Wie wir die Modellqualität in Cursor vergleichen
Hinweis: CursorBench wird fortlaufend aktualisiert, da sich die Fähigkeiten der Agenten weiterentwickeln. Die aktuelle Produktionsversion ist CursorBench 3.1; die neueste Bestenliste findest du auf dieser Seite.
Entwickler übertragen Coding-Agenten immer längere und komplexere Aufgaben, die sich über mehrere Dateien, Tools und Schritte erstrecken. Mit dem wachsenden Umfang dieser Anfragen müssen sich auch die Evals weiterentwickeln, mit denen wir die Leistung von Agenten messen.
Bei Cursor nutzen wir einen hybriden Online-Offline-Eval-Prozess, damit unser Verständnis der Modellqualität mit dem übereinstimmt, was Entwickler tatsächlich tun.
Der Offline-Teil nutzt CursorBench, unsere interne Eval-Suite auf Basis echter Cursor-Sitzungen aus unserem Engineering-Team. Da die Aufgaben aus der tatsächlichen Nutzung von Cursor stammen und nicht aus öffentlichen Repositories, kann CursorBench Modelle besser voneinander unterscheiden und bildet reale Ergebnisse für Entwickler besser ab als öffentliche Benchmarks.
Wir haben CursorBench entwickelt, um mehrere Dimensionen der Agent-Leistung zu messen, darunter Lösungskorrektheit, Codequalität, Effizienz und Interaktionsverhalten. Dieser Blog konzentriert sich auf Ergebnisse zur Lösungskorrektheit, aber in der Praxis evaluieren wir Agenten entlang all dieser Achsen.
Update, Mai 2026: Inzwischen haben wir CursorBench mit schwierigeren Problemen auf Version 3.1 aktualisiert. Da sich die Problemverteilung geändert hat, können die Scores von CursorBench 3.1 von den Zahlen und Diagrammen in diesem Beitrag abweichen und sollten nur innerhalb derselben Eval-Version verglichen werden.


Wir ergänzen CursorBench durch kontrollierte Analysen auf Live-Traffic. Diese Online-Evals erfassen Regressionen, die Offline-Suites übersehen, etwa wenn die Ausgabe des Agenten für einen Bewerter korrekt aussieht, sich für einen Entwickler im Produkt aber schlechter anfühlt.
Gemeinsam sorgt dieser Online-Offline-Kreislauf dafür, dass unser Verständnis von Modellqualität in der Produktion verankert bleibt, auch wenn sich Workflows verändern, und ermöglicht es uns, in Cursor die bestmögliche Agent-Erfahrung zu schaffen.
Die Grenzen öffentlicher Benchmarks
Ein guter Benchmark muss zwischen Modellen unterscheiden können, die in der Praxis unterschiedlich gut abschneiden, und zugleich widerspiegeln, wie Entwickler diese Modelle tatsächlich erleben. Öffentliche Offline-Evals haben mit beidem Schwierigkeiten.
Das erste Problem ist die Ausrichtung. Da Entwickler mit Agent zunehmend komplexere und vielfältigere Aufgaben übernehmen, testen statische oder schlecht ausgerichtete Benchmarks am Ende oft völlig die falschen Dinge. Die meisten SWE-Benchmarks konzentrieren sich zum Beispiel noch immer auf Bugfixing-Aufgaben. Ebenso legt Terminal-Bench den Schwerpunkt auf allgemeine, rätselartige Aufgaben wie das Finden des besten Schachzugs aus einer bestimmten Brettposition. Unserer Einschätzung nach passt das nicht gut zu der Programmierarbeit, um die Entwickler Agent bitten.
Das zweite Problem ist die Bewertung. Viele öffentliche Benchmark-Aufgaben gehen von einem engen Spektrum richtiger Lösungen aus, aber die meisten Anfragen von Entwicklern sind so wenig spezifiziert, dass viele gültige Ansätze möglich sind. Dadurch bestrafen Benchmarks tendenziell entweder alternative, aber richtige Lösungswege oder fügen künstliche Anforderungen hinzu, um diese Unterspezifikation zu beseitigen. Beides liefert keine genaue Einschätzung der tatsächlichen Leistung.
