शैडो वर्कस्पेस के साथ इटरेशन
विफलता का एक पक्का नुस्खा यह है: कुछ प्रासंगिक फ़ाइलें Google Doc में पेस्ट करें, उसका लिंक अपने पसंदीदा p60 सॉफ़्टवेयर इंजीनियर को भेजें, जो आपके कोडबेस के बारे में कुछ नहीं जानता, और उससे कहें कि वह आपके अगले PR को पूरी तरह और सही तरीके से उसी Doc के अंदर लागू कर दे।
किसी AI से यही काम करने को कहें, तो वह भी अनुमान के मुताबिक विफल होगा।
अब इसकी बजाय उन्हें आपके विकास परिवेश तक रिमोट पहुँच दें, ताकि वे lint देख सकें, definitions पर जा सकें, और कोड चला सकें—तब आप सच में उनसे कुछ हद तक मददगार होने की उम्मीद कर सकते हैं।
हमारा मानना है कि AI को आपका अधिक कोड लिखने में सक्षम बनाने वाली चीज़ों में से एक है आपके विकास परिवेश में इटरेट करने की क्षमता। लेकिन अगर AI को यूँ ही आपके फ़ोल्डर में खुला छोड़ दिया जाए, तो नतीजा अराजकता होता है: ज़रा सोचिए, आप कोई तर्क-गहन फ़ंक्शन लिख रहे हों और AI उसे ओवरराइट कर दे, या आप अपना प्रोग्राम चलाने की कोशिश करें और AI ऐसा कोड जोड़ दे जो compile ही न हो। सचमुच उपयोगी होने के लिए, AI का यह इटरेशन पृष्ठभूमि में होना चाहिए, बिना आपके कोडिंग अनुभव को प्रभावित किए।
इसे संभव बनाने के लिए, हमने Cursor में वह लागू किया है जिसे हम शैडो वर्कस्पेस कहते हैं। इस ब्लॉग पोस्ट में, मैं पहले हमारे डिज़ाइन मानदंडों की रूपरेखा बताऊँगा, फिर उस implementation का वर्णन करूँगा जो लिखे जाने के समय Cursor में मौजूद है (एक छिपी हुई Electron विंडो), और यह भी कि भविष्य में हम इसे कहाँ ले जाना चाहते हैं (एक कर्नेल-स्तर का फ़ोल्डर प्रॉक्सी)।

डिज़ाइन मानदंड
हम चाहते हैं कि शैडो कार्यस्थान निम्नलिखित लक्ष्य हासिल करे:
-
LSP-उपयोगिता: AI को अपने परिवर्तनों से उत्पन्न lint दिखने चाहिए, वे definitions पर जा सकें, और सामान्य रूप से language server protocol (LSP) के सभी हिस्सों के साथ इंटरैक्ट कर सकें।
-
चलने-योग्यता: AI अपना कोड चला सकें और आउटपुट देख सकें।
शुरुआत में, हमारा ध्यान LSP-उपयोगिता पर है।
इन लक्ष्यों को निम्नलिखित आवश्यकताओं के अधीन हासिल किया जाना चाहिए:
-
स्वतंत्रता: उपयोगकर्ता का कोडिंग अनुभव प्रभावित नहीं होना चाहिए।
-
गोपनीयता: उपयोगकर्ता का कोड सुरक्षित होना चाहिए (उदाहरण के लिए, उसका पूरी तरह local रहना)।
-
समांतरता: कई AI एक साथ अपना काम कर सकें।
-
सार्वभौमिकता: यह सभी भाषाओं और सभी कार्यस्थान सेटअप के लिए काम करना चाहिए।
-
रखरखाव-योग्यता: इसे यथासंभव कम और आसानी से अलग किए जा सकने वाले कोड के साथ लिखा जाना चाहिए।
-
गति: कहीं भी मिनटों की देरी नहीं होनी चाहिए, और AI की सैकड़ों ब्रांचों के लिए पर्याप्त थ्रूपुट होना चाहिए।
इनमें से कई बातें एक लाख से अधिक उपयोगकर्ताओं के लिए कोड एडिटर बनाने की वास्तविकता को दर्शाती हैं। हम सचमुच किसी के भी कोडिंग अनुभव पर नकारात्मक असर नहीं डालना चाहते।
LSP-usability प्राप्त करना
