गतिशील संदर्भ खोज
कोडिंग एजेंट्स तेज़ी से यह बदल रहे हैं कि सॉफ़्टवेयर कैसे बनाया जाता है। उनमें तेज़ी से हो रहा सुधार बेहतर एजेंटिक मॉडल्स और उन्हें दिशा देने के लिए बेहतर संदर्भ इंजीनियरिंग, दोनों का परिणाम है।
Cursor का एजेंट हार्नेस—यानी वे निर्देश और उपकरण जो हम मॉडल को देते हैं—हम जिन भी नए अत्याधुनिक मॉडल्स का समर्थन करते hain, उनमें से हर एक के लिए अलग-अलग अनुकूलित किया जाता है। हालाँकि, संदर्भ इंजीनियरिंग में ऐसे सुधार भी हैं जो हम कर सकते हैं—जैसे हम संदर्भ कैसे इकट्ठा करते हैं और लंबे ट्रैजेक्टरी में token के उपयोग को कैसे अनुकूलित करते हैं—जो हमारे हार्नेस के भीतर सभी मॉडल्स पर लागू होते हैं।
जैसे-जैसे मॉडल एजेंट की तरह बेहतर काम करने लगे हैं, हमने शुरुआत में कम विवरण देकर बेहतर परिणाम पाए हैं, जिससे एजेंट के लिए खुद प्रासंगिक संदर्भ जुटाना आसान हो जाता है। हम इस पैटर्न को गतिशील संदर्भ खोज कह रहे हैं, स्थिर संदर्भ के विपरीत, जो हमेशा शामिल रहता है।
गतिशील संदर्भ खोज के लिए फ़ाइलें
गतिशील संदर्भ खोज token के लिहाज़ से कहीं अधिक दक्ष है, क्योंकि केवल ज़रूरी डेटा ही कॉन्टेक्स्ट विंडो में लाया जाता है। यह कॉन्टेक्स्ट विंडो में संभावित रूप से भ्रमित करने वाली या परस्पर विरोधी जानकारी की मात्रा कम करके एजेंट की प्रतिक्रिया की गुणवत्ता भी बेहतर कर सकता है।
यहाँ बताया गया है कि हमने Cursor में गतिशील संदर्भ खोज का उपयोग कैसे किया है:
- लंबे टूल प्रतिक्रियाओं को फ़ाइलों में बदलना
- सारांशण के दौरान चैट इतिहास का संदर्भ देना
- Agent Skills खुले मानक का समर्थन
- केवल आवश्यक MCP टूल्स को कुशलतापूर्वक लोड करना
- सभी एकीकृत टर्मिनल सेशनों को फ़ाइलों के रूप में मानना
1. लंबे टूल प्रतिक्रियाओं को फ़ाइलों में बदलना
टूल कॉल्स बड़े JSON रिस्पॉन्स लौटाकर कॉन्टेक्स्ट विंडो को काफ़ी बढ़ा सकते हैं।
Cursor में फ़र्स्ट-पार्टी टूल्स, जैसे फ़ाइलों को संपादित करना और कोडबेस में खोज करना, के लिए हम समझदार टूल परिभाषाओं और न्यूनतम रिस्पॉन्स फ़ॉर्मैट्स के ज़रिए संदर्भ के अनावश्यक बढ़ाव को रोक सकते हैं। लेकिन तृतीय-पक्ष टूल्स (यानी शेल कमांड या MCP कॉल्स) को यह सुविधा मूल रूप से नहीं मिलती।
