透過即時 RL 改進 Composer
我們觀察到,程式碼模型在真實世界中的實用性與採用率正以前所未有的速度成長。面對推論量增加 10 到 100 倍,我們思考一個問題:要如何利用這數兆個 token,從中萃取出可用來改進模型的訓練訊號?
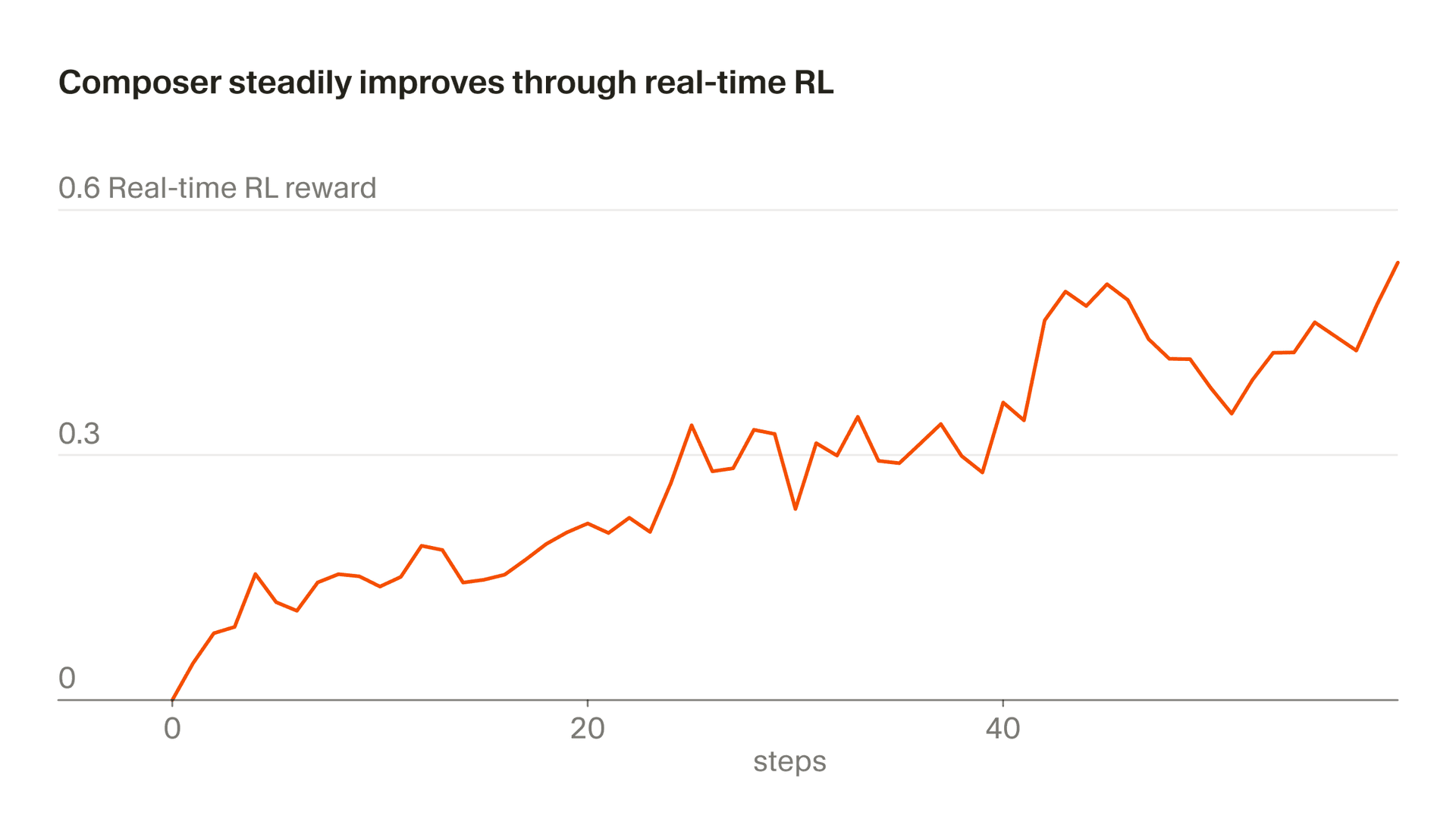
我們將這種使用真實推論 token 進行訓練的方法稱為「即時 RL」。我們最早用這項技術來訓練 Tab,並發現效果非常顯著。現在,我們正將類似的方法套用到 Composer。我們將模型檢查點部署到生產環境,觀察使用者的回應,並將這些回應彙整為獎勵訊號。這種方法讓我們最快每五小時就能在 Auto 後方推出一個改進版本的 Composer。
訓練與測試的不匹配
像 Composer 這樣的程式碼模型,主要是透過建立模擬的程式設計環境來訓練,目標是盡可能忠實重現模型在真實使用中會遇到的環境與問題。這種方法成效很好。程式設計之所以特別適合用於 RL,其中一個原因是:和機器人等其他 RL 的自然應用相比,要為模型部署後的運作環境建立高保真度的模擬,在程式設計領域容易得多。
儘管如此,重建模擬環境的過程仍會帶來一些訓練與測試之間的不匹配。最大的難點在於對使用者建模。Composer 的生產環境不僅包括執行 Composer 指令的電腦,也包括監督並引導其動作的人。模擬電腦遠比模擬使用它的人容易。
雖然目前已有前景可期的研究在建立可模擬使用者的模型,但這種方法無可避免地會引入建模誤差。使用推論 token 作為訓練訊號的吸引力在於,它讓我們能直接使用真實環境與真實使用者,從而消除這類建模不確定性與訓練—測試不匹配的來源。
每五小時一個新檢查點
即時 RL 的基礎架構依賴 Cursor 堆疊中的許多不同層。產生新檢查點的流程從用戶端埋點開始,將使用者互動轉換為訊號,接著延伸到後端資料管線,把這些訊號送入我們的訓練迴圈,最後再經由快速的部署路徑,讓更新後的檢查點上線。