AI को अपने संपादनों के लिए लिंट्स पाने देना, अंतर्निहित भाषा मॉडल को स्थिर रखते हुए, कोड जनरेशन के प्रदर्शन को बेहतर बनाने के सबसे प्रभावशाली तरीकों में से एक है। लिंट्स न केवल 90% काम करने वाले कोड को 100% काम करने वाले कोड तक पहुँचाने में मदद करते हैं, बल्कि वे संदर्भ-सीमित परिस्थितियों में भी बहुत उपयोगी होते हैं, जब AI को पहली ही कोशिश में यह सोच-समझकर अनुमान लगाना पड़ सकता है कि किस method या सेवा को कॉल करना है। लिंट्स उन जगहों की पहचान करने में भी मदद कर सकते हैं जहाँ AI को अधिक जानकारी माँगने की आवश्यकता है।

LSP-usability, चलने-योग्यता की तुलना में अधिक सरल भी है, क्योंकि लगभग सभी language server उन फ़ाइलों पर काम कर सकते हैं जिन्हें फ़ाइल सिस्टम में लिखा नहीं गया है (और जैसा कि हम आगे देखेंगे, फ़ाइल सिस्टम को शामिल करने से चीज़ें काफ़ी अधिक कठिन हो जाती हैं)। इसलिए शुरुआत यहीं से करते हैं! हमारी पाँचवीं आवश्यकता, maintainability, की भावना के अनुरूप, हमने पहले सबसे सरल संभव समाधानों को आज़माया।
वे सरल समाधान जो काम नहीं करते
Cursor, VS Code का एक फ़ोर्क होने के कारण, हमें language servers तक पहले से ही बहुत आसान पहुँच मिल जाती है। VS Code में, हर खुली फ़ाइल को एक TextModel ऑब्जेक्ट के रूप में दर्शाया जाता है, जो मेमोरी में फ़ाइल की वर्तमान स्थिति को संग्रहीत करता है। Language servers डिस्क के बजाय इन text model ऑब्जेक्ट्स से पढ़ते हैं, इसलिए वे आपके टाइप करते समय completions और lints दे पाते हैं (सिर्फ़ सहेजने पर नहीं)।
मान लीजिए कोई AI फ़ाइल lib.ts में संपादन करता है। जाहिर है, हम lib.ts से जुड़े मौजूदा TextModel ऑब्जेक्ट को संशोधित नहीं कर सकते, क्योंकि हो सकता है उपयोगकर्ता भी उसी समय उसे संपादित कर रहा हो। फिर भी, एक सुनने में उचित लगने वाला विचार यह है कि TextModel ऑब्जेक्ट की एक कॉपी बनाई जाए, उस कॉपी को डिस्क पर मौजूद किसी वास्तविक फ़ाइल से अलग कर दिया जाए, और AI को उसी ऑब्जेक्ट पर संपादन करने और उससे lints प्राप्त करने दिया जाए। यह नीचे दी गई 6 पंक्तियों के कोड से किया जा सकता है।
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// कॉपी किया गया इन-मेमोरी TextModel बनाएँ और उस पर AI संपादन लागू करें
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// language सर्वर को नए TextModel ऑब्जेक्ट को प्रोसेस करने के लिए 2 सेकंड प्रतीक्षा करें
await new Promise((resolve) => setTimeout(resolve, 2000));
// marker सेवा से lints पढ़ें, जो आंतरिक रूप से भाषा के आधार पर सही एक्सटेंशन पर रूट करती है
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}रखरखाव की दृष्टि से यह समाधान स्पष्ट रूप से बेहतरीन है। सार्वभौमिकता के लिहाज़ से भी यह बहुत अच्छा है, क्योंकि ज़्यादातर लोग अपने प्रोजेक्ट के लिए सही भाषा-विशिष्ट एक्सटेंशन पहले से इंस्टॉल और कॉन्फ़िगर कर चुके होंगे। समांतरता और गोपनीयता की ज़रूरतें भी आसानी से पूरी हो जाती हैं।
