Cursorでモデル品質を比較する方法
注: CursorBenchは、エージェントの能力の進化に合わせて継続的に更新されています。現在の本番バージョンはCursorBench 3.1です。最新のリーダーボードはそのページをご覧ください。
開発者は、複数のファイル、ツール、工程にまたがる、より長く複雑なタスクをコーディングエージェントに任せるようになっています。こうしたリクエストの対象範囲が広がるにつれ、エージェントの性能を測る評価もそれに合わせて進化する必要があります。
Cursorでは、モデル品質の捉え方を開発者の実際の使い方に合わせ続けるために、オンラインとオフラインを組み合わせたハイブリッドな評価プロセスを採用しています。
オフライン部分では、エンジニアリングチームの実際のCursorセッションをもとにした社内評価スイートのCursorBenchを使っています。タスクは公開リポジトリではなく実際のCursorの使用から得られているため、CursorBenchは公開ベンチマークよりもモデル間の差をより適切に見分けられ、実際の開発者の成果にもより即しています。
私たちは、解の正確性、コード品質、効率性、インタラクションの振る舞いなど、エージェントの性能の複数の側面を測定できるようにCursorBenchを構築しました。このブログでは解の正確性の結果のみを報告していますが、実際にはこれらすべての軸でエージェントを評価しています。
更新、2026年5月: その後、より難しい問題を含むCursorBench 3.1に更新しました。問題の分布が変わったため、CursorBench 3.1のスコアはこの投稿内の数値やグラフとは異なる場合があり、同じ評価バージョン内で比較する必要があります。


