint は、AI が追加の情報を求める必要がある箇所を特定するのに役立ちます。

LSP-usability の実現は runnability よりも簡単です。というのも、ほとんどすべての language server はファイルシステムに書き込まれていないファイルでも処理できるからです(そして後で見るように、ファイルシステムを関与させると事態はかなり複雑になります)。そこでまずはここから始めましょう。5 つ目の要件である maintainability の観点からも、私たちはまず、可能な限り単純な解決策から試しました。
うまくいかない単純な解決策
Cursor は VS Code のフォークであるため、言語サーバーには非常に簡単にアクセスできます。VS Code では、開いている各ファイルは TextModel オブジェクトとして表現されており、そのオブジェクトがファイルの現在の状態をメモリ上に保持します。言語サーバーはディスクからではなくこれらの TextModel オブジェクトから読み取ることで、(保存したときだけでなく)入力中に補完やリントを返すことができます。
AI がファイル lib.ts に編集を加えるとします。ユーザーが同時にそのファイルを編集しているかもしれないので、lib.ts に対応する既存の TextModel オブジェクトを書き換えることは明らかにできません。とはいえ、もっともらしい案として、TextModel オブジェクトのコピーを作り、そのコピーをディスク上の実ファイルから切り離して、AI がそのオブジェクトに対して編集を行いリントを受け取れるようにする、というものが考えられます。これは次の 6 行のコードで実現できます。
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// インメモリのTextModelのコピーを作成し、AIの編集を適用
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// 言語サーバーが新しいTextModelオブジェクトを処理できるように2秒待機
await new Promise((resolve) => setTimeout(resolve, 2000));
// マーカーサービスからリントを読み取る(内部的には言語に基づいて適切な拡張機能にルーティングされる)
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}この解決策は、保守性の観点では明らかに抜群です。ほとんどのユーザーは、すでに自分のプロジェクト向けに適切な言語別拡張機能をインストールして設定しているので、汎用性の面でも優れています。並行性とプライバシーについても、ほとんど自明に満たせます。
問題は独立性です。TextModel のコピーを作成することで、ユーザーが編集中のファイル自体を直接変更してはいないものの、コピーしたファイルの存在を、ユーザーが使っているのと同じ言語サーバーに知らせてしまっています。これによって問題が発生します。go-to-references の結果にコピーしたファイルが含まれてしまったり、Go のように複数ファイルにまたがるデフォルトの名前空間スコープを持つ言語では、コピーしたファイルとユーザーが編集している元のファイルの両方で、すべての関数について宣言が重複しているとエラーになったりします。また、Rust のように、どこか別の場所で明示的にインポートされている場合にのみファイルが取り込まれる言語では、まったくエラーが出なかったりします。おそらく、この種の問題は他にもたくさんあります。
これらの問題は些細に聞こえるかもしれませんが、独立性は私たちにとって絶対に重要です。通常のコード編集体験をほんの少しでも劣化させてしまうと、AI 機能がどれだけ優れていても意味がありません。私自身を含め、人々は単に Cursor を使わなくなるでしょう。