समस्या स्वतंत्रता की है। TextModel की एक कॉपी बनाने का मतलब यह है कि हम उपयोगकर्ता द्वारा संपादित की जा रही फ़ाइल को सीधे संशोधित नहीं कर रहे हैं, लेकिन फिर भी हम भाषा सर्वर को — उसी भाषा सर्वर को, जिसका उपयोग उपयोगकर्ता कर रहा है — अपनी कॉपी की गई फ़ाइल के अस्तित्व के बारे में बता देते हैं। इससे समस्याएँ पैदा होती हैं: go-to-references के नतीजों में हमारी कॉपी की गई फ़ाइल भी शामिल होगी; Go जैसी भाषाएँ, जिनमें डिफ़ॉल्ट रूप से बहु-फ़ाइल namespace scope होता है, कॉपी की गई फ़ाइल और उस मूल फ़ाइल दोनों में मौजूद सभी functions के लिए duplicated declarations की शिकायत करेंगी, जिन्हें उपयोगकर्ता संपादित कर रहा हो सकता है; और Rust जैसी भाषाएँ, जिनमें फ़ाइलें केवल तभी शामिल होती हैं जब उन्हें कहीं और स्पष्ट रूप से import किया गया हो, आपको कोई भी त्रुटि नहीं देंगी। संभव है कि ऐसी और भी बहुत-सी समस्याएँ हों।
आपको लग सकता है कि ये समस्याएँ मामूली हैं, लेकिन हमारे लिए स्वतंत्रता बिल्कुल निर्णायक है। अगर हम कोड संपादित करने के सामान्य अनुभव को ज़रा-सा भी खराब कर दें, तो हमारी AI सुविधाएँ कितनी भी अच्छी क्यों न हों — लोग, जिनमें मैं खुद भी शामिल हूँ, Cursor का उपयोग ही नहीं करेंगे।
हमने कुछ और विचारों पर भी विचार किया, जो आखिरकार असफल ही साबित हुए: VS Code अवसंरचना के बाहर अपने खुद के tsc, gopls, या rust-analyzer instances स्पॉन करना; extension host प्रक्रिया की नकल करना, जहाँ सभी VS Code एक्सटेंशन चलाए जाते हैं, ताकि हम हर language server extension की दो प्रतियां चला सकें; और सभी लोकप्रिय language servers को फ़ोर्क करके फ़ाइलों के कई अलग-अलग versions का समर्थन जोड़ना, और फिर उन एक्सटेंशन को Cursor में bundle करना।
वर्तमान shadow workspace इम्प्लीमेंटेशन
आख़िरकार, हमने shadow workspace को एक hidden window के रूप में कार्यान्वित किया: जब भी कोई AI अपने लिखे हुए कोड के lints देखना चाहता है, हम मौजूदा workspace के लिए एक hidden window स्पॉन करते हैं, और फिर उसी विंडो में संपादन करके lints वापस रिपोर्ट करते हैं। हम अनुरोधों के बीच इस hidden window का पुन: उपयोग करते हैं। इससे हमें (लगभग*) पूरी LSP-उपयोगिता मिल जाती है, जबकि लगभग सभी आवश्यकताएँ (लगभग*) पूरी हो जाती हैं। तारांकन चिह्नों पर आगे चर्चा की गई है।
एक सरलीकृत architecture diagram Figure 4 में दिखाया गया है।
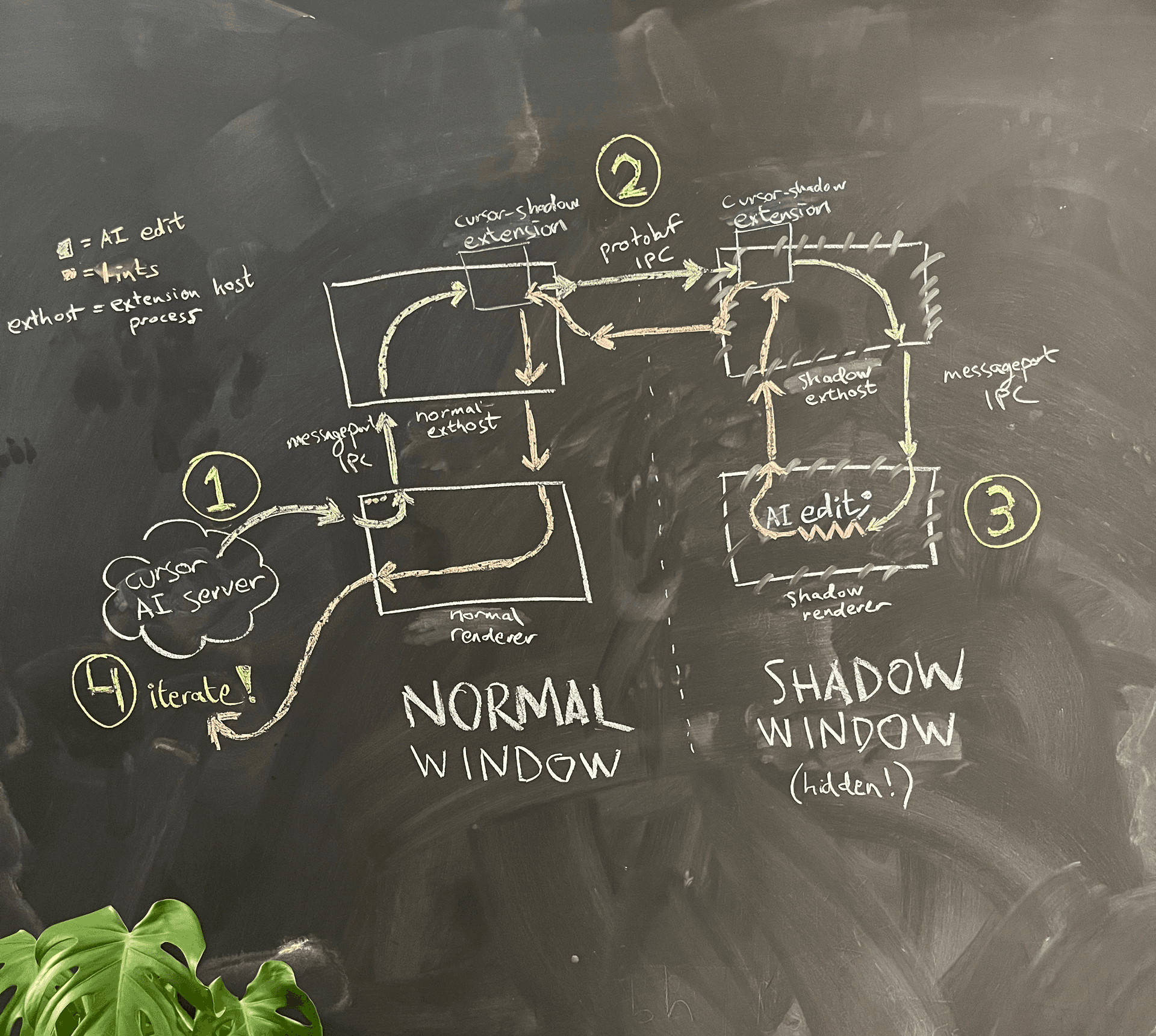
AI सामान्य विंडो के renderer process में चल रहा होता है। जब वह अपने लिखे हुए कोड के lints देखना चाहता है, तो renderer process main process से उसी फ़ोल्डर में एक hidden shadow window स्पॉन करने के लिए कहता है।
Electron sandboxing की वजह से, दोनों renderer process आपस में सीधे संवाद नहीं कर सकते। एक विकल्प, जिस पर हमने विचार किया, यह था कि VS Code द्वारा कार्यान्वित उस सावधानीपूर्वक message port creation logic का पुन: उपयोग किया जाए, जो renderer process को extension host process से संवाद करने देती है, और उसका इस्तेमाल सामान्य विंडो और shadow window के बीच अपना message port IPC बनाने के लिए किया जाए। रखरखाव का बोझ बढ़ने की आशंका को देखते हुए, हमने एक hack चुना: हम renderer process से extension host तक पहले से मौजूद message port IPC का पुन: उपयोग करते हैं, और फिर extension host से extension host के बीच एक स्वतंत्र IPC connection के ज़रिए संवाद करते हैं। वहीं, हमने एक quality-of-life improvement भी जोड़ दी: अब हम संवाद के लिए gRPC और buf (जो हमें बहुत पसंद हैं) का उपयोग कर सकते थे, VS Code की कस्टम और कुछ हद तक नाज़ुक JSON serialization logic के बजाय।