Das dritte Problem ist Kontamination. SWE-bench Verified, Pro und Multilingual beziehen ihre Aufgaben alle aus öffentlichen Repositories, die in den Trainingsdaten der Modelle landen und dadurch die Ergebnisse künstlich in die Höhe treiben. OpenAI hat kürzlich ganz aufgehört, Ergebnisse für SWE-bench Verified zu veröffentlichen, nachdem festgestellt wurde, dass führendes Modell die Referenz-Patches aus dem Gedächtnis reproduzieren konnten und dass fast 60 % der ungelösten Probleme fehlerhafte Tests hatten.
Das Ergebnis ist, dass diese Benchmarks auf Spitzenniveau nicht mehr zwischen Modellen unterscheiden, die für Entwickler einen sehr unterschiedlichen Nutzen haben.
So entsteht CursorBench
Wir beziehen Aufgaben für CursorBench über Cursor Blame. Damit lässt sich committeter Code bis zu der Agent-Anfrage zurückverfolgen, durch die er entstanden ist. So erhalten wir eine natürliche Zuordnung von Entwickleranfrage und Ground-Truth-Lösung. Viele Aufgaben stammen aus unserer internen Codebasis und aus kontrollierten Quellen. Das verringert das Risiko, dass Modelle sie bereits im Training gesehen haben. Wir aktualisieren die Suite alle paar Monate, um Veränderungen darin nachzuverfolgen, wie Entwickler Agent nutzen.
