我們如何在 Cursor 比較模型品質
注意: CursorBench 會隨著代理能力演進而持續更新。目前正式環境版本為 CursorBench 3.1;最新排行榜請參閱該頁面。
開發者正要求編碼代理承擔更長、更複雜的任務,涵蓋多個檔案、工具與步驟。隨著這些請求的範圍持續擴大,用來衡量代理表現的評估方式也必須隨之演進。
在 Cursor,我們採用混合式線上-離線評估流程,確保我們對模型品質的理解與開發者實際的使用情境保持一致。
離線部分使用 CursorBench,這是我們根據工程團隊真實 Cursor 工作階段打造的內部 eval 套件。由於任務來自實際的 Cursor 使用情境,而非公開儲存庫,CursorBench 不僅更能區分不同模型的表現,也比公開基準測試更貼近真實的開發者結果。
我們打造 CursorBench 是為了衡量代理表現的多個面向,包括解決方案正確性、程式碼品質、效率與互動行為。這篇部落格聚焦於解決方案正確性的結果,但在實務中,我們會從所有這些面向評估代理。
更新,2026 年 5 月: 此後我們已將 CursorBench 更新至 3.1,並加入更高難度的問題。由於問題分布已改變,CursorBench 3.1 的分數可能會與本文中的數字和圖表不同,因此應在相同的 eval 版本內進行比較。


我們以真實流量上的受控分析來補充 CursorBench。這些線上評估能捕捉離線套件遺漏的回歸問題,例如代理的輸出對評分器來說看似正確,但對實際使用產品的開發者而言,體驗卻更差。
