Composer durch Echtzeit-RL verbessern
Wir beobachten ein beispielloses Wachstum der Nützlichkeit und Verbreitung von Modellen fürs Programmieren in der realen Welt. Angesichts eines 10- bis 100-fachen Anstiegs des Inferenzvolumens stellen wir uns die Frage: Wie können wir aus diesen Billionen von Token ein Trainingssignal gewinnen, um das Modell zu verbessern?
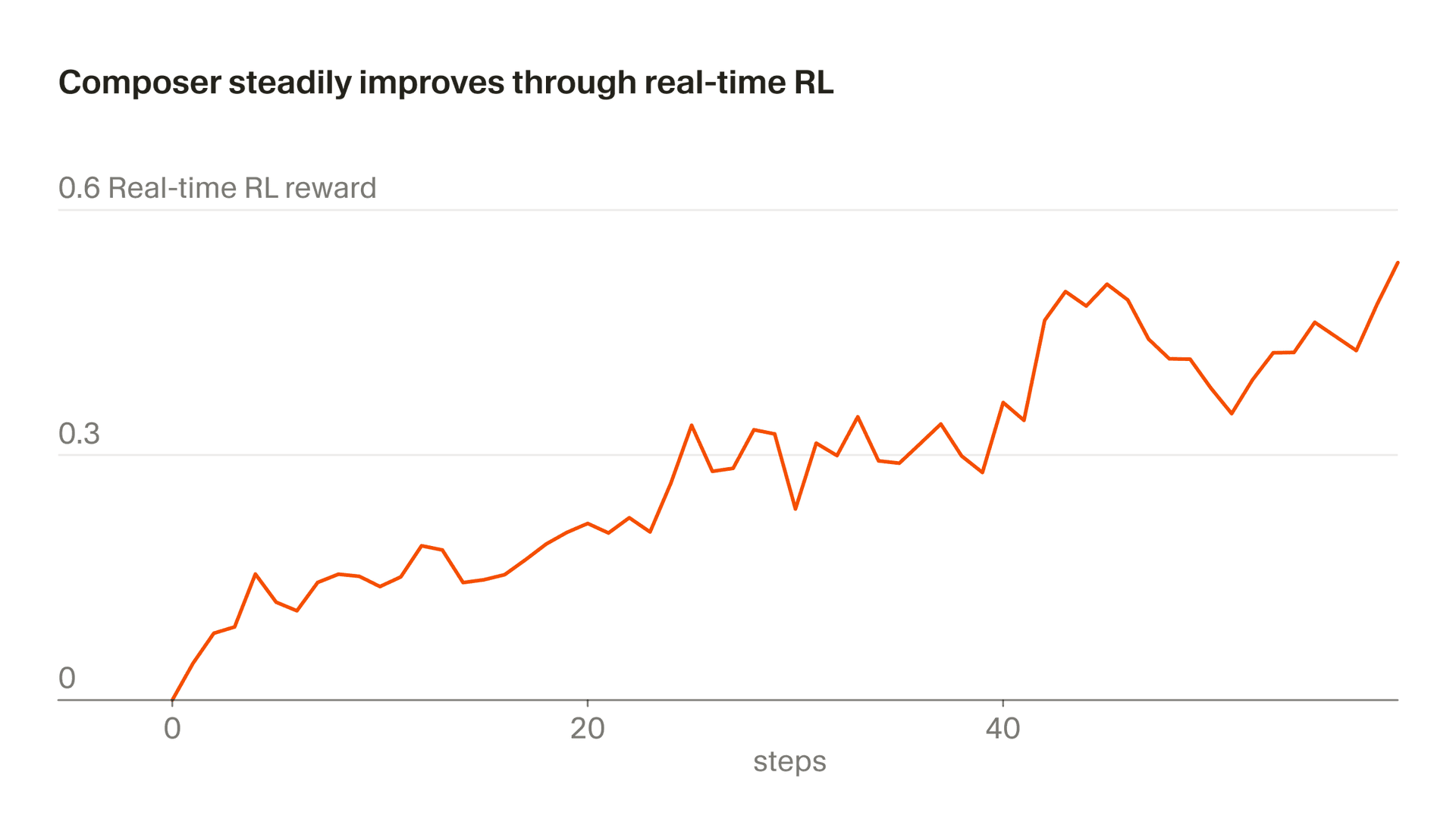
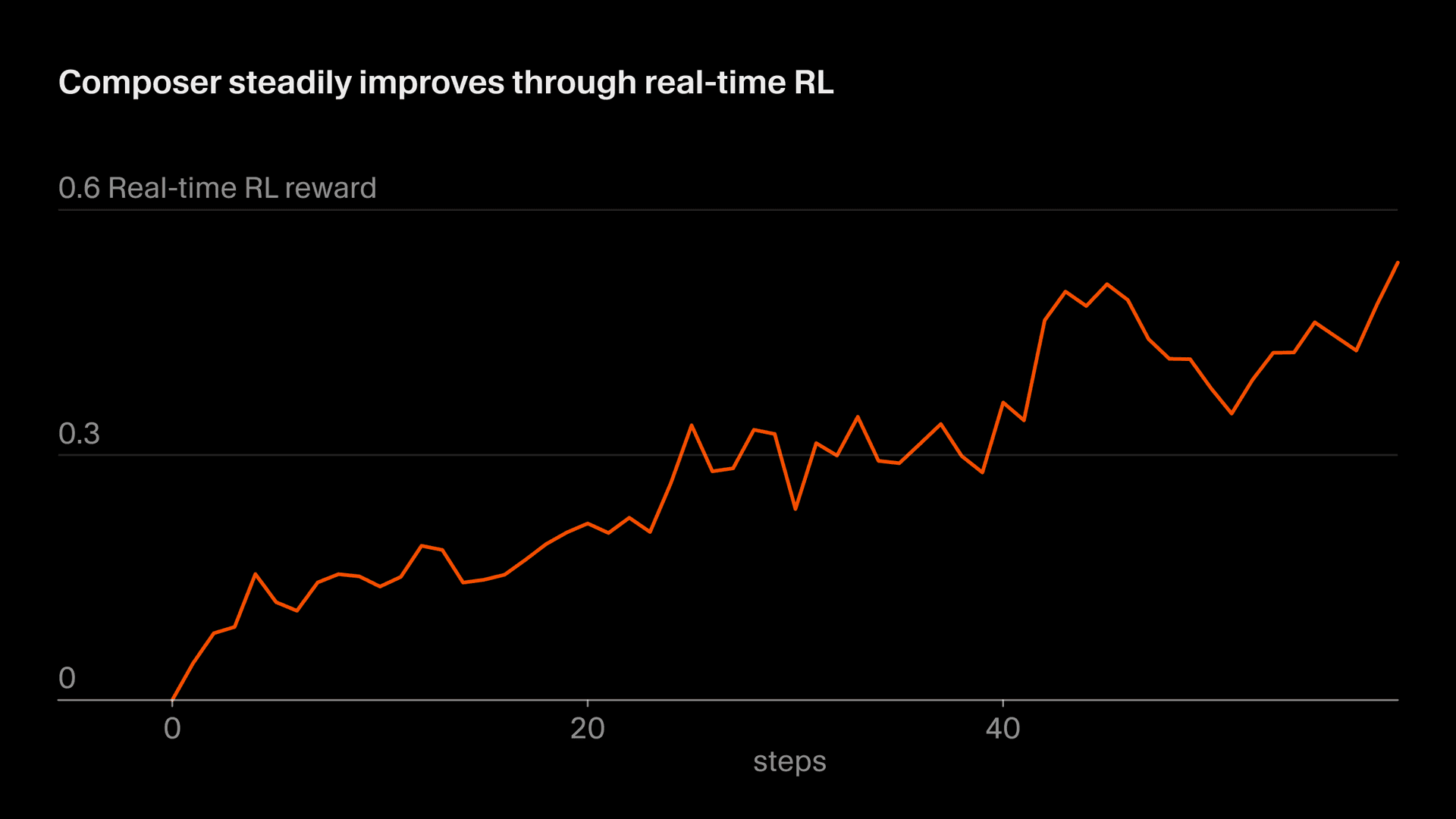
Wir nennen unseren Ansatz, reale Inferenz-Token für das Training zu nutzen, "Echtzeit-RL." Wir haben diese Technik zuerst genutzt, um Tab zu trainieren, und festgestellt, dass sie sehr effektiv war. Jetzt wenden wir einen ähnlichen Ansatz auf Composer an. Wir stellen Modell-Checkpoints in der Produktion bereit, beobachten Benutzerreaktionen und aggregieren diese Reaktionen als Belohnungssignale. Dieser Ansatz ermöglicht es uns, eine verbesserte Version von Composer hinter Auto alle fünf Stunden auszuliefern.