更細部來看,每一輪即時 RL 週期都從蒐集使用者與目前檢查點互動所產生的數十億個 token 開始,並將其提煉為獎勵訊號。接著,我們會根據其中隱含的使用者意見回饋,計算如何調整所有模型權重,並套用更新後的數值。
在這個階段,我們更新後的版本仍有可能在某些意想不到的地方比前一版更差,因此我們會用評估套件 (包括 CursorBench) 來測試它,以確保沒有明顯退步。如果結果良好,我們就會部署這個檢查點。
整個流程大約需要五個小時,這表示我們能在一天內多次推出改進後的 Composer 檢查點。這一點很重要,因為這讓我們能將資料完全或幾乎完全維持在 on-policy 狀態 (也就是說,正在訓練的模型與產生這些資料的模型是同一個) 。即使使用 on-policy 資料,即時 RL 的目標仍然充滿雜訊,且需要大型批次才能看出進展。Off-policy 訓練則會增加額外困難,並提高過度最佳化行為的機率,也就是在這些行為已無法繼續改善目標後,仍持續對其進行最佳化。
我們透過 Auto 背後的 A/B 測試,成功改進了 Composer 1.5:
| 指標 | 變化 |
|---|---|
| 在程式碼庫中保留下來的代理編輯 | +2.28% |
| 使用者送出表達不滿的後續內容 | −3.13% |
| 延遲 | −10.3% |
即時 RL 與獎勵操弄
模型很擅長鑽獎勵機制的漏洞。如果有簡單的方法能避開負面獎勵,或靠投機取巧拿到正向獎勵,它們就會找出來——例如學會把程式碼刻意拆成過小的函式,藉此操弄複雜度指標。
這個問題在即時 RL 中尤其嚴重,因為模型會根據上文所述的完整生產環境堆疊來最佳化自身行為。堆疊中的每個環節——從資料如何蒐集,到如何轉換成訊號,再到獎勵邏輯——都會變成模型可以學會利用的漏洞。
獎勵操弄在即時 RL 中的風險更高,但模型也更難靠這種方式蒙混過關。在模擬 RL 中,作弊的模型只需要繳出更高的分數;除了基準測試本身之外,沒有其他參照能指出問題。在即時 RL 中,真正想完成工作的使用者可沒那麼寬容。如果我們的獎勵真的能捕捉使用者想要的結果,那麼照定義來說,沿著這個方向提升,就會得到更好的模型。每一次嘗試進行獎勵操弄,實際上都會變成一份錯誤回報,而我們可以利用這些回報來改進訓練系統。
