Composer 2 的技術報告

我們已在 arXiv 發表一份關於 Composer 2 訓練的技術報告。Composer 2 是我們用於代理式軟體工程的程式碼模型。這份報告涵蓋完整的訓練流程,從基於開放的基礎模型 Kimi K2.5 進行持續預訓練,到大規模強化學習,重點在於盡可能貼近真實的 Cursor 環境。
持續預訓練與 RL
Composer 2 的訓練分為兩個階段:先在偏重程式碼的混合資料上進行持續預訓練,以深化基礎模型的程式設計知識,接著再透過大規模強化學習,提升端對端代理效能。我們發現,降低預訓練損失有助於改善下游 RL 效能,而更紮實的基礎知識也能穩定轉化為更好的代理表現。
Composer 2 的 RL 訓練是在真實的 Cursor 工作階段中進行,使用與已部署模型相同的工具與執行框架,並套用於能反映開發者要求 Composer 執行之各類任務完整範圍的問題分布。我們發現,RL 訓練同時提升了平均效能與 best-of-K 效能,這表示模型正在學習新的解題路徑,而不只是更集中在既有路徑上。
使用 CursorBench 進行真實世界評估
打造程式碼模型的一項核心挑戰在於,公開基準測試往往無法反映開發者實際在做的工作。任務的規格往往過於明確,解法空間狹窄,而且程式碼庫規模也很小。
我們根據工程團隊的真實程式設計工作階段打造了 CursorBench。其中包含一些任務,其提示詞簡短且帶有歧義,而解法則需要在多個檔案中進行數百行的變更。我們在整個訓練與評估過程中使用 CursorBench,讓模型持續貼近真實問題。
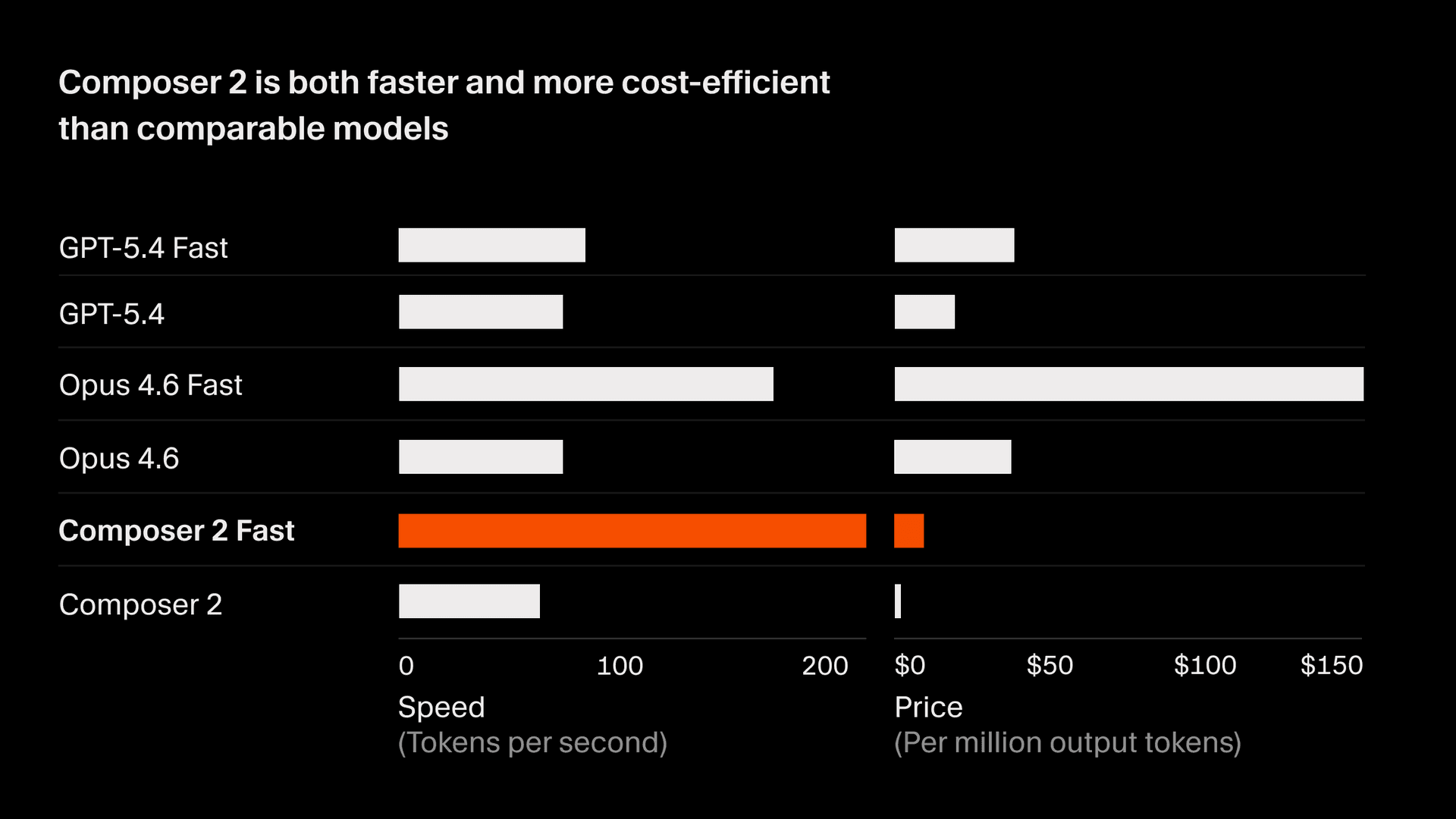
效能
在 CursorBench 上,Composer 2 得分 61.3,較 Composer 1.5 提升 37%,並可與最強的尖端模型競爭。在公開基準測試中,Composer 2 在 SWE-bench Multilingual 上獲得 73.7 分,在 Terminal-Bench 上獲得 61.7 分。它以顯著低於同級模型的推論成本達成這樣的表現,在互動式開發工作流程中,於準確性與成本之間實現帕累托最優的平衡。



基礎架構
訓練 Composer 2 需要大量的基礎架構開發,包括為在 Blackwell GPU 上高效進行 MoE 訓練而打造的自訂低精度 kernel、橫跨多個地區的全非同步 RL 管線,以及 Anyrun——我們用來執行數十萬個受沙箱隔離的程式設計環境的內部運算平台。報告涵蓋了完整堆疊,包括我們在權重同步、容錯能力與環境保真度方面的做法。
報告也更詳細地說明了這些內容,包括訓練方案的消融實驗、我們調校代理行為的方法,以及評估套件的設計。
感謝 Kimi K2.5、Ray、ThunderKittens、PyTorch 背後的團隊,以及更廣泛的開源社群。我們也要感謝 Fireworks 與 Colfax 的合作與夥伴關係。
完整技術報告可在此讀取。