私たちは、実トラフィックに対する統制された分析でCursorBenchを補完しています。こうしたオンライン評価により、たとえばエージェントの出力が評価器には正しく見えても、実際に製品を使う開発者には以前より使いにくく感じられる場合のような、オフラインのスイートでは見逃される後退を捉えられます。
このオンライン-オフラインのループによって、ワークフローが変化しても、モデル品質の捉え方を本番環境に根ざしたものに保ちつつ、Cursorで可能な限り優れたエージェント体験を実現できます。
公開ベンチマークの限界
優れたベンチマークは、実運用において異なる振る舞いをするモデルを見分けられ、かつ開発者が実際にそれらのモデルをどう体験するかと一致している必要があります。公開されたオフライン評価は、この両方に課題があります。
1つ目の問題は、整合性です。開発者がエージェントとともに、ますます複雑で多様な作業に取り組むようになるにつれて、静的なベンチマークや実態に合っていないベンチマークは、まったく的外れなものを測ってしまいます。たとえば、多くの SWE ベンチマークは、いまだにバグ修正タスクに重点を置いています。同様に、Terminal-Bench は、盤面の局面から最善手を見つけるといった、幅広いパズル的なタスクを重視しています。私たちは、これらは開発者がエージェントに依頼するコーディング作業とは十分に整合していないと考えています。
2つ目は採点です。多くの公開ベンチマークのタスクは、正解となる解法がごく限られていることを前提としていますが、ほとんどの開発者のリクエストは、複数の妥当なアプローチが成り立つ程度にしか仕様が定まっていません。その結果、ベンチマークは正しい別解を不当に減点するか、あるいは仕様の曖昧さをなくすために人工的な要件を付け加える傾向があります。どちらも、真の性能を正確に評価することはできません。