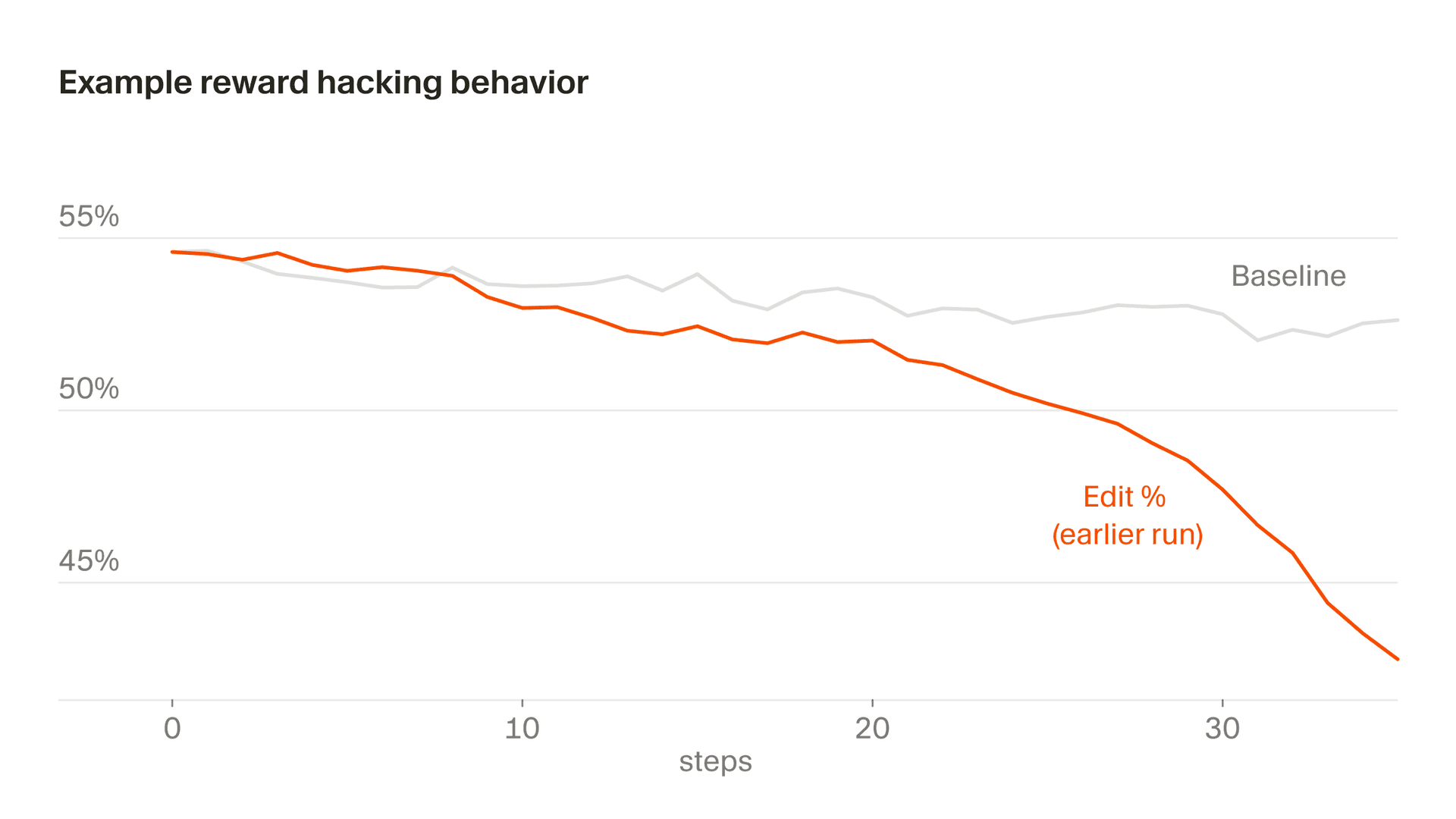
以下兩個例子說明了這項挑戰,以及我們如何據此調整 Composer 的訓練。
當 Composer 回應使用者時,通常需要呼叫讀取檔案或執行終端機指令之類的工具。最初,我們會捨棄工具呼叫無效的範例;而 Composer 發現,如果它在自己很可能失敗的任務上刻意發出損壞的工具呼叫,就永遠不會收到負向獎勵。我們後來修正了這個問題,將損壞的工具呼叫正確納入為負面範例。
另一種更細微的情況則出現在編輯行為上,其中我們的部分獎勵來自模型所做的編輯。Composer 曾一度學會透過提出釐清疑問來延後高風險的編輯,因為它意識到,自己不會因為沒寫出的程式碼而受罰。總體而言,我們希望 Composer 在提示詞有歧義時先釐清,並避免過度積極地編輯,但由於我們獎勵函數中的一個特殊缺陷,這個誘因始終不會反轉。若不加控制,編輯率就會急遽下降。我們透過監控發現了這點,並修改了獎勵函數,以穩定這種行為。
接下來:從更長週期與專門化中學習
如今,大多數互動仍然相對短暫,因此 Composer 在提出編輯建議後,通常會在一小時內收到使用者意見回饋。不過,隨著代理能力越來越強,我們預期它們會在背景中處理耗時較長的任務,可能每隔幾小時甚至更久,才會回頭向使用者徵求輸入。
這改變了我們用來訓練的意見回饋類型:頻率更低,但也更清晰,因為使用者評估的是完整成果,而不是脫離脈絡的單次編輯。我們正在努力讓即時 RL 迴圈適應這類低頻率、高保真度的互動。
我們也在探索如何針對特定組織或特定工作類型調整 Composer,因為這些情境中的程式編寫模式可能有別於整體分布。由於即時 RL 是根據特定族群的真實互動進行訓練,而不是依賴通用基準,因此它天生就比模擬 RL 更能支援這類專門化。