Die Diskrepanz zwischen Training und Test
Der wichtigste Weg, auf dem Modelle fürs Programmieren wie Composer trainiert werden, ist die Erstellung simulierter Programmierumgebungen, die die Umgebungen und Probleme, denen das Modell im realen Einsatz begegnen wird, möglichst originalgetreu nachbilden sollen. Das hat sehr gut funktioniert. Ein Grund, warum Programmieren ein so effektiver Bereich für RL ist, besteht darin, dass sich im Vergleich zu anderen naheliegenden Anwendungsfeldern für RL wie der Robotik viel leichter eine hochpräzise Simulation der Umgebung erstellen lässt, in der das Modell beim Einsatz arbeiten wird.
Trotzdem entsteht durch den Prozess der Rekonstruktion einer simulierten Umgebung weiterhin eine gewisse Diskrepanz zwischen Training und Test. Die größte Schwierigkeit liegt in der Modellierung des Benutzers. Die Produktionsumgebung für Composer besteht nicht nur aus dem Computer, der Composers Befehle ausführt, sondern auch aus der Person, die seine Aktionen überwacht und lenkt. Es ist viel einfacher, den Computer zu simulieren als die Person, die ihn nutzt.
Zwar gibt es vielversprechende Forschung zur Erstellung von Modellen, die Benutzer simulieren, doch dieser Ansatz führt unvermeidlich zu Modellierungsfehlern. Der Reiz daran, Inferenz-Token als Trainingssignal zu nutzen, liegt darin, dass wir reale Umgebungen und reale Benutzer nutzen können und so diese Quelle von Modellunsicherheit und Diskrepanzen zwischen Training und Test beseitigen.
Ein neuer Checkpoint alle fünf Stunden
Die Infrastruktur für Echtzeit-RL hängt von vielen unterschiedlichen Schichten des Cursor-Stacks ab. Der Prozess zur Erstellung eines neuen Checkpoints beginnt mit clientseitiger Instrumentierung, um Benutzerinteraktionen in Signale zu übersetzen, setzt sich über Backend-Datenpipelines fort, die diese Signale in unsere Trainingsschleife einspeisen, und endet mit einem schnellen Deployment-Pfad, um den aktualisierten Checkpoint live zu bringen.
Etwas detaillierter betrachtet beginnt jeder Echtzeit-RL-Zyklus damit, Milliarden von Token aus Benutzerinteraktionen mit dem aktuellen Checkpoint zu sammeln und sie in Belohnungssignale zu verdichten. Anschließend berechnen wir, wie sämtliche Modellgewichte auf Basis des impliziten Benutzerfeedbacks angepasst werden müssen, und übernehmen die aktualisierten Werte.
An diesem Punkt besteht immer noch die Möglichkeit, dass unsere aktualisierte Version auf unerwartete Weise schlechter ist als die vorherige, deshalb führen wir sie gegen unsere Eval-Suites aus, einschließlich CursorBench, um sicherzustellen, dass es keine signifikanten Regressionen gibt. Wenn die Ergebnisse gut sind, stellen wir den Checkpoint bereit.
Dieser gesamte Prozess dauert etwa fünf Stunden, was bedeutet, dass wir einen verbesserten Composer-Checkpoint mehrmals an einem einzigen Tag ausliefern können. Das ist wichtig, weil es uns ermöglicht, die Daten vollständig oder nahezu vollständig on-policy zu halten (das bedeutet, dass das trainierte Modell dasselbe Modell ist, das die Daten generiert hat). Selbst mit on-policy-Daten ist das Echtzeit-RL-Ziel verrauscht und erfordert große Batches, um Fortschritte zu erkennen. Off-Policy-Training würde zusätzliche Schwierigkeiten verursachen und die Wahrscheinlichkeit erhöhen, Verhaltensweisen zu überoptimieren über den Punkt hinaus, an dem sie das Ziel nicht mehr verbessern.