कोडिंग एजेंट्स आम तौर पर लंबे शेल कमांड्स या MCP परिणामों को ट्रंकेट कर देते हैं। इससे डेटा खो सकता है, जिसमें वह अहम जानकारी भी शामिल हो सकती है जिसे आप संदर्भ में रखना चाहते थे। Cursor में, इसके बजाय हम आउटपुट को एक फ़ाइल में लिख देते हैं और एजेंट को उसे पढ़ने की क्षमता देते हैं। एजेंट आखिर का हिस्सा जाँचने के लिए tail कॉल करता है, और ज़रूरत पड़ने पर फिर और पढ़ता है।
इससे संदर्भ सीमाओं तक पहुँचने पर अनावश्यक सारांशण कम हुआ है।
2. सारांशण के दौरान चैट इतिहास का संदर्भ लेना
जब मॉडल की कॉन्टेक्स्ट विंडो भर जाती है, तो Cursor एजेंट को उसके अब तक के काम के सारांश के साथ एक नई कॉन्टेक्स्ट विंडो देने के लिए सारांशण चरण ट्रिगर करता है।
लेकिन सारांशण के बाद एजेंट की जानकारी कम हो सकती है, क्योंकि यह संदर्भ का हानिपूर्ण संपीड़न होता है। एजेंट अपने कार्य से जुड़े अहम विवरण भूल सकता है। Cursor में, हम सारांशण की गुणवत्ता बेहतर करने के लिए चैट इतिहास को फ़ाइलों के रूप में उपयोग करते हैं।


कॉन्टेक्स्ट विंडो की सीमा तक पहुंचने के बाद, या जब उपयोगकर्ता मैन्युअल रूप से सारांशण करने का फैसला करता है, तो हम एजेंट को इतिहास फ़ाइल का संदर्भ देते हैं। अगर एजेंट को पता हो कि उसे ऐसे अधिक विवरण चाहिए जो सारांश में नहीं हैं, तो वह उन्हें वापस पाने के लिए इतिहास में खोज कर सकता है।
3. Agent Skills खुले मानक का समर्थन
Cursor Agent Skills का समर्थन करता है, जो विशेषीकृत क्षमताओं के साथ कोडिंग एजेंट्स का विस्तार करने के लिए एक खुला मानक है। नियम के अन्य प्रकारों की तरह, कौशल उन फ़ाइलों से परिभाषित होते हैं जो एजेंट को बताती हैं कि किसी डोमेन-विशिष्ट कार्य को कैसे पूरा करना है।
कौशलों में एक नाम और विवरण भी शामिल होता है, जिसे सिस्टम प्रॉम्प्ट में "स्थिर संदर्भ" के रूप में शामिल किया जा सकता है। इसके बाद एजेंट grep और Cursor की सिमैंटिक खोज जैसे टूल्स का इस्तेमाल करके, प्रासंगिक कौशलों को शामिल करने के लिए गतिशील संदर्भ खोज कर सकता है।