यह setup अपने-आप में काफ़ी maintainable है, क्योंकि जो कोड जोड़ा गया है वह दूसरे कोड से स्वतंत्र है, और विंडो को छिपाने के लिए आवश्यक मुख्य कोड सिर्फ़ एक पंक्ति का है (Electron में विंडो खोलते समय, आप उसे छिपाने के लिए show: false पैरामीटर दे सकते हैं)। यह आसानी से सार्वभौमिकता और गोपनीयता, दोनों आवश्यकताएँ पूरी कर देता है।
सौभाग्य से, स्वतंत्रता की शर्त भी पूरी होती है! नई विंडो उपयोगकर्ता से पूरी तरह स्वतंत्र है, इसलिए AI बिना किसी बाधा के जो भी परिवर्तन करना चाहे कर सकता है और उनके lints पा सकता है। उपयोगकर्ता को कुछ भी पता नहीं चलेगा।
हालाँकि, shadow window के साथ एक चिंता ज़रूर है: यह नई विंडो सीधे-सीधे मेमोरी उपयोग में 2x वृद्धि ले आती है। हम इसका प्रभाव इस तरह घटाते हैं कि shadow window में चलने वाले एक्सटेंशन सीमित रखते हैं, 15 मिनट की निष्क्रियता के बाद इसे अपने-आप बंद कर देते हैं, और यह सुनिश्चित करते हैं कि यह opt-in हो। फिर भी, concurrency के लिए यह एक चुनौती है: हम हर AI के लिए बस एक नई shadow window स्पॉन नहीं कर सकते। सौभाग्य से, यहाँ हम AI और मानव के बीच एक अहम अंतर का लाभ उठा सकते हैं: AI को अनिश्चित समय तक pause किया जा सकता है, और उसे इसका एहसास भी नहीं होता। खास तौर पर, अगर आपके पास दो AI, A और B हैं, जो क्रमशः A1 के बाद A2 और B1 के बाद B2 संपादन प्रस्तावित कर रहे हैं, तो आप उन संपादनों को interleave कर सकते हैं। shadow window पहले पूरे फ़ोल्डर की स्थिति को A1 पर reset करती है, lints प्राप्त करती है, और उन्हें A को लौटा देती है। फिर वह पूरे फ़ोल्डर की स्थिति को B1 पर reset करती है, lints प्राप्त करती है, और उन्हें B को लौटा देती है। इसी तरह A2 और B2 के साथ यह क्रम चलता रहता है। इस मायने में, AI मानवों की तुलना में कंप्यूटर प्रक्रियाओं के ज़्यादा समान हैं (जिन्हें भी CPU इसी तरह interleave करता है और उन्हें इसका पता नहीं चलता), क्योंकि मानवों में समय का एक अंतर्निहित बोध होता है।
इन सबको मिलाकर, हमें एक सरल Protobuf API मिलती है, जिसका उपयोग हमारे background AI उपयोगकर्ता को बिल्कुल भी प्रभावित किए बिना अपने संपादनों को परिष्कृत करने के लिए कर सकते हैं।
अब उन तारांकन-चिह्नों की बात, जिनका वादा किया गया था: कुछ language server लिंट्स रिपोर्ट करने से पहले इस बात पर निर्भर करते हैं कि कोड डिस्क पर लिखा जाए। इसका मुख्य उदाहरण rust-analyzer language server है, जो लिंट्स प्राप्त करने के लिए बस प्रोजेक्ट-स्तर का cargo check चलाता है, और VS Code virtual file system के साथ एकीकृत नहीं होता (संदर्भ के लिए इस समस्या देखें)। इसलिए, शैडो कार्यस्थान अभी Rust के लिए LSP उपयोगिता का समर्थन नहीं करता, जब तक उपयोगकर्ता अप्रचलित RLS extension का उपयोग न कर रहा हो।