這個線上-離線循環結合起來,讓我們對模型品質的判斷能隨工作流程變化而持續立足於實際正式環境,並讓我們能在 Cursor 中打造最佳的代理體驗。
公開基準測試的侷限
好的基準必須能區分在實際使用中表現不同的模型,並且貼近開發者實際使用這些模型的體驗。公開的離線評估在這兩點上都做得不好。
第一個問題是貼合度。隨著開發者開始與代理一起處理日益複雜且多樣的工作,靜態或不貼切的基準最終會完全測錯方向。舉例來說,大多數 SWE 基準仍然著重於修正錯誤的任務。同樣地,Terminal-Bench 強調的是偏廣泛、偏謎題式的任務,例如根據棋盤局面找出最佳的西洋棋步。我們認為,這些任務與開發者要求代理執行的程式設計工作並不十分吻合。
第二個問題是評分。許多公開基準任務都假設只有一小組正確解法,但大多數開發者的請求本身規格並不夠完整,因此往往容許多種合理作法。結果是,基準不是會懲罰其他同樣正確的替代方案,就是會額外加入人為設計的要求來消除這種規格不完整。這兩種做法都無法準確反映真實表現。
第三個問題是污染。SWE-bench Verified、Pro 和 Multilingual 都是從公開儲存庫中抽取任務,而這些任務最終會進入模型訓練資料,進而灌高分數。OpenAI 最近 發現,前沿模型可以憑記憶重現標準修補程式,而且近 60% 的未解決問題都存在有缺陷的測試,因此已完全停止報告 SWE-bench Verified 的結果。
結果是,在前沿水準下,這些基準已無法再區分那些對開發者實用性差異極大的模型。
打造 CursorBench