私たちは、最終的にはうまくいかない他の案もいくつか検討しました。VS Code のインフラストラクチャの外側で独自に tsc や gopls や rust-analyzer のインスタンスを起動する案、すべての VS Code 拡張機能が動作する extension host プロセス自体を複製して、各言語サーバー拡張機能を 2 つずつ実行できるようにする案、そして、よく使われている言語サーバーをすべてフォークして複数バージョンのファイルをサポートできるようにし、それらの拡張機能を Cursor に同梱する案などです。
現在のシャドウワークスペース実装
最終的に、シャドウワークスペースは「非表示ウィンドウ」として実装しました。AI が自分で書いたコードに対するリントを確認したいとき、そのワークスペース用の非表示ウィンドウを生成し、そのウィンドウ側で編集を行い、そこで得られたリントを報告します。非表示ウィンドウはリクエスト間で使い回します。これにより、すべての要件を(ほぼ*)完全に満たしつつ、(ほぼ*)LSP をほぼフルに活用できる状態が得られます。アスタリスクについては後ほど説明します。
簡略化したアーキテクチャ図を図4に示します。
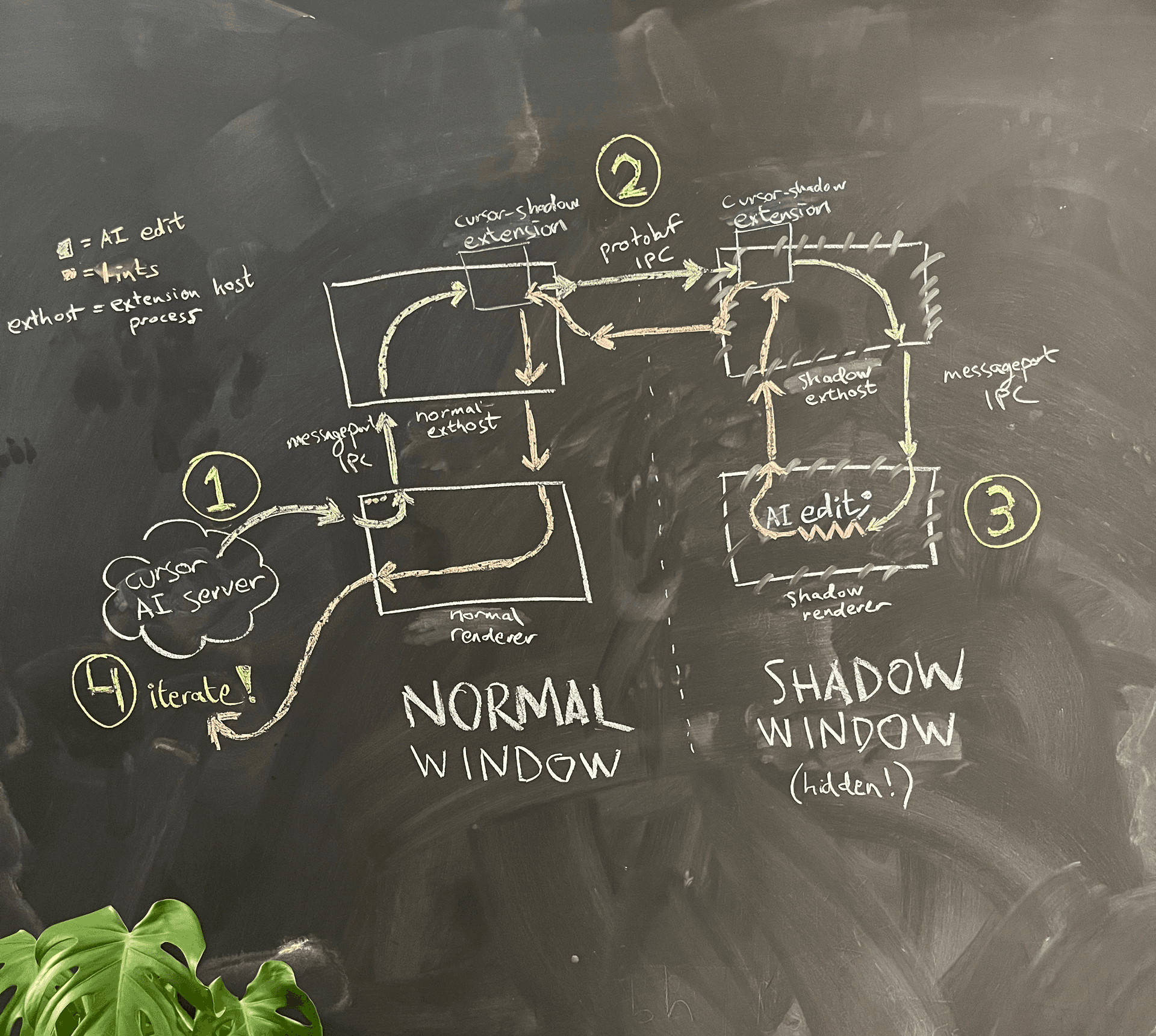
AI は通常ウィンドウのレンダラープロセス内で動作しています。AI が自分で書いたコードに対するリントを確認したいとき、レンダラープロセスはメインプロセスに対して、同じフォルダ内に非表示のシャドウウィンドウを生成するよう要求します。
Electron のサンドボックス化のため、2 つのレンダラープロセスは互いに直接通信できません。検討した選択肢のひとつは、VS Code が実装している、レンダラープロセスが extension host プロセスと通信できるようにする慎重に組まれた message port 作成ロジックを再利用し、それを使って通常ウィンドウとシャドウウィンドウ間に独自の message port IPC を作る、というものでした。しかし、その保守コストを懸念し、私たちはハック寄りの方法を選びました。すなわち、既存の「レンダラープロセス → extension host」向け message port IPC を再利用し、その後は extension host 同士の間を独立した IPC 接続で通信するという方法です。そこに、ちょっとした使い勝手向上も紛れ込ませました。VS Code 独自の、やや壊れやすい JSON シリアライゼーションロジックではなく、私たちが大好きな gRPC と buf を使って通信できるようになったのです。
この構成は、自然とかなり保守しやすいものになります。追加したコードは他のコードから独立しており、ウィンドウを非表示にするために必要な中核コードは 1 行だけだからです(Electron でウィンドウを開く際に show: false というパラメータを渡せば非表示にできます)。これにより、汎用性とプライバシーは自明に満たされます。
幸いなことに、「独立性」も満たされます。新しいウィンドウはユーザーから完全に独立しているので、AI は自由に好きな変更を行い、その結果のリントを取得できます。ユーザーがそれに気づくことはありません。
シャドウウィンドウには懸念点がひとつあります。新しいウィンドウは、素朴に考えるとメモリ使用量が 2 倍になる、という点です。この影響を抑えるため、シャドウウィンドウで実行を許可する拡張機能を制限し、15 分間アクティビティがなければ自動的に強制終了し、さらにオプトイン制にしています。それでも、同時実行という観点では課題になります。単純に AI ごとに新しいシャドウウィンドウを生成する、というわけにはいきません。幸運なことに、ここでは AI と人間の決定的な違いのひとつを活かせます。AI は、いくらでも長時間ポーズさせても、それに気づきもしないのです。