चलने-योग्यता प्राप्त करना
चलने-योग्यता वह बिंदु है जहाँ चीज़ें एक साथ दिलचस्प भी हो जाती हैं और जटिल भी। वर्तमान में हम Cursor के लिए कम समय-अवधि वाले AI पर ध्यान केंद्रित कर रहे हैं — जैसे, जब आप Cursor का उपयोग कर रहे हों, तब पृष्ठभूमि में आपके लिए फ़ंक्शन कार्यान्वित करना, न कि पूरे PRs कार्यान्वित करना — इसलिए हमने अभी तक चलने-योग्यता लागू नहीं की है। फिर भी, यह सोचना दिलचस्प है कि इसे कैसे प्राप्त किया जाए।
कोड चलाने के लिए उसे फ़ाइल सिस्टम में सहेजना पड़ता है। कई प्रोजेक्ट्स में डिस्क-आधारित साइड इफ़ेक्ट भी होंगे (जैसे, बिल्ड कैश और लॉग फ़ाइलें)। इसलिए, अब हम shadow window को उपयोगकर्ता के उसी फ़ोल्डर में लॉन्च नहीं कर सकते। सभी proजेक्ट्स की पूर्ण चलने-योग्यता के लिए हमें नेटवर्क-स्तर का आइसोलेशन भी चाहिए, लेकिन फ़िलहाल हम डिस्क आइसोलेशन प्राप्त करने पर ध्यान केंद्रित कर रहे हैं।
सबसे सरल विचार: cp -r
सबसे सरल तरीका यह है कि उपयोगकर्ता के फ़ोल्डर को रिकर्सिव तरीके से /tmp लोकेशन में कॉपी कर दिया जाए, फिर वहाँ AI के संपादन लागू किए जाएँ, फ़ाइलें सहेजी जाएँ, और कोड चलाया जाए। किसी दूसरे AI द्वारा किए जाने वाले अगले संपादन के लिए, हम rm -rf के बाद नया cp -r कॉल करेंगे, ताकि शैडो कार्यस्थान उपयोगकर्ता के कार्यस्थान के साथ सिंक में बना रहे।
समस्या गति की है: cp -r वास्तव में बहुत धीमा है। ध्यान रखने वाली बात यह है कि किसी प्रोजेक्ट को चलाने के लिए हमें सिर्फ़ स्रोत कोड ही कॉपी नहीं करना होता, बल्कि बिल्ड से जुड़ी सभी सहायक फ़ाइलें भी कॉपी करनी पड़ती हैं। यानी, JavaScript प्रोजेक्ट्स में node_modules, Python प्रोजेक्ट्स में venv, और Rust प्रोजेक्ट्स में target भी कॉपी करने पड़ते हैं। ये फ़ोल्डर आम तौर पर बहुत बड़े होते हैं, यहाँ तक कि मध्यम आकार के प्रोजेक्ट्स में भी, और यहीं से सीधे-सादे cp -r तरीके की सीमा सामने आ जाती है।
Symlinks, hardlinks, copy-on-writes
बड़े फ़ोल्डर स्ट्रक्चर को कॉपी करना और बनाना हमेशा बहुत धीमा नहीं होना चाहिए! इसका एक अच्छा उदाहरण bun है, जो node_modules में cached dependencies इंस्टॉल करने में अक्सर एक सेकंड से भी कम समय लेता है। Linux पर वे hardlinks का उपयोग करते हैं, जो तेज़ है क्योंकि इसमें वास्तव में डेटा इधर-उधर नहीं जाता। macOS पर वे clonefile syscall का उपयोग करते हैं, जो अपेक्षाकृत नया है और किसी फ़ाइल या फ़ोल्डर की copy-on-write करता है।
दुर्भाग्य से, हमारे मध्यम आकार के monorepo में cp -c clonefile को भी पूरा होने में 45 सेकंड लगते हैं। हर shadow workspace अनुरोध से पहले इसे चलाना बहुत धीमा है। Hardlinks जोखिम भरे हैं, क्योंकि shadow फ़ोल्डर में आप जो भी चलाएँ, वह गलती से मूल रिपॉज़िटरी की असली फ़ाइलों को संशोधित कर सकता है। Symlinks में भी यही समस्या है, और उनके साथ एक अतिरिक्त दिक्कत यह है कि उन्हें पारदर्शी रूप से नहीं संभाला जाता, यानी उनके लिए अक्सर अतिरिक्त कॉन्फ़िगरेशन की आवश्यकता होती है (उदाहरण के लिए Node.js’s --preserve-symlinks flag)।