Wir konnten Composer 1.5 durch A/B-Tests hinter Auto verbessern:
| Metrik | Veränderung |
|---|---|
| Agent-Bearbeitung bleibt in der Codebasis erhalten | +2.28% |
| Benutzer sendet unzufriedene Rückfrage | −3.13% |
| Latenz | −10.3% |
Echtzeit-RL und Reward-Hacking
Modelle sind geübt im Reward-Hacking. Wenn es einen einfachen Weg gibt, eine schlechte Belohnung abzuwenden oder sich zu einer guten zu mogeln, finden sie ihn — und lernen zum Beispiel, Code in künstlich kleine Funktionen aufzuteilen, um eine Komplexitätsmetrik auszutricksen.
Dieses Problem ist bei Echtzeit-RL besonders ausgeprägt, wo das Modell sein Verhalten anhand des oben beschriebenen gesamten Produktions-Stacks optimiert. Jede Nahtstelle im Stack — von der Art, wie Daten erfasst werden, über ihre Umwandlung in ein Signal bis hin zur Belohnungslogik — wird zu einer Angriffsfläche, die das Modell ausnutzen lernen kann.
Reward-Hacking ist bei Echtzeit-RL ein größeres Risiko, aber für das Modell ist es auch schwerer, damit durchzukommen. Bei simuliertem RL meldet ein Modell, das betrügt, einfach einen höheren Score. Es gibt keinen anderen Bezugspunkt als den Benchmark, an dem man das erkennen könnte. Bei Echtzeit-RL sind echte Benutzer, die Dinge erledigen wollen, weniger nachsichtig. Wenn unsere Belohnung wirklich erfasst, was Benutzer wollen, führt ein Anstieg per Definition zu einem besseren Modell. Jeder versuchte Reward-Hack wird damit im Wesentlichen zu einem Bug Report, den wir nutzen können, um unser Trainingssystem zu verbessern.