Der Problemumfang in unseren Korrektheits-Evaluierungen hat sich von der ersten Version bis zur aktuellen, CursorBench-3, sowohl bei den Codezeilen als auch bei der durchschnittlichen Anzahl von Dateien ungefähr verdoppelt. CursorBench-3-Aufgaben umfassen deutlich mehr Zeilen als jene in SWE-bench Verified, Pro oder Multilingual. Codezeilen sind zwar kein perfektes Maß für Schwierigkeit, doch das Wachstum bei dieser Kennzahl zeigt, wie wir CursorBench um anspruchsvollere Aufgaben erweitert haben, etwa den Umgang mit Multi-Workspace-Umgebungen mit Monorepos, die Untersuchung von Produktionslogs und die Durchführung lang laufender Experimente.
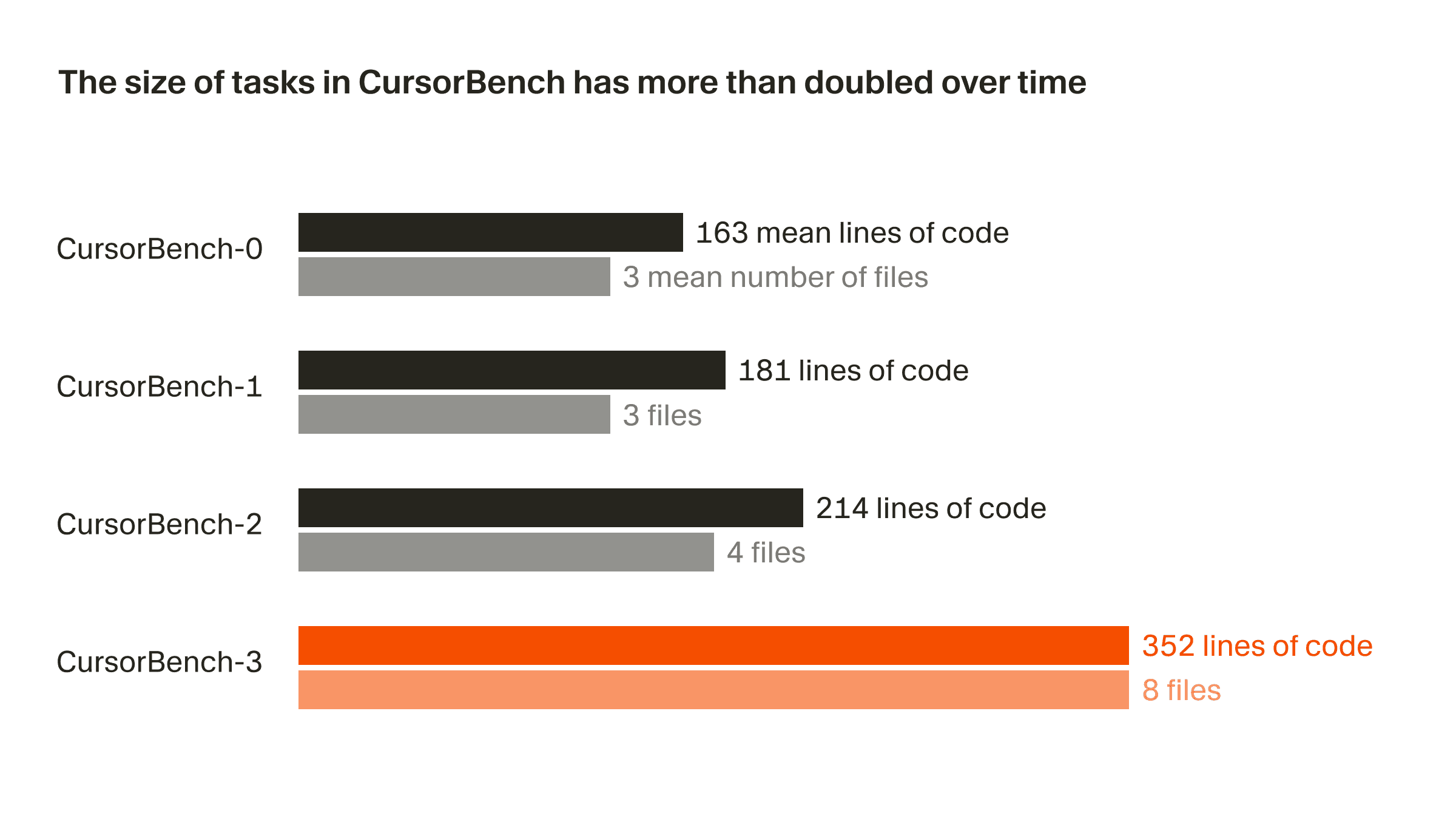
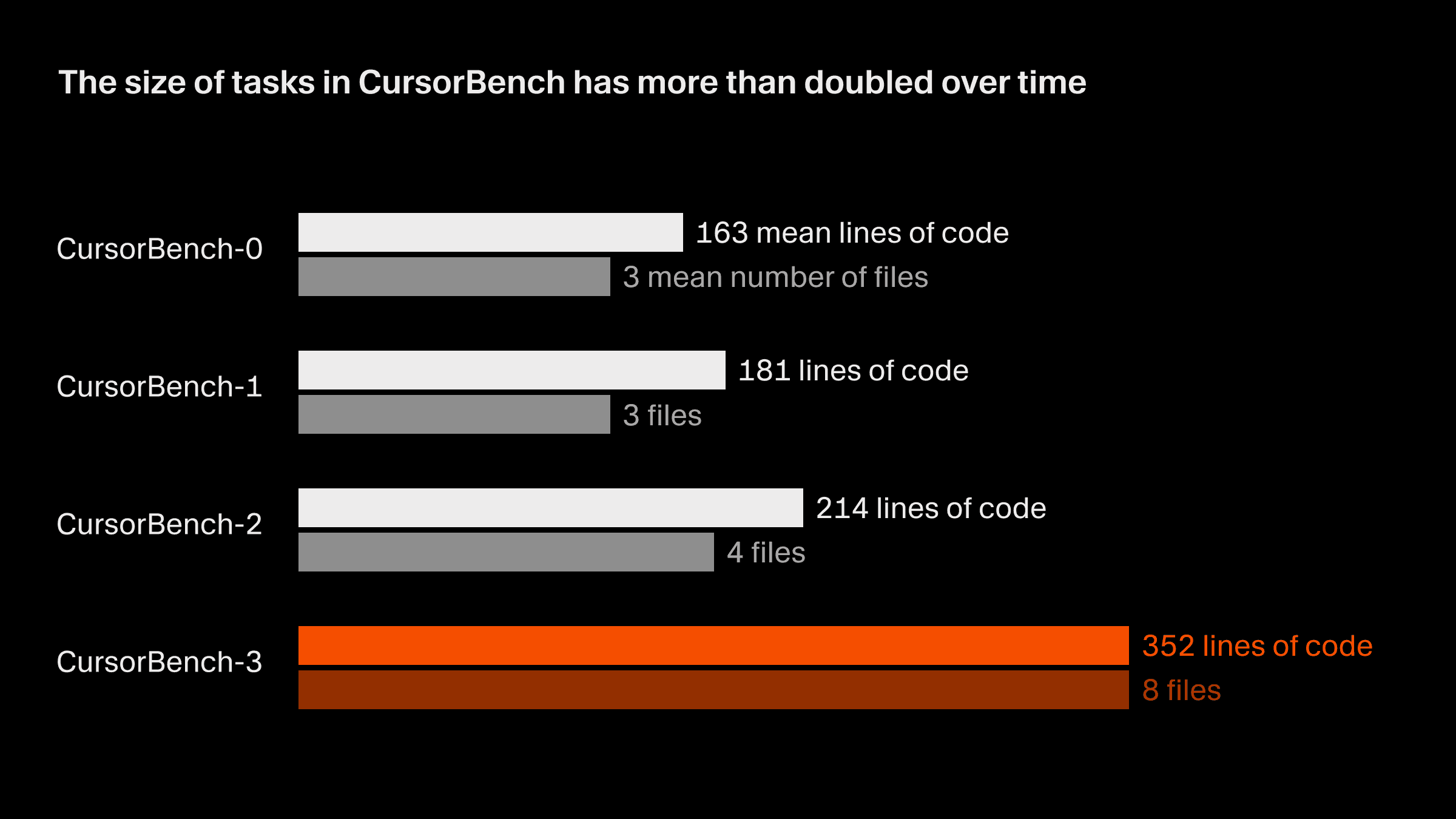
CursorBench-Aufgaben entsprechen außerdem der unterbestimmten, oft mehrdeutigen Art, wie Entwickler mit Agent kommunizieren. Unsere Aufgabenbeschreibungen sind bewusst kurz – im Gegensatz zu den detaillierten GitHub-Issues aus öffentlichen Benchmarks – und wir nutzen agentische Bewerter, um sie zuverlässig zu bewerten.


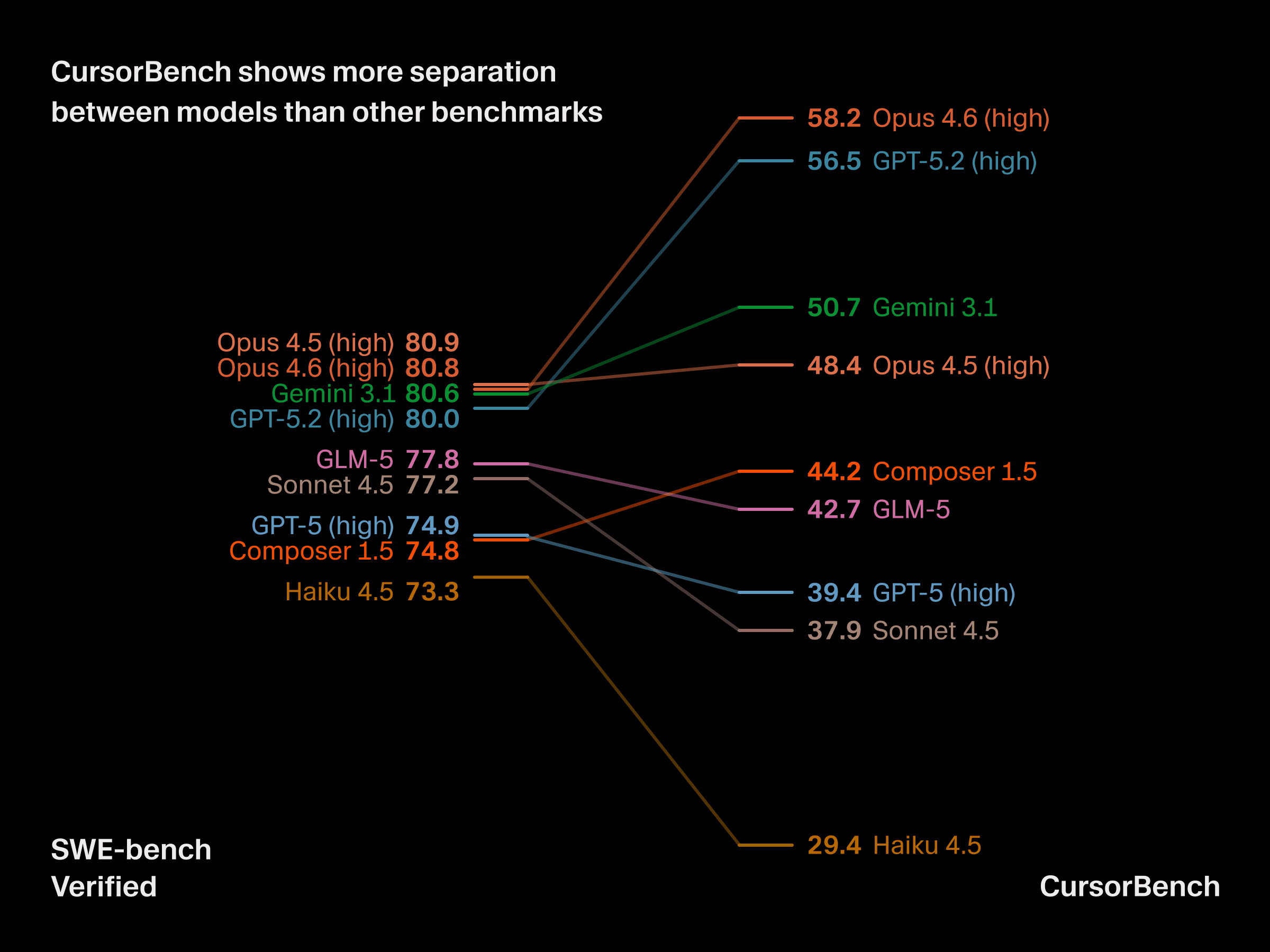
CursorBench zeigt deutlichere Unterschiede zwischen Modellen