कल्पना की जा सकती है कि clonefile (या यहाँ तक कि साधारण cp -r) काम कर सकता है, अगर उसके साथ कोई चतुर हिसाब-किताब वाली व्यवस्था जोड़ दी जाए ताकि हर अनुरोध से पहले फ़ोल्डर को दोबारा कॉपी न करना पड़े। शुद्धता सुनिश्चित करने के लिए, हमें पिछली पूरी कॉपी के बाद से उपयोगकर्ता के फ़ोल्डर में हुए सभी फ़ाइल परिवर्तनों की निगरानी करनी होगी, और कॉपी किए गए फ़ोल्डर में हुए सभी फ़ाइल परिवर्तनों की भी, और फिर हर अनुरोध से पहले दूसरे वाले परिवर्तनों को पूर्ववत करके पहले वाले परिवर्तनों को फिर से लागू करना होगा। जब भी किसी भी तरफ़ परिवर्तन का इतिहास ट्रैक रखने के लिए बहुत बड़ा हो जाए, हम एक नई पूरी कॉपी कर सकते हैं और स्थिति रीसेट कर सकते हैं। यह काम कर सकता है, लेकिन इसमें बग आने की संभावना लगती है, यह नाज़ुक भी लगता है, और सच कहें तो, ऐसी चीज़ के लिए थोड़ा भद्दा भी, जो सुनने में इतनी सरल लगती है।
जिसकी हमें वास्तव में आवश्यकता है: एक कर्नेल-स्तरीय फ़ोल्डर प्रॉक्सी
असल में हमें जो चाहिए, वह सरल है: हम चाहते हैं कि एक शैडो फ़ोल्डर A′, नियमित फ़ाइल सिस्टम API का उपयोग करने वाले सभी एप्लिकेशन को उपयोगकर्ता के फ़ोल्डर A जैसा ही दिखाई दे, और साथ ही ओवरराइड फ़ाइलों के एक छोटे सेट को जल्दी से कॉन्फ़िगर करने की क्षमता भी हो, जिनकी सामग्री डिस्क के बजाय मेमोरी से पढ़ी जाए। हम यह भी चाहते हैं कि फ़ोल्डर A′ में होने वाले किसी भी write को डिस्क पर लिखने के बजाय इन-मेमोरी ओवरराइड स्टोर में लिखा जाए। संक्षेप में, हमें कॉन्फ़िगर करने योग्य ओवरराइड्स वाला एक प्रॉक्सी फ़ोल्डर चाहिए, और ओवरराइड टेबल को पूरी तरह मेमोरी में रखना हमारे लिए स्वीकार्य है। इसके बाद हम इस प्रॉक्सी फ़ोल्डर के भीतर अपनी शैडो विंडो स्पॉन कर सकते हैं, और डिस्क-स्तर की पूर्ण स्वतंत्रता हासिल कर सकते हैं।
अहम बात यह है कि फ़ोल्डर प्रॉक्सी के लिए हमें कर्नेल-स्तरीय समर्थन चाहिए, ताकि चल रहा कोई भी कोड बिना किसी परिवर्तन के read और write syscalls को कॉल करता रहे। एक तरीका यह है कि एक कर्नेल एक्सटेंशन 13 बनाया जाए, जो कर्नेल के वर्चुअल फ़ाइल सिस्टम में शैडो फ़ोल्डर के लिए खुद को बैकएंड के रूप में पंजीकृत करे, और ऊपर बताए गए सरल व्यवहार को कार्यान्वित करे।
Linux पर हम यह काम उपयोगकर्ता स्तर पर FUSE (“Filesystem in Userspace”) के साथ भी कर सकते हैं। FUSE एक कर्नेल मॉड्यूल है, जो डिफ़ॉल्ट रूप से अधिकांश Linux वितरणों में पहले से मौजूद होता है, और फ़ाइल सिस्टम कॉल्स को प्रॉक्सी करके उपयोगकर्ता-स्तरीय प्रक्रिया तक भेजता है। इससे फ़ोल्डर प्रॉक्सी को कार्यान्वित करना और भी आसान हो जाता है। फ़ोल्डर प्रॉक्सी का एक साधारण कार्यान्वयन कुछ इस प्रकार दिख सकता है, जिसे यहाँ C++ में प्रस्तुत किया गया है।
सबसे पहले, हम उपयोगकर्ता-स्तरीय FUSE लाइब्रेरी इम्पोर्ट करते हैं, जो FUSE कर्नेल मॉड्यूल के साथ संचार करने के लिए ज़िम्मेदार होती है। हम लक्ष्य फ़ोल्डर (उपयोगकर्ता का फ़ोल्डर) और ओवरराइड्स के इन-मेमोरी मैप को भी परिभाषित करते हैं।
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// अन्य इनक्लूड...