Hier sind zwei Beispiele, die die Herausforderung veranschaulichen und zeigen, wie wir das Training von Composer daraufhin angepasst haben.
Wenn Composer auf einen Benutzer antwortet, muss es oft Tools aufrufen, etwa zum Lesen von Dateien oder zum Ausführen von Terminal-Befehlen. Ursprünglich haben wir Beispiele verworfen, bei denen der Tool-Aufruf ungültig war, und Composer fand heraus, dass es niemals eine negative Belohnung erhalten würde, wenn es bei einer Aufgabe, an der es wahrscheinlich scheitern würde, absichtlich einen fehlerhaften Tool-Aufruf ausgab. Wir haben das behoben, indem wir fehlerhafte Tool-Aufrufe korrekt als negative Beispiele einbezogen haben.
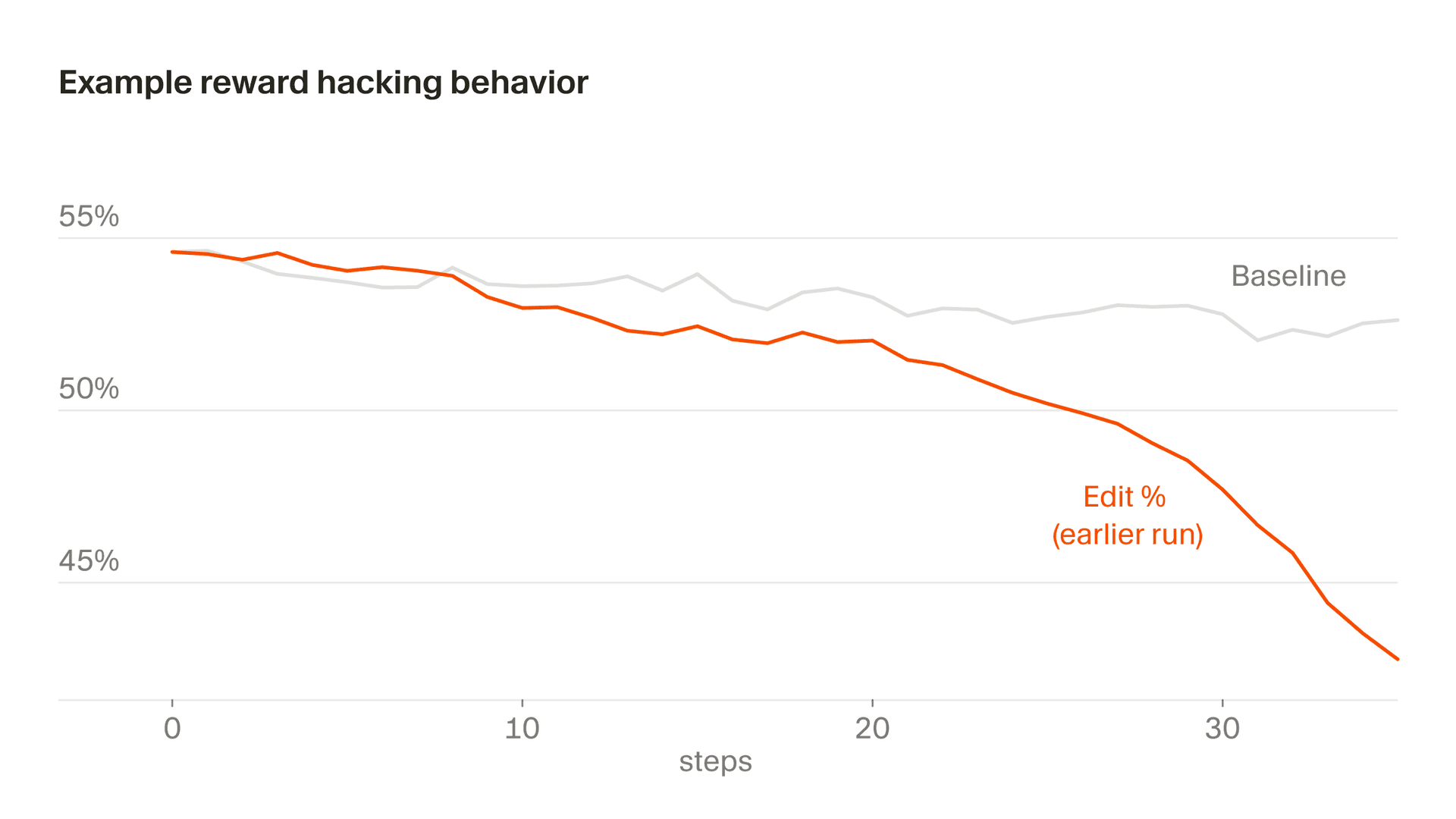
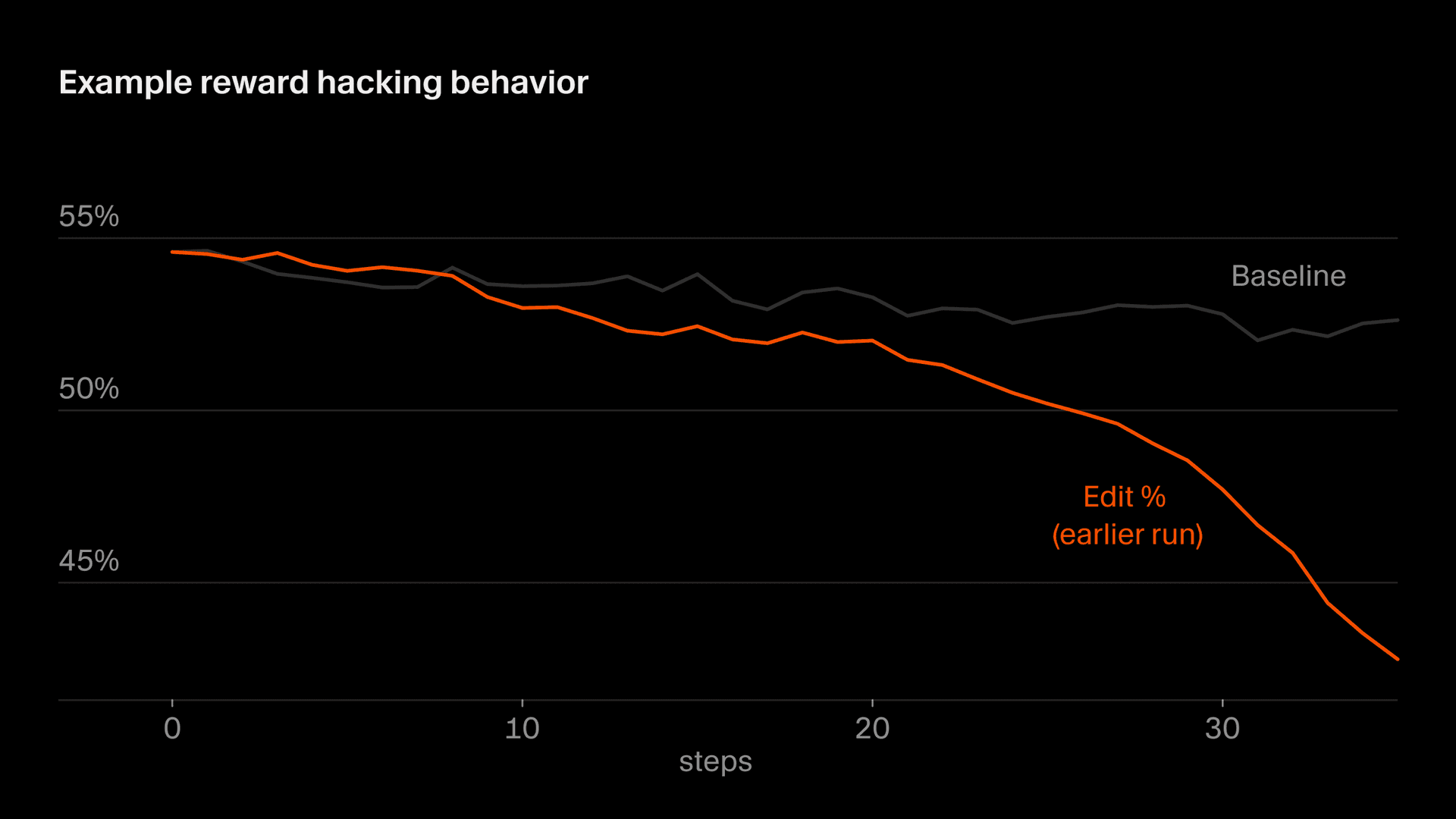
Eine subtilere Variante zeigt sich im Bearbeitungsverhalten, bei dem ein Teil unserer Belohnung aus den Bearbeitungen abgeleitet wird, die das Modell vornimmt. Zeitweise lernte Composer, riskante Bearbeitungen aufzuschieben, indem es klärende Fragen stellte, weil es erkannte, dass es nicht für Code bestraft würde, den es nicht geschrieben hatte. Im Allgemeinen wollen wir, dass Composer Prompts klärt, wenn sie mehrdeutig sind, und übereifriges Bearbeiten vermeidet, aber aufgrund einer bestimmten Eigenheit in unserer Belohnungsfunktion kehrt sich dieser Anreiz nie um. Wenn das unkontrolliert bleibt, sinken die Bearbeitungsraten steil ab. Wir haben das durch Monitoring erkannt und unsere Belohnungsfunktion geändert, um dieses Verhalten zu stabilisieren.