कौशल कार्य से संबंधित एक्ज़िक्यूटेबल फ़ाइलें या स्क्रिप्ट्स भी बंडल कर सकते हैं। चूँकि ये सिर्फ़ फ़ाइलें हैं, एजेंट आसानी से पता लगा सकता है कि किसी विशेष कौशल के लिए क्या प्रासंगिक है।
4. केवल ज़रूरी MCP टूल्स को कुशलतापूर्वक लोड करना
OAuth के पीछे सुरक्षित संसाधनों तक पहुँचने के लिए MCP काफ़ी उपयोगी है। इनमें उत्पादन लॉग्स, बाहरी डिज़ाइन फ़ाइलें, या किसी Enterprise के लिए आंतरिक संदर्भ और दस्तावेज़ीकरण शामिल हो सकते हैं।
कुछ MCP सर्वर में बहुत से टूल्स होते हैं, और अक्सर उनके विवरण भी लंबे होते हैं, जिससे कॉन्टेक्स्ट विंडो काफ़ी बड़ी हो सकती है। इनमें से ज़्यादातर टूल्स इस्तेमाल ही नहीं होते, फिर भी वे हमेशा प्रॉम्प्ट में शामिल रहते हैं। अगर आप कई MCP सर्वर उपयोग करें, तो यह समस्या और बढ़ जाती है।
यह उम्मीद करना व्यावहारिक नहीं है कि हर MCP सर्वर इसके लिए अनुकूलित हो। हमारा मानना है कि संदर्भ उपयोग घटाने की ज़िम्मेदारी कोडिंग एजेंट्स की है। Cursor में, हम MCP के लिए गतिशील संदर्भ खोज का समर्थन करते हैं, जिसमें टूल विवरणों को एक फ़ोल्डर में सिंक किया जाता है।1
अब एजेंट को केवल थोड़ा-सा स्थिर संदर्भ मिलता है, जिसमें टूल्स के नाम शामिल होते हैं, ताकि जब कार्य की ज़रूरत पड़े तो वह टूल्स को खोज सके। एक A/B परीक्षण में, हमने पाया कि जिन रन में किसी MCP टूल को कॉल किया गया, उनमें इस रणनीति ने कुल एजेंट टोकन 46.9% तक घटा दिए (सांख्यिकीय रूप से महत्वपूर्ण, और इंस्टॉल किए गए MCPs की संख्या के आधार पर इसमें काफ़ी अधिक विचरण था)।
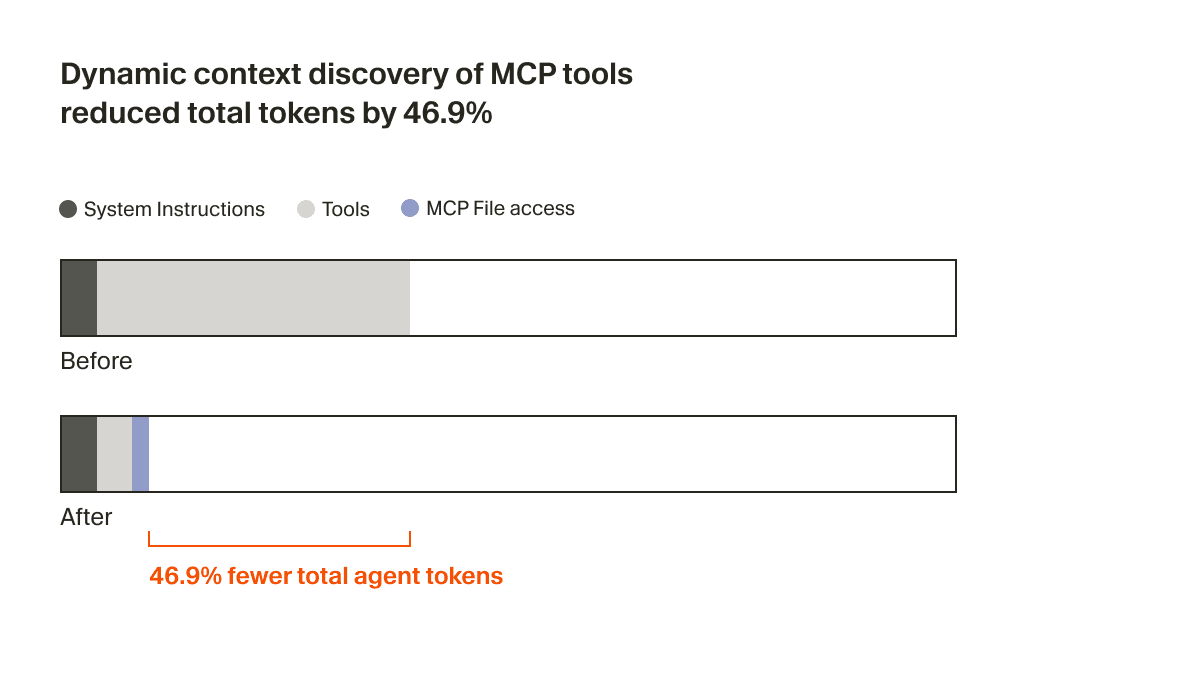
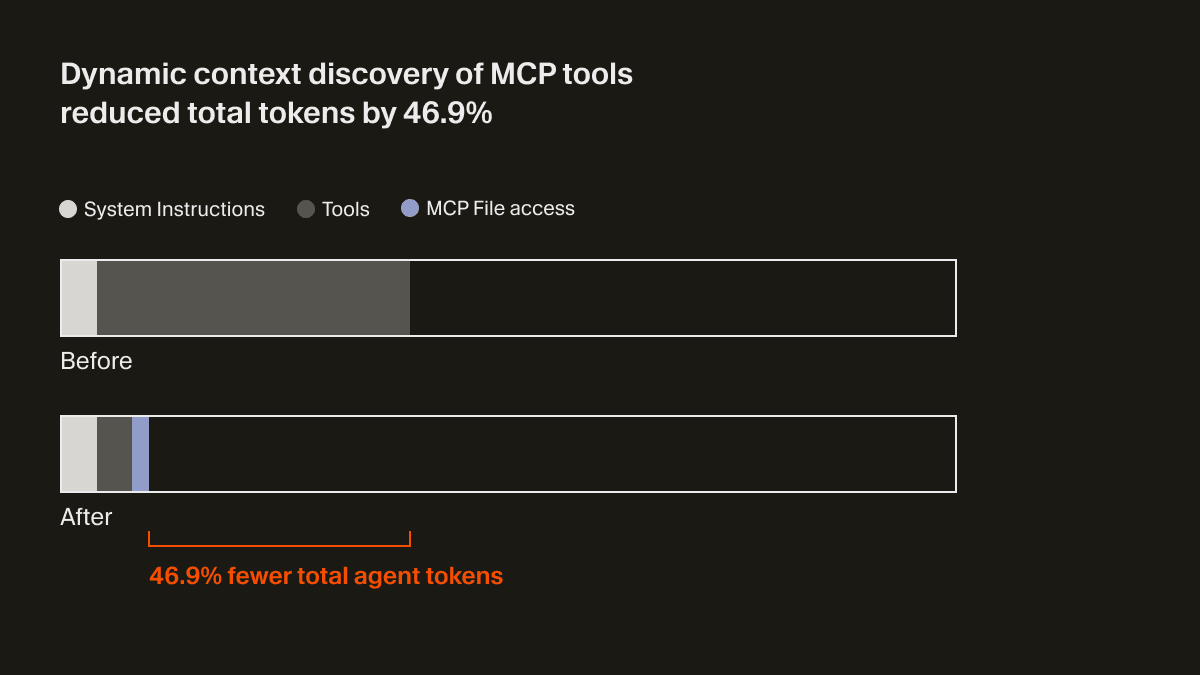
यह फ़ाइल-आधारित तरीका एजेंट तक MCP टूल्स की स्थिति पहुँचाने की क्षमता भी खोलता है। उदाहरण के लिए, पहले अगर किसी MCP सर्वर को दोबारा प्रमाणीकरण की ज़रूरत होती थी, तो एजेंट उन टूल्स के बारे में पूरी तरह भूल जाता था, जिससे उपयोगकर्ता भ्रमित हो जाता था। अब यह उपयोगकर्ता को पहले से ही दोबारा प्रमाणित करने के लिए सक्रिय रूप से बता सकता है।
5. सभी एकीकृत टर्मिनल सेशनों को फ़ाइलों के रूप में मानना
टर्मिनल सत्र के आउटपुट को एजेंट इनपुट में कॉपी/पेस्ट करने की आवश्यकता के बजाय, Cursor अब एकीकृत टर्मिनल के आउटपुट को स्थानीय फ़ाइलसिस्टम के साथ सिंक करता है।