Diese Unterschiede bei Aufgabenkomplexität und Spezifikation haben praktische Folgen für den Nutzen von Benchmarks. CursorBench zeigt bei Modellen auf Frontier-Niveau deutlichere Unterschiede, während öffentliche Benchmarks zunehmend an ihre Grenzen stoßen, und in manchen Fällen können Modelle wie Haiku mit GPT-5 mithalten oder es sogar übertreffen. CursorBench unterscheidet zuverlässig zwischen Modellen, die Entwickler in der Praxis als deutlich unterschiedlich erleben.

CursorBench-Ergebnisse stimmen mit Online-Evaluierungen überein
Die Online-Evaluierung misst, ob Verbesserungen an unserem Agent Entwicklern in der Praxis tatsächlich helfen. Wir verfolgen eine Reihe übergeordneter Proxy-Metriken für die Ergebnisse des Agent, darunter sowohl Signale zur Interaktion als auch zur Qualität der Ausgabe, und achten darauf, dass sie sich konsistent entwickeln, anstatt auf eine einzelne Metrik zu optimieren. Durch diese Aggregation können wir Regressionen erkennen, bei denen die Ausgabe des Agent in einer Offline-Bewertung zwar gut abschneidet, in der Praxis für Entwickler aber nicht wirklich gut funktioniert.
Wir nutzen kontrollierte Online-Experimente, um Auswirkungen klar zuzuordnen. Als wir beispielsweise an semantischer Suche und Retrieval arbeiteten, führten wir eine Ablation durch, bei der das Tool für semantische Suche vollständig entfernt wurde. So konnten wir genau die Szenarien bestimmen, in denen semantische Suche am wichtigsten war, etwa bei repository-gestützter Fragebeantwortung in größeren Codebasen.
CursorBench-Rankings bilden außerdem genauer ab, wie Entwickler die Modellqualität in Cursor erleben, gemessen an unseren Online-Evaluierungsmetriken.


Die nächste Eval-Suite
Während CursorBench-3-Aufgaben länger sind als Aufgaben in öffentlichen Benchmarks, lassen sie sich immer noch innerhalb einer einzigen Sitzung lösen. Wir gehen davon aus, dass sich im Laufe des nächsten Jahres der weitaus größte Teil der Entwicklungsarbeit auf langlaufende Agenten verlagern wird, die auf ihren eigenen Rechnern arbeiten, und wir planen, CursorBench entsprechend anzupassen. Dafür müssen wir Wege finden, die Auswertung kostengünstiger zu machen, die Reproduzierbarkeit für Aufgaben zu gewährleisten, die mit externen Diensten interagieren, und die Lücke zwischen Offline-Bewertung und Developer Experience zu schließen.
Der Online-Offline-Kreislauf bietet aus unserer Sicht die richtige Grundlage, und wir planen, mehr darüber zu teilen, während wir darauf aufbauen.
Wenn du daran interessiert bist, an anspruchsvollen technischen Problemen rund um die Zukunft des Codings zu arbeiten, melde dich unter hiring@cursor.com.