具体的には、2 つの AI A と B がいて、それぞれが A1, A2 および B1, B2 という編集を順に提案する場合、それらの編集はインターリーブできます。シャドウウィンドウはまずフォルダ全体の状態を A1 にリセットし、リントを取得して A に返します。次にフォルダ全体の状態を B1 にリセットし、リントを取得して B に返します。A2 と B2 についても、同様に繰り返します。この意味で、AI は(CPU によってこのようにインターリーブされても気づかない)コンピュータプロセスに近く、本質的な時間感覚を持つ人間とは異なります。
これらすべてを組み合わせることで、バックグラウンドで動く AI がユーザーに一切影響を与えることなく自分の編集を洗練させるために利用できる、シンプルな Protobuf API を提供できるようになりました。
予告していた補足: 一部の言語サーバーは、リントを報告する前にコードが一度ディスクに書き出されていることを前提としています。代表的な例は rust-analyzer 言語サーバーで、これはプロジェクトレベルの cargo check を実行してリントを取得するだけであり、VS Code の仮想ファイルシステムと統合されていません(参考としてこの issueを参照してください)。そのため、ユーザーが非推奨の RLS 拡張機能を利用している場合を除き、シャドウワークスペースは Rust に対する LSP としての利用をまだサポートしていません。
実行性の実現
実行性の話になると、途端におもしろくもあり、同時に複雑にもなってきます。現在 Cursor では、長時間連続で動き続けるような AI ではなく、比較的短い時間スケールで動作する AI にフォーカスしています。つまり、あなたがそれらを使っている間にバックグラウンドで関数の実装を書いてくれる、といった使い方であり、最初から最後まで PR 全体を自動で実装してしまうようなものではありません。そのため、この「実行性」自体はまだ実装していません。とはいえ、それをどう実現できるかを考えてみるのはおもしろい題材です。
コードを実行するには、それをファイルシステムに保存する必要があります。多くのプロジェクトでは、ディスクに対する副作用(ビルドキャッシュやログファイルなど)も発生します。したがって、もはやユーザーと同じフォルダ内でシャドウウィンドウを起動することはできません。すべてのプロジェクトで完全な実行性を実現するにはネットワークレベルでのアイソレーションも必要ですが、ここではディスクのアイソレーションの実現に焦点を当てます。
最もシンプルなアイデア: cp -r
最もシンプルなアイデアは、ユーザーのフォルダを再帰的に /tmp の場所へコピーし、そこで AI による編集を適用してファイルを保存し、その場でコードを実行するというものです。別の AI による次の編集の際には、rm -rf を実行してから新たに cp -r を実行し、シャドウワークスペースがユーザーのワークスペースと常に同期している状態を保ちます。
問題は速度です。cp -r は非常に遅い処理です。プロジェクトを実行できるようにするには、ソースコードだけでなく、ビルド関連の付随ファイルもすべてコピーする必要がある、という点を忘れてはいけません。具体的には、JavaScript プロジェクトでは node_modules、Python プロジェクトでは venv、Rust プロジェクトでは target をコピーする必要があります。これらは一般的に、中規模プロジェクトであっても巨大なフォルダになるため、単純な cp -r アプローチは現実的ではなくなってしまいます。
シンボリックリンク、ハードリンク、コピーオンライト