इससे "मेरा कमांड क्यों विफल हुआ?" पूछना आसान हो जाता है और एजेंट के लिए यह समझना भी आसान हो जाता है कि आप किसका संदर्भ दे रहे हैं। चूँकि टर्मिनल हिस्ट्री लंबी हो सकती है, एजेंट सिर्फ़ प्रासंगिक आउटपुट के लिए grep कर सकता है, जो सर्वर जैसी लंबे समय तक चलने वाली प्रक्रिया के लॉग्स के लिए उपयोगी है।
यह वैसा ही है जैसा CLI-आधारित कोडिंग एजेंट्स देखते हैं—यानी संदर्भ में पहले का शेल आउटपुट मौजूद होता है—लेकिन उसे स्थिर रूप से इंजेक्ट करने के बजाय, गतिशील रूप से खोजा जाता है।
सरल एब्स्ट्रैक्शन्स
यह स्पष्ट नहीं है कि LLM-आधारित टूल्स के लिए फ़ाइलें ही अंतिम इंटरफ़ेस होंगी या नहीं।
लेकिन जैसे-जैसे कोडिंग एजेंट्स तेज़ी से बेहतर हो रहे हैं, फ़ाइलें इस्तेमाल करने के लिए एक सरल और शक्तिशाली आधार साबित हुई हैं, और ऐसे किसी नए एब्स्ट्रैक्शन की तुलना में ज़्यादा सुरक्षित विकल्प भी हैं जो भविष्य को पूरी तरह समेट नहीं सकता। इस क्षेत्र में साझा करने के लिए हमारे पास और भी बहुत-सा रोमांचक काम है—बने रहें।
ये सुधार आने वाले हफ्तों में सभी उपयोगकर्ताओं के लिए लाइव हो जाएँगे। इस ब्लॉग पोस्ट में बताई गई तकनीकें Cursor के कई कर्मचारियों के काम का नतीजा हैं, जिनमें Lukas Moller, Yash Gaitonde, Wilson Lin, Jason Ma, Devang Jhabakh और Jediah Katz शामिल हैं। अगर आप AI का इस्तेमाल करके सबसे कठिन और महत्वाकांक्षी कोडिंग कार्यों को हल करने में रुचि रखते हैं, तो हम आपसे सुनना पसंद करेंगे। हमसे hiring@cursor.com पर संपर्क करें।
- हमने टूल खोज के तरीके पर विचार किया था, लेकिन उससे टूल्स एक सपाट इंडेक्स में बिखर जाते। इसके बजाय, हम हर सर्वर के लिए एक फ़ोल्डर बनाते हैं, जिससे उस सर्वर के टूल्स तार्किक रूप से एक साथ समूहित रहते हैं। जब मॉडल किसी फ़ोल्डर की सूची देखता है, तो उसे उस सर्वर के सभी टूल्स एक साथ दिखते हैं और वह उन्हें एक सुसंगत इकाई के रूप में समझ सकता है। फ़ाइलें अधिक शक्तिशाली खोज भी सक्षम करती हैं। एजेंट पूरे
rgपैरामीटर का उपयोग कर सकता है या टूल विवरणों को फ़िल्टर करने के लिएjqका भी उपयोग कर सकता है। ↩