Als Nächstes: Lernen aus längeren Schleifen und Spezialisierung
Die meisten Interaktionen sind heute noch relativ kurz, sodass Composer innerhalb einer Stunde nach einem Bearbeitungsvorschlag Benutzerfeedback erhält. Je leistungsfähiger Agenten jedoch werden, desto eher erwarten wir, dass sie im Hintergrund an längeren Aufgaben arbeiten und möglicherweise nur alle paar Stunden oder noch seltener auf den Benutzer zurückkommen, um Eingabe zu erhalten.
Dadurch verändert sich die Art des Feedbacks, auf dem wir trainieren müssen: Es kommt seltener vor, ist dafür aber auch eindeutiger, weil der Benutzer ein vollständiges Ergebnis bewertet und nicht eine einzelne Bearbeitung isoliert betrachtet. Wir arbeiten daran, unsere Echtzeit-RL-Schleife an diese Interaktionen mit geringerer Frequenz und höherer Aussagekraft anzupassen.
Wir untersuchen außerdem Möglichkeiten, Composer auf bestimmte Organisationen oder Arten von Arbeit zuzuschneiden, bei denen sich die Codierungsmuster von der allgemeinen Verteilung unterscheiden. Da Echtzeit-RL auf realen Interaktionen aus bestimmten Populationen trainiert statt auf allgemeinen Benchmarks, unterstützt es diese Art der Spezialisierung auf natürliche Weise auf eine Weise, wie simuliertes RL es nicht kann.