3つ目は汚染です。SWE-bench Verified、Pro、Multilingual はいずれも、最終的にモデルの学習データに含まれる公開リポジトリからタスクを抽出しており、その結果スコアが水増しされます。OpenAI は最近、最先端レベルのモデルが gold patch を記憶から再現できること、さらに未解決問題のほぼ 60% に不備のあるテストが含まれていたことを受けて、SWE-bench Verified の結果報告を完全にやめました。
その結果、最先端レベルでは、これらのベンチマークでは、開発者にとっての有用性が大きく異なるモデルを見分けられなくなっています。
CursorBench の構築
CursorBench のタスクは、コミット済みのコードを、それを生み出したエージェントへのリクエストまでさかのぼって追跡する Cursor Blame を使って収集しています。これにより、開発者のクエリと正解となる解決策の自然なペアが得られます。多くのタスクは社内コードベースや管理されたソースに由来しており、モデルが学習時にそれらを見ているリスクを抑えられます。開発者がエージェントをどう使うかの変化を追うために、このスイートは数か月ごとに更新しています。
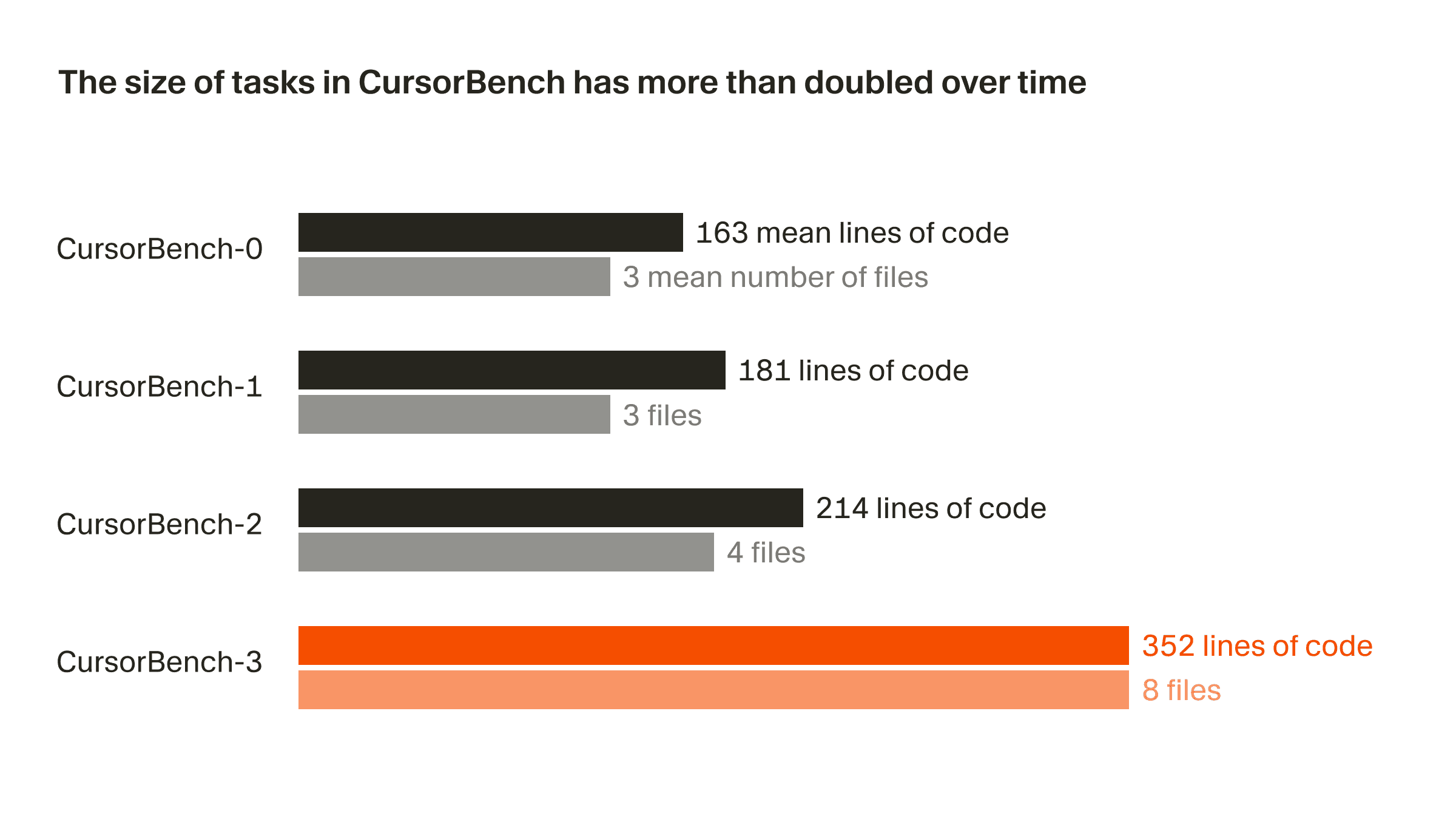
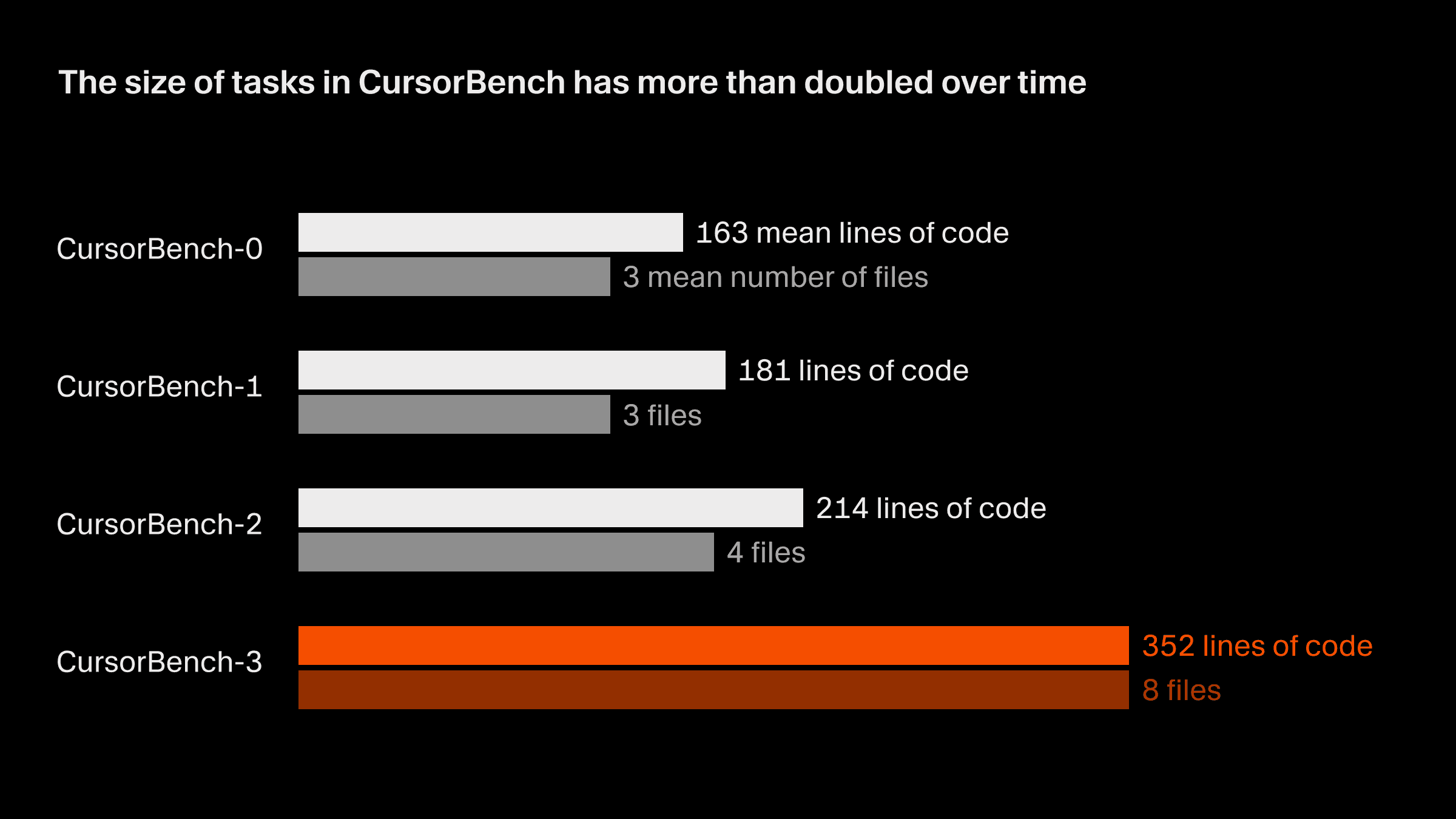