我們使用 Cursor Blame 為 CursorBench 蒐集任務;這項功能會將已提交的程式碼追溯到產生該程式碼的代理請求。這讓我們能自然地將開發者的查詢與標準答案解決方案配對。許多任務來自我們的內部程式碼庫與受控來源,因此可降低模型在訓練時看過這些任務的風險。我們每隔幾個月就會更新一次這套基準,以追蹤開發者使用代理方式的變化。
我們正確性評估中的問題範圍,就程式碼行數與平均檔案數而言,從初始版本到目前的 CursorBench-3 大約擴大了一倍。CursorBench-3 的任務所涉及的程式碼行數,明顯多於 SWE-bench Verified、Pro 或 Multilingual。雖然程式碼行數並不是衡量難度的完美指標,但這項指標的成長反映出我們已將更具挑戰性的任務納入 CursorBench,例如處理含 monorepo 的多工作區環境、調查正式環境日誌,以及執行長時間運行的實驗。
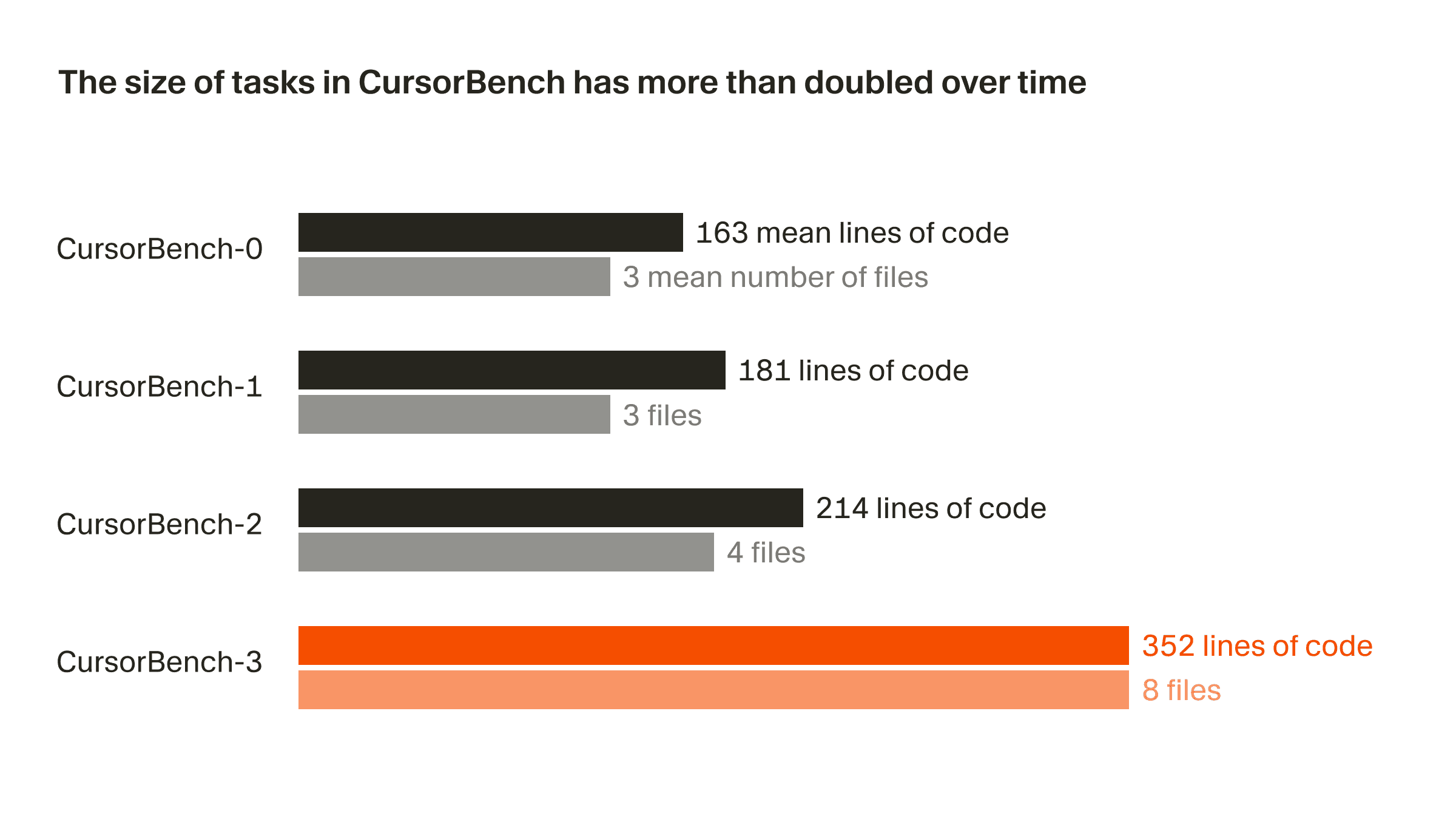
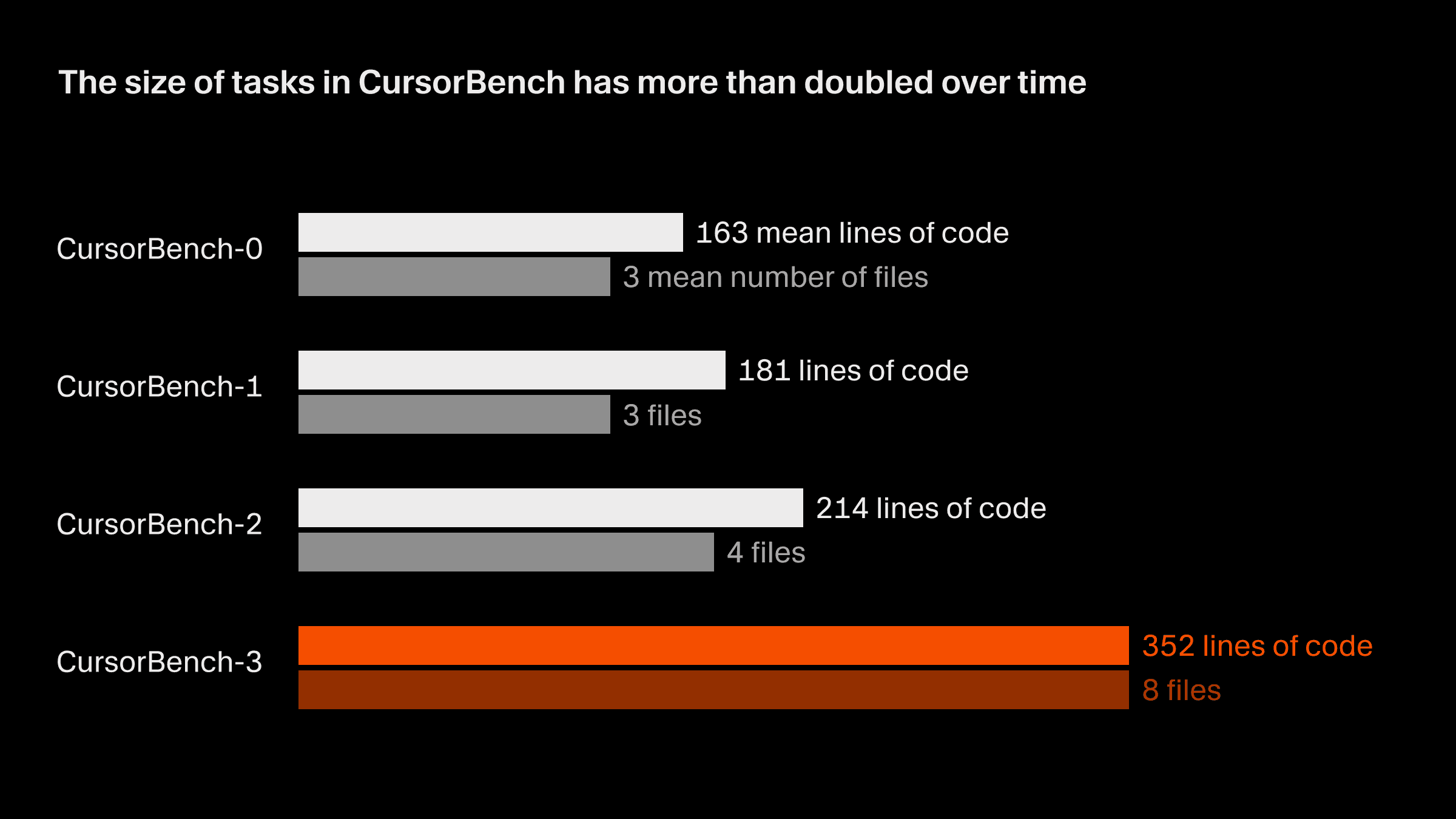
CursorBench 任務也貼近開發者與代理溝通時那種規格不完整、且常帶有歧義的表達方式。相較於公開基準測試中取自 GitHub 議題的詳細描述,我們的任務描述刻意保持簡短,並使用代理式評分器來可靠評分。


CursorBench 顯示出模型之間更明顯的區分度
這些任務複雜度與規格上的差異,對基準測試的實用性有實際影響。在公開基準測試於前沿水準日益飽和之際,CursorBench 能在模型之間產生更明顯的區分度,而且在某些情況下,像 Haiku 這樣的模型可以媲美甚至超越 GPT-5。CursorBench 能可靠地區分那些開發者實際感受到具有明顯差異的模型。