using namespace std;
// वह प्रॉक्सीड फ़ोल्डर जिसे हम संशोधित नहीं करना चाहते
string target_folder = "/path/to/target/folder";
// लागू करने के लिए इन-मेमोरी ओवरराइड
unordered_map<string, vector<char>> overrides;फिर, हम अपना कस्टम read फ़ंक्शन परिभाषित करते हैं, ताकि वह यह जाँच सके कि overrides में वह पाथ मौजूद है या नहीं, और अगर नहीं है, तो सीधे target फ़ोल्डर से पढ़े।
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// जाँच करें कि पाथ overrides में है या नहीं
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// यदि है, तो override की सामग्री लौटाएँ
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// अन्यथा, proxied फ़ोल्डर से फ़ाइल खोलें और पढ़ें
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}हमारा कस्टम write फ़ंक्शन सिर्फ़ overrides map में लिखता है।
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// हमेशा overrides में लिखें
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}अंत में, हम अपने कस्टम फ़ंक्शनों को FUSE में पंजीकृत करते हैं।
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}एक वास्तविक कार्यान्वयन के लिए पूरे FUSE API को लागू करना होगा, जिसमें readdir, getattr, और lock शामिल हैं, लेकिन ये फ़ंक्शन ऊपर दिए गए फ़ंक्शनों जैसे ही होंगे। लिंट्स के लिए हर नए अनुरोध पर, हम overrides map को केवल उसी विशिष्ट AI के संपादनों तक रीसेट कर सकते हैं, जो तुरंत हो जाता है। अगर हम मेमोरी के अत्यधिक बढ़ने से पूरी तरह बचाव सुनिश्चित करना चाहें, तो overrides map को डिस्क पर भी रख सकते हैं (इसके लिए कुछ अतिरिक्त bookkeeping का काम करना होगा)।
परिवेश पर पूरा नियंत्रण होने पर, हम संभवतः इसे FUSE से होने वाले अतिरिक्त user-kernel संदर्भ बदलने के ओवरहेड से बचने के लिए native कर्नेल module के रूप में लागू करना चाहेंगे। 14
...लेकिन: बंद इकोसिस्टम
Linux के लिए FUSE फ़ोल्डर प्रॉक्सी बेहतरीन काम करता है, लेकिन हमारे ज़्यादातर उपयोगकर्ता macOS या Windows का उपयोग करते हैं, और इनमें से किसी में भी बिल्ट-इन FUSE implementation नहीं है। दुर्भाग्य से, कर्नेल एक्सटेंशन शिप करना भी संभव नहीं है: Apple Silicon वाले Macs पर कोई उपयोगकर्ता कर्नेल एक्सटेंशन तभी इंस्टॉल कर सकता है, जब वह recovery mode में जाने के लिए एक विशेष कुंजी दबाए रखते हुए कंप्यूटर को reboot करे, और फिर “Reduced Security” पर downgrade करे। इसे शिप करना नामुमकिन है!
क्योंकि FUSE को आंशिक रूप से कर्नेल के भीतर चलना पड़ता है, इसलिए macFUSE जैसे तृतीय-पक्ष FUSE implementations को भी वही समस्या झेलनी पड़ती है: उपयोगकर्ताओं से इसे इंस्टॉल करवाना लगभग असंभव है।
इस पाबंदी के आसपास रचनात्मक तरीके आज़माने की कोशिशें हुई हैं। एक तरीका यह है कि ऐसे network-based file system का उपयोग किया जाए, जिसे macOS मूल रूप से समर्थन करता है (जैसे NFS या SMB), और उसके नीचे एक FUSE API लगा दिया जाए। NFS के ऊपर बना FUSE-जैसे API वाला एक ओपन सोर्स proof-of-concept local server xetdata/nfsserve पर होस्ट किया गया है, और closed-source प्रोजेक्ट macOS-FUSE-t, NFS और SMB दोनों पर बने backends का समर्थन करता है।
समस्या हल हो गई? पूरी तरह नहीं... फ़ाइल सिस्टम सिर्फ़ फ़ाइलें पढ़ने, लिखने और सूचीबद्ध करने भर से कहीं ज़्यादा जटिल होते हैं! यहाँ Cargo शिकायत करता है, क्योंकि NFS के पुराने संस्करण, जिन पर xetdata/nfsserve implementation बनाया गया है, file locking का समर्थन नहीं करते।

MacOS-FUSE-t, NFSv4 पर बनाया गया है, जो वास्तव में file locking का समर्थन करता है, लेकिन GitHub रेपो में सिर्फ़ तीन non-source फ़ाइलें (Attributions.txt, License.txt, README.md) हैं, और इसे macos-fuse-t जैसे संदिग्ध रूप से एकल-उद्देश्यीय username वाले GitHub खाते ने बनाया है, जिसके बारे में और कोई जानकारी नहीं है। साफ़ है, हम अपने उपयोगकर्ताओं को यूँ ही कोई random binary शिप नहीं कर सकते... open समस्याएँ यह भी दिखाती हैं कि NFS/SMB-आधारित तरीके में कुछ और बुनियादी समस्याएँ हैं, जिनमें ज़्यादातर Apple के kernel bugs शामिल हैं।