正確性評価における問題の規模は、コード行数と平均ファイル数の両方の点で、初期版から現行版の CursorBench-3 まででおおよそ 2 倍になっています。CursorBench-3 のタスクは SWE-bench Verified、Pro、Multilingual のものより大幅に多くの行数を含みます。コード行数は難しさを測るうえで不完全な指標ではあるものの、この指標での増加は、モノレポを含むマルチワークスペース環境への対応、本番ログの調査、長時間にわたる実験の実行といった、より難しいタスクを CursorBench に取り入れてきたことを反映しています。
CursorBench のタスクは、開発者がエージェントに依頼するときの、仕様が十分に定まっておらず曖昧なことも多い実際の話し方にも合っています。私たちのタスク記述は、公開ベンチマークで使われる詳細な GitHub Issue とは対照的に、意図的に短くしています。また、それらを安定して採点するために、エージェントベースの採点器を使っています。


CursorBench はモデル間の差をより明確に示す
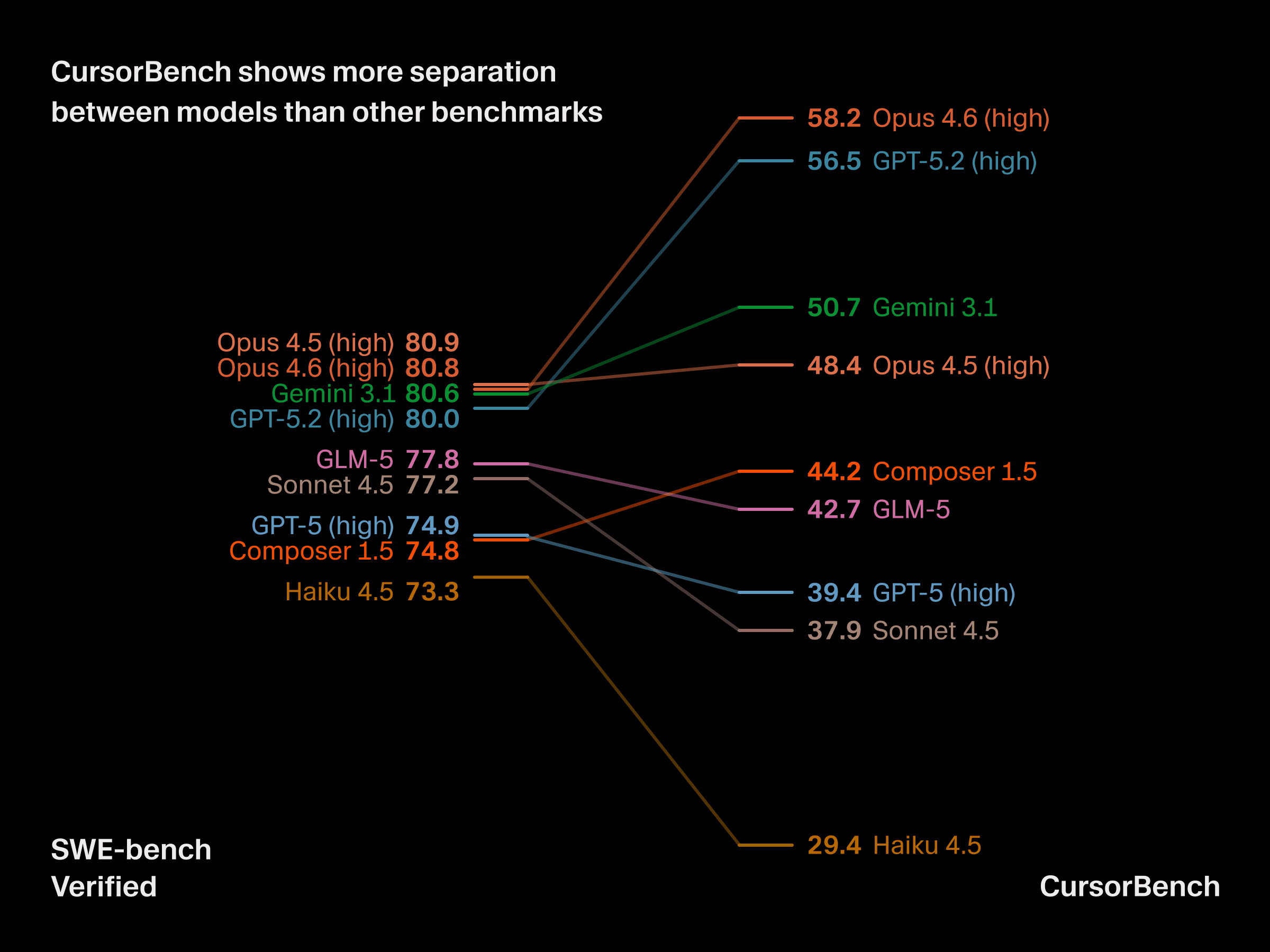
タスクの複雑さや仕様の違いは、ベンチマークの有用性に実践的な影響をもたらします。公開ベンチマークがますます飽和しつつある最先端レベルでは、CursorBench はモデル間の差をより明確に示し、場合によっては Haiku のようなモデルが GPT-5 に匹敵する、あるいは上回ることもあります。CursorBench は、開発者が実際に明確な違いを感じるモデル同士を、安定して見分けられます。

CursorBench のスコアはオンライン評価と整合している
オンライン評価では、エージェントの改善が実際に開発者の役に立っているかどうかを測定します。私たちは、インタラクションと出力品質のシグナルの両方を含む、エージェントの成果に関する高レベルの代理指標群を追跡し、単一の指標だけを最適化するのではなく、それら全体で一貫した変化が見られるかを確認しています。これらを集約することで、オフライン評価ではエージェントの出力が高得点でも、実際には開発者にとってうまく機能していないような後退を捉えられます。
