Mayor uso para agentes
Hemos aumentado los límites de Auto y Composer 1.5 para todos los planes individuales.
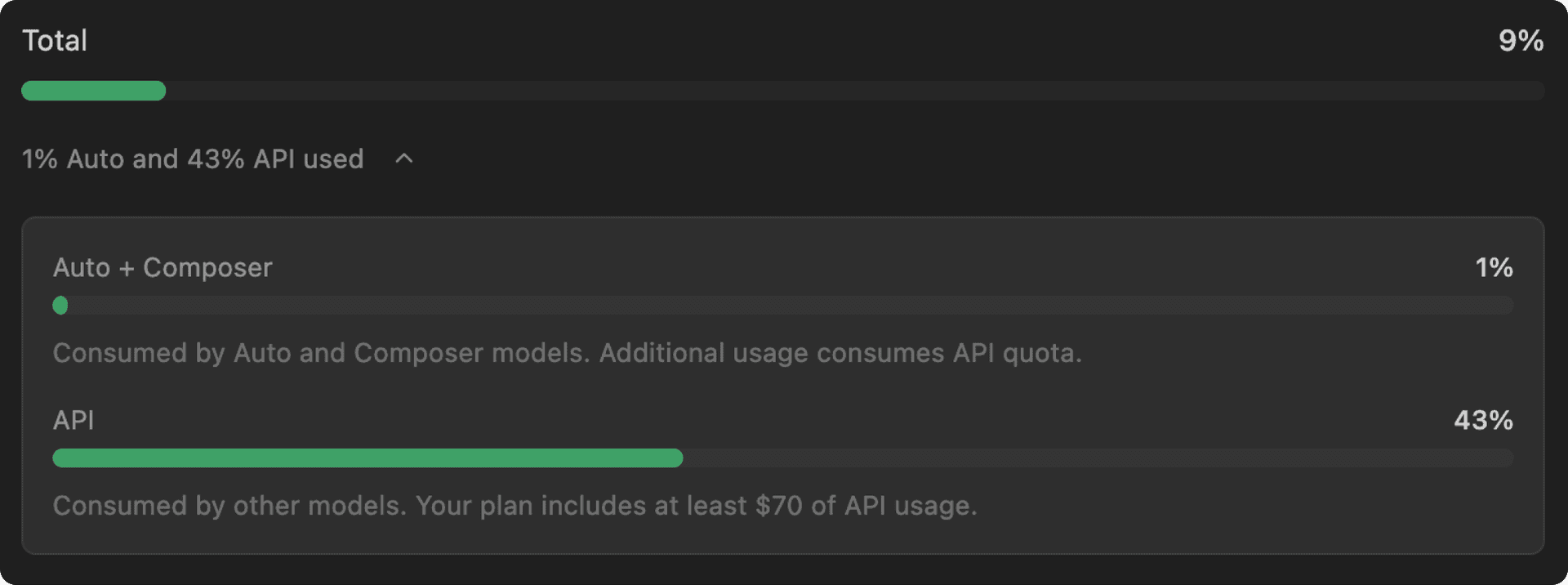
Ahora hay dos grupos de uso:
- Grupo de modelos propios: En el lanzamiento, incluimos un uso significativamente mayor para Auto y Composer 1.5.
- API: Cobramos el precio API del modelo (que no cambia con esta actualización).
Composer 1.5 ahora tiene 3 veces el límite de uso de Composer 1. Para un tiempo limitado (hasta el 16 de febrero), aumentamos ese límite a 6 veces más.
De autocompletado a agentes
En los últimos meses, hemos visto un cambio importante hacia programar con agentes.
Los desarrolladores le están pidiendo a Cursor que realice cambios ambiciosos en toda su base de código. Queremos que Cursor admita la programación basada en agentes en el día a día, y reconocemos que los desarrolladores tienen prioridades diferentes.
Algunos se sienten cómodos pagando siempre por los modelos más nuevos, mientras que otros buscan el equilibrio adecuado entre velocidad, inteligencia y coste. Al introducir dos grupos de uso y aumentar los límites de los modelos propios, estamos respaldando ambos enfoques.
Un nuevo modelo para programación basada en agentes
Entrenar nuestros propios modelos como Composer-1.5 nos permite admitir un volumen de uso significativamente mayor de forma sostenible.
Hemos observado que Composer 1.5 es un modelo muy capaz: obtiene una puntuación superior a Sonnet 4.5 en Terminal-Bench 2.0, aunque por debajo de los mejores modelos de vanguardia.1


Esperamos seguir encontrando formas de ofrecer modelos cada vez más inteligentes y rentables, junto con los modelos de vanguardia más recientes.
Visibilidad de uso mejorada
Para seguir mejorando la visibilidad del uso, hemos añadido una nueva página en el editor donde puedes controlar tus límites con dos grupos de uso diferentes:
- Grupo de modelos propios: En el lanzamiento, incluimos un uso significativamente mayor al seleccionar Auto o
composer-1.5. - API: Los planes individuales incluyen al menos 20 USD de uso cada mes (más en niveles superiores), con la opción de pagar por uso adicional según sea necesario. Estos límites de uso no han cambiado con esta actualización.

Prueba nuestro modelo más reciente
Te recomendamos probar Composer 1.5 con nuestros límites de uso actualizados.
Ambos cupos de uso se restablecen con tu ciclo de uso mensual. Estos límites ya están activos para todos los planes individuales (Pro, Pro Plus y Ultra).
- Terminal-Bench 2.0 es un benchmark de evaluación de agentes para uso en terminal, mantenido por Laude Institute. Las puntuaciones de los modelos de Anthropic usan el harness Claude Code y las puntuaciones de los modelos de OpenAI usan el harness Simple Codex. Nuestra puntuación de Cursor se calculó usando el framework de evaluación Harbor oficial (el harness designado para Terminal-Bench 2.0) con la configuración predeterminada del benchmark. Ejecutamos 2 iteraciones por par modelo-agente y reportamos el promedio. Puedes encontrar más detalles sobre el benchmark en el sitio web oficial de Terminal Bench. Para otros modelos además de Composer 1.5, tomamos la puntuación máxima entre la puntuación de la tabla de clasificación oficial y la puntuación registrada al ejecutarlo en nuestra infraestructura. ↩