大きなフォルダ構造をコピーしたり作成したりする処理は、必ずしもものすごく遅い必要はありません。その実例が bun で、node_modules にキャッシュ済み依存関係をインストールするのに、サブ秒オーダーで済むことも多くあります。Linux ではハードリンクを使っており、実際のデータ移動がないため高速です。macOS では、比較的最近追加された clonefile syscall を使っていて、ファイルやフォルダのコピーオンライトを実行します。
残念ながら、私たちのそこそこ大きなモノレポでは、cp -c による clonefile でさえ完了まで 45 秒かかります。これは、すべてのシャドウワークスペース要求の前に実行するには遅すぎます。ハードリンクは、シャドウフォルダ内で実行した処理が誤って元のリポジトリ内の実ファイルを変更してしまう可能性があるため、扱いづらい選択肢です。シンボリックリンクも同様で、さらに透過的には扱われないという追加の問題があります。そのため、しばしば追加の設定が必要になります(例: Node.js の --preserve-symlinks フラグ)。
clonefile(あるいは単純な cp -r でも)を使いつつ、フォルダを毎回コピーし直さなくて済むようにする賢い管理スキームと組み合わせれば、うまくいくかもしれません。正しさを保証するには、最後にフルコピーを行ってからユーザーフォルダ内で行われたすべてのファイル変更と、コピー先フォルダ内でのすべてのファイル変更を監視し、各リクエストの前に後者を取り消して前者を再適用する必要があります。どちらか一方の変更履歴が追跡しきれないほど大きくなった場合には、新たにフルコピーを実行して状態をリセットします。これは動作するかもしれませんが、バグが入り込みやすく、壊れやすく、そして率直に言えば、こんなにシンプルそうなことを達成するにはあまりスマートではないアプローチに感じられます。
本当に欲しいもの: カーネルレベルのフォルダプロキシ
本当に欲しいものはシンプルです。通常のファイルシステムAPIを使っているあらゆるアプリケーションから見ると、シャドウフォルダ A′ がユーザーのフォルダ A とまったく同一に見えつつ、一部のオーバーライド用ファイルだけを手早く設定でき、その内容はディスクではなくメモリから読み出されるようにしたいのです。また、フォルダ A′ への書き込みはディスクではなくメモリ上のオーバーライドストアに書き込まれるようにしたい。要するに、設定可能なオーバーライドを備えたプロキシフォルダが欲しく、そのオーバーライドテーブルはすべてメモリ上に保持できれば十分です。そうすれば、このプロキシフォルダ内にシャドウウィンドウを起動して、ディスクレベルで完全に独立した環境を実現できます。
重要なのは、このフォルダプロキシに対してカーネルレベルのサポートが必要になる点です。そうすることで、動作中のコードは read や write システムコールを一切変更せずに呼び続けられます。1つのアプローチは、カーネルの仮想ファイルシステム内でシャドウフォルダのバックエンドとして自らを登録するカーネル拡張 13 を作成し、上で述べたシンプルな挙動を実装することです。
Linux では、代わりにユーザ空間でこれを実現できます。FUSE(「Filesystem in Userspace」)を使う方法です。FUSE はほとんどのLinuxディストリビューションに標準で含まれているカーネルモジュールで、ファイルシステムコールをユーザ空間プロセスへプロキシします。これにより、フォルダプロキシの実装はさらに簡単になります。フォルダプロキシの簡易的な実装は次のようになります。ここでは C++ で示します。
まず、FUSEカーネルモジュールとの通信を担うユーザ空間のFUSEライブラリをインポートします。また、対象フォルダ(ユーザーのフォルダ)と、メモリ上のオーバーライドマップを定義します。
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// その他のインクルード...