影響を切り分けて把握するために、私たちは統制されたオンライン実験を使っています。たとえば、セマンティック検索とリトリーバルを改善していた際には、セマンティック検索ツールを完全に取り除くアブレーションを実施しました。これにより、大規模なコードベースにおけるリポジトリに基づく質問応答のように、セマンティック検索が特に重要になる場面を特定できました。
CursorBench の順位は、オンライン評価指標で測定される、開発者が Cursor で実際に体験するモデル品質にも、より近い形で対応しています。


次の評価スイート
CursorBench-3 のタスクは公開ベンチマークのタスクより長いものの、依然として 1 回のセッション内で完了します。今後 1 年で、開発作業の大半は、それぞれのコンピューター上で自律的に長時間動作するエージェントへ移っていくと私たちは見込んでおり、それに合わせて CursorBench も適応させていく計画です。そのためには、評価コストを下げる方法を見つけること、外部サービスとやり取りするタスクの再現性を確保すること、そしてオフライン評価と開発者体験とのギャップを埋めることが必要になります。
オンライン-オフラインのループは、私たちが適切だと考える土台を与えてくれており、これを基盤に取り組みを進める中で、今後さらに詳しく共有していく予定です。
コーディングの未来に関わる高度な技術的課題に取り組むことに関心がある方は、hiring@cursor.com までご連絡ください。