अब हमारे पास क्या बचता है? या तो कोई नया रचनात्मक तरीका, 15 या... राजनीति! कर्नेल एक्सटेंशन को धीरे-धीरे समाप्त करने की Apple की दशक-लंबी यात्रा ने उन्हें और ज़्यादा user-level APIs (जैसे DriverKit) खोलने की दिशा में आगे बढ़ाया है, और पुराने file systems के लिए उनका built-in समर्थन हाल ही में user-land में स्थानांतरित किया गया है। उनके open source MS-DOS कोड में FSKit नाम के एक private framework का संदर्भ यहाँ मिलता है, जो काफ़ी आशाजनक लगता है! ऐसा लगता है कि थोड़ी-सी राजनीतिक कोशिश से हम Apple को FSKit को अंतिम रूप देकर external डेवलपर्स के लिए जारी करने के लिए मना सकते हैं (या शायद वे पहले से ही इसकी योजना बना रहे हों?), और अगर ऐसा हुआ, तो macOS के लिए चलने-योग्यता की समस्या का भी शायद हमारे पास समाधान हो सकता है।
खुले प्रश्न
जैसा कि हमने देखा है, AI को पृष्ठभूमि में कोड पर बार-बार काम करने देने की जो समस्या ऊपर से सरल लगती है, वह वास्तव में काफ़ी जटिल है। शैडो कार्यस्थान 1 हफ़्ते और 1 व्यक्ति का प्रोजेक्ट था, जिसका मकसद हमारी उस तत्काल ज़रूरत को पूरा करने के लिए एक कार्यान्वयन तैयार करना था, जिसमें हमें AI को lints दिखाने थे। आगे चलकर, हम इसे बढ़ाकर चलने-योग्यता की समस्या को भी हल करने लायक बनाना चाहते हैं। कुछ खुले प्रश्न:
-
क्या उस साधारण प्रॉक्सी फ़ोल्डर को, जिसके बारे में हम सोच रहे हैं, कर्नेल एक्सटेंशन बनाए बिना या FUSE API का इस्तेमाल किए बिना लागू करने का कोई दूसरा तरीका है? FUSE एक बड़ी समस्या (किसी भी तरह की फ़ाइल सिस्टम) को हल करने की कोशिश करता है, इसलिए यह संभव लगता है कि macOS और Windows पर कुछ कम-ज्ञात APIs हों जो हमारे फ़ोल्डर प्रॉक्सी के लिए काम करें, लेकिन सामान्य FUSE कार्यान्वयन के लिए न करें।
-
Windows पर प्रॉक्सी फ़ोल्डर का समाधान वास्तव में कैसा दिखेगा? क्या WinFsp जैसी कोई चीज़ सीधे काम कर जाएगी, या उसके साथ इंस्टॉलेशन, प्रदर्शन या सुरक्षा संबंधी समस्याएँ होंगी? मैंने अपना ज़्यादातर समय macOS पर फ़ोल्डर प्रॉक्सी कैसे किया जाए, यह समझने में बिताया।
-
शायद macOS पर DriverKit का उपयोग करके एक नकली USB डिवाइस का अनुकरण करने का कोई तरीका हो, जो प्रॉक्सी फ़ोल्डर की तरह काम करे? मुझे इस पर संदेह है, लेकिन मैंने API को इतना क़रीब से नहीं देखा है कि आत्मविश्वास के साथ कह सकूँ कि यह असंभव है।
-
हम नेटवर्क-स्तर की स्वतंत्रता कैसे हासिल कर सकते हैं? विचार करने लायक एक खास स्थिति वह है जब AI किसी integration test को डीबग करना चाहता है, जहाँ कोड तीन microservices में बँटा हुआ है। 16 हो सकता है कि हम कुछ अधिक VM-जैसा करना चाहें, हालाँकि उसके लिए पूरे परिवेश सेटअप और सभी इंस्टॉल किए गए सॉफ़्टवेयर की समतुल्यता सुनिश्चित करने में अधिक काम लगेगा।
-
क्या उपयोगकर्ता के स्थानीय कार्यस्थान से एक बिल्कुल समान remote कार्यस्थान बनाया जा सकता है, जिसमें उपयोगकर्ता से यथासंभव कम सेटअप की आवश्यकता हो? क्लाउड में, हम बिना किसी झंझट के FUSE को सीधे इस्तेमाल कर सकते हैं (या प्रदर्शन कारणों से चाहें तो कर्नेल मॉड्यूल भी), और हम यह भी सुनिश्चित कर सकते हैं कि उपयोगकर्ता के लिए कोई अतिरिक्त मेमोरी उपयोग न हो और पूरी स्वतंत्रता मिले। जिन उपयोगकर्ताओं को गोपनीयता की कम चिंता है, उनके लिए यह एक अच्छा विकल्प हो सकता है। एक शुरुआती विचार यह है कि सिस्टम का अवलोकन करके किसी तरह का auto-inferred docker container बनाया जाए (शायद मशीन पर क्या चल रहा है, इसका पता लगाने के लिए स्क्रिप्ट्स लिखने और Dockerfile लिखने के लिए language models का उपयोग करने के संयोजन से)।
यदि इन प्रश्नों में से किसी के बारे में आपके पास अच्छे विचार हैं, तो कृपया मुझे arvid@cursor.com पर ईमेल करें। साथ ही, अगर आप इस तरह की चीज़ों पर काम करना चाहते हैं, तो हम भर्ती कर रहे हैं।