using namespace std;
// 変更を加えないプロキシ対象フォルダ
string target_folder = "/path/to/target/folder";
// 適用するメモリ内オーバーライド
unordered_map<string, vector<char>> overrides;次に、オーバーライドにそのパスが含まれているかを確認するカスタムの read 関数を定義し、含まれていなければターゲットフォルダから読み込むだけにします。
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// パスがオーバーライドに含まれているかチェック
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// 含まれていれば、オーバーライドの内容を返す
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// それ以外の場合は、プロキシフォルダからファイルを開いて読み取る
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}カスタムの write 関数は、オーバーライドマップに単に書き込むだけです。
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 常にオーバーライドに書き込む
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}最後に、独自関数を FUSE に登録します。
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}実際の実装では、readdir や getattr、lock を含む FUSE API 全体を実装する必要がありますが、それぞれの関数は上で示したものと非常によく似たものになります。新しいリントのリクエストごとに、その AI 固有の編集内容だけを反映するように overrides map をリセットすればよく、これは即座に行えます。メモリ使用量の暴走を確実に防ぎたい場合は、追加の管理処理を行いつつ、overrides map をディスク上に保持しておくこともできます。
環境を完全に制御できるのであれば、FUSE による追加のユーザー空間とカーネル空間のコンテキストスイッチによるオーバーヘッドを避けるために、代わりにネイティブなカーネルモジュールとして実装したいと考えるでしょう。14
…しかし:ウォールドガーデン
Linux では FUSE フォルダプロキシはとてもよく動作しますが、私たちのユーザーの大半は macOS か Windows を使っており、どちらにも FUSE の標準実装は搭載されていません。残念ながら、カーネル拡張を同梱することも選択肢に入れられません。Apple Silicon 搭載の Mac では、ユーザーがカーネル拡張をインストールする唯一の方法は、特別なキーを押しながらコンピュータを再起動してリカバリモードに入り、「Reduced Security(セキュリティを低にする)」へダウングレードすることです。これではとても製品として出荷できません!