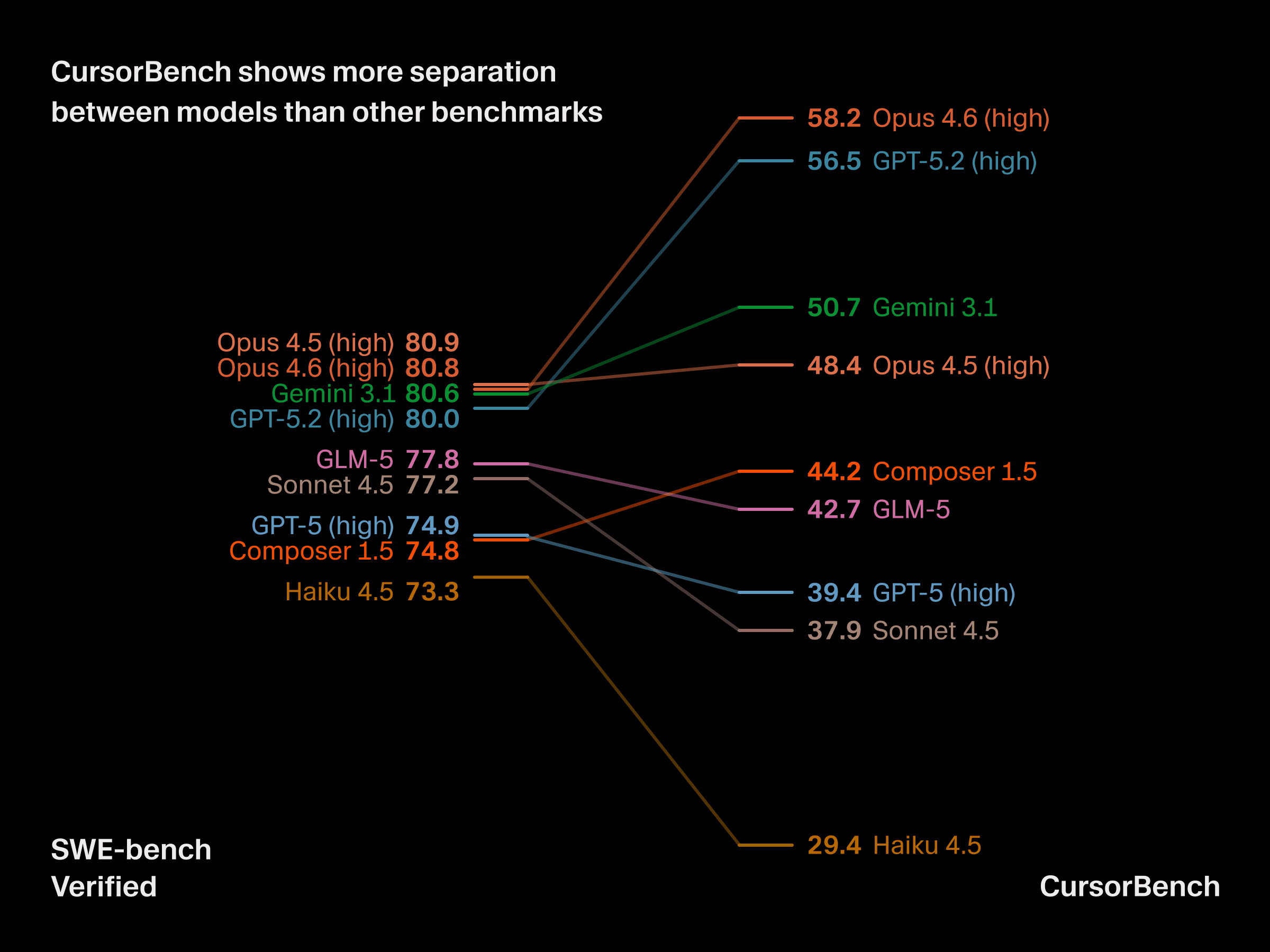
CursorBench 分數與線上評估結果一致
線上評估衡量的是,我們對代理所做的改進是否真的能在實務中幫助開發者。我們會追蹤一組可反映代理成效的高階替代指標,其中包括互動與輸出品質的訊號,並觀察這些指標是否一致變動,而不是只針對單一指標進行最佳化。將這些指標彙整起來後,我們就能發現這類退步情況:代理輸出在離線評分器下分數很高,但實際上對開發者並不好用。
我們使用受控的線上實驗來歸因成效。例如,在迭代語意搜尋與檢索時,我們進行了一次消融實驗,將語意搜尋工具完全移除。這讓我們能精確找出語意搜尋最重要的情境,例如在較大型程式碼庫中,以儲存庫為基礎的問答。
CursorBench 排名也更貼近開發者在 Cursor 中實際體驗到的模型品質,這是由我們的線上評估指標所衡量的。


下一個 eval 套件
雖然 CursorBench-3 的任務比公開基準測試上的任務更長,但仍可在單次工作階段內完成。我們預期在未來一年內,絕大多數的開發工作將轉向由長時間運行、在各自電腦上自行工作的代理來執行,我們也正規劃據此調整 CursorBench。要做到這一點,我們需要找到降低評分成本的方法、解決與外部服務互動之任務的可重現性問題,並縮小離線評估與開發者體驗之間的落差。
線上—離線循環為我們奠定了我們認為正確的基礎,而隨著我們在此基礎上持續打造,我們也規劃分享更多內容。
如果你有興趣投入與程式設計未來相關的深層技術問題,請聯絡 hiring@cursor.com。