FUSE は一部をカーネル内で動かす必要があるため、macFUSE のようなサードパーティの FUSE 実装も、ユーザーにインストールしてもらうのがほぼ不可能、という同じ問題を抱えています。
この制約を回避するために、いくつかクリエイティブな試みがなされてきました。ひとつのアプローチは、macOS がネイティブにサポートしているネットワークベースのファイルシステム(例えば NFS や SMB)を使い、その下に FUSE API をかぶせるというものです。xetdata/nfsserve では、NFS の上に構築された FUSE ライクな API を持つローカルサーバーのオープンソースの PoC が公開されており、クローズドソースプロジェクトの macOS-FUSE-t は、NFS と SMB の両方の上に構築されたバックエンドをサポートしています。
これで問題解決? そう簡単ではありません……。ファイルシステムは、ファイルの読み書きや一覧取得以上にずっと複雑です! ここでは、xetdata/nfsserve が依拠している古いバージョンの NFS がファイルロックをサポートしていないため、Cargo が失敗しています。

MacOS-FUSE-t はファイルロックを サポートする NFSv4 の上に構築されていますが、GitHub リポジトリにはソースコードではない 3 つのファイル(Attributions.txt, License.txt, README.md)しかなく、作成者も macos-fuse-t といういかにも単一用途っぽいユーザー名の GitHub アカウントで、それ以上の情報はありません。当然ながら、そんな正体不明のバイナリをユーザーに配布することはできません……。また、オープンな issue からは、NFS/SMB ベースのアプローチに、主に Apple の カーネルバグ に起因する、より根本的な問題があることも示唆されています。
では、私たちに残された選択肢は何でしょうか? まったく新しいクリエイティブなアプローチか、15 年待つか、あるいは……ポリティクスです! Apple はここ 10 年以上かけてカーネル拡張を段階的に廃止する取り組みを進めてきており、その過程で DriverKit のようなユーザーレベルの API を次々に公開し、古いファイルシステムに対するビルトインサポートも、最近では ユーザーランド実装へと切り替えられました。Apple のオープンソースの MS-DOS コードには、FSKit という名前のプライベートフレームワークへの参照がここに含まれており、非常に有望に思えます! 少しポリティクスをがんばって Apple に働きかければ、FSKit を外部開発者向けに仕上げて公開してもらえるかもしれない(あるいは、すでにその計画があるのかもしれない)と感じています。その場合、macOS における「実行可能性」の問題にも、ひとつの解決策が見えてくるかもしれません。
未解決の疑問
これまで見てきたように、AI がバックグラウンドでコードを繰り返し編集できるようにするという一見シンプルな問題は、実際にはかなり複雑です。shadow workspace は、AI に Lint 結果を表示するという当面のニーズを満たすために、1 週間・1 人で実装したプロジェクトでした。将来的には、実行可能性の問題も解決できるよう拡張する予定です。いくつか未解決の疑問があります:
-
kernel extension を作成したり FUSE API を使ったりせずに、検討しているようなシンプルなプロキシフォルダを実現する別の方法はあるでしょうか?FUSE はより大きな問題(あらゆる種類のファイルシステム)を解決しようとしているため、一般的な FUSE 実装では動作しないものの、私たちのフォルダプロキシには使えるような、macOS や Windows 上のマイナーな API が存在していてもおかしくないと感じています。
-
Windows 上では、このプロキシフォルダは具体的にどのような形になるのでしょうか?WinFsp のようなものがそのまま動作するのか、それともインストール、パフォーマンス、セキュリティに関する問題があるのでしょうか?私は主に、macOS 上でフォルダプロキシを実現する方法を調査することに時間を費やしました。
-
もしかすると、macOS で DriverKit を使い、仮想的な USB デバイスをシミュレーションしてプロキシフォルダとして機能させる方法があるかもしれません。可能性は低いと思っていますが、不可能だと言い切れるほどには API を詳しく調べていません。
-
ネットワークレベルでの独立性をどのように達成できるでしょうか?考慮すべき特定の状況として、コードが 3 つのマイクロサービスに分割されている統合テストを AI がデバッグしたい場合があります。16 より VM に近いアプローチが必要になる可能性もありますが、その場合は環境セットアップ全体とインストール済みソフトウェアの同等性を保証するために、より多くの作業が必要になります。
-
ユーザー側のセットアップをできるだけ少なく抑えつつ、ユーザーのローカルのワークスペースと同一のリモートワークスペースを作成する方法はあるでしょうか?クラウドであれば、政治的な調整を一切せずに、FUSE をそのまま使うことも(パフォーマンス目的であれば kernel module さえも)可能であり、ユーザー側の追加メモリ使用をゼロにしつつ、完全な独立性も保証できます。プライバシーをあまり気にしないユーザーにとっては、これは良い代替案になり得ます。ひとつのプロトタイプ的なアイデアとして、システムを観察することで自動的に推論される Docker コンテナがあります(おそらく、マシン上で何が動いているかを検出するスクリプトを書き、それと併せて言語モデルを使って Dockerfile を生成する、といった組み合わせです)。
これらの問いについて良いアイデアがあれば、arvid@cursor.com までメールをください。また、このようなテーマに取り組みたい場合は、we’re hiring もぜひご覧ください。