섀도우 워크스페이스로 반복 개발하기
실패를 부르는 레시피가 있다. 관련 있는 파일 몇 개를 Google Doc에 붙여 넣고, 당신의 코드베이스에 대해 아무것도 모르는 단골 p60 소프트웨어 엔지니어에게 링크를 보내, 그 문서 안에서 다음 PR을 완전하고 정확하게 구현해 달라고 요청해 보는 것이다.
AI에게 똑같이 시켜도, 예상대로 마찬가지로 실패할 것이다.
이제, 대신 그들에게 당신의 개발 환경에 대한 원격 접근 권한을 주고, 린트 결과를 보고, 정의로 이동하고, 코드를 실행할 수 있도록 해 준다면, 실제로 어느 정도는 도움이 될 것이라고 기대할 수 있다.
우리는 AI가 더 많은 코드를 작성할 수 있게 해 주는 핵심 요소 중 하나가, 개발 환경 안에서 반복적으로 작업할 수 있는 능력이라고 믿는다. 하지만 단순하게 AI가 당신의 폴더 안에서 마음대로 돌아다니게 두면 혼란이 벌어진다. 공을 많이 들여 복잡한 추론이 필요한 함수를 작성해 놨는데 AI가 그것을 덮어쓴다거나, 프로그램을 실행하려고 하는데 AI가 컴파일되지 않는 코드를 집어넣는 상황을 상상해 보라. 실제로 도움이 되려면, AI의 반복 작업은 당신의 코딩 경험에 영향을 주지 않고 백그라운드에서 일어나야 한다.
이를 위해 우리는 Cursor에 **섀도우 워크스페이스(shadow workspace)**라고 부르는 것을 구현했다. 이 블로그 글에서 나는 먼저 우리의 설계 기준을 개괄하고, 이어서 글을 쓰는 시점에 Cursor에 존재하는 구현(숨겨진 Electron 창)과, 앞으로 우리가 그것을 어디까지 확장하려 하는지(커널 수준 폴더 프록시)에 대해 설명하겠다.

디자인 기준
우리는 섀도우 워크스페이스(shadow workspace)가 다음 목표를 달성하길 바랍니다:
-
LSP 사용성: AI가 자신의 변경으로 인한 린트 결과를 보고, 정의로 바로 이동할 수 있으며, 더 나아가 language server protocol (LSP)의 모든 부분과 상호작용할 수 있어야 합니다.
-
실행 가능성: AI가 자신의 코드를 실행하고 그 결과를 확인할 수 있어야 합니다.
우리는 우선 LSP 사용성에 집중합니다.
이 목표들은 다음 요구 사항을 충족하는 선에서 달성되어야 합니다:
-
독립성: 사용자의 코딩 경험은 어떤 영향도 받아서는 안 됩니다.
-
프라이버시: 사용자의 코드는 (예: 전부 로컬에 두는 방식으로) 안전하게 보호되어야 합니다.
-
동시성: 여러 AI가 동시에 자신의 작업을 수행할 수 있어야 합니다.
-
보편성: 모든 언어와 모든 워크스페이스 설정에서 동작해야 합니다.
-
유지보수성: 가능한 한 적고, 서로 잘 분리된 코드로 작성되어야 합니다.
-
속도: 어디에서도 몇 분씩 지연이 발생해서는 안 되며, 수백 개의 AI 브랜치를 처리할 수 있을 만큼의 처리량이 확보되어야 합니다.
이 요구 사항들 상당수는 십만 명이 넘는 사용자를 위한 코드 에디터를 구축하는 현실을 반영합니다. 우리는 그 누구의 코딩 경험도 절대 저해하고 싶지 않습니다.
LSP 사용성 달성하기
AI가 자신의 코드 수정에 대해 린트 검사를 받도록 하는 것은, 기반이 되는 언어 모델이 고정된 상태에서 코드 생성 성능을 끌어올리는 가장 효과적인 방법 중 하나입니다. 린트는 동작하는 코드를 90% 수준에서 100% 수준으로 끌어올려 줄 뿐 아니라, AI가 첫 시도에 어떤 메서드나 서비스를 호출해야 할지 추론해야 하는, 컨텍스트가 제한된 상황에서도 매우 유용합니다. 린트는 AI가 어디에서 추가 정보를 요청해야 하는지 파악하는 데 도움을 줄 수 있습니다.

LSP 사용성을 확보하는 일은 실행 가능성을 확보하는 것보다도 더 단순합니다. 거의 모든 language server가 파일 시스템에 실제로 기록되지 않은 파일에도 동작할 수 있기 때문입니다(그리고 뒤에서 보겠지만, 파일 시스템을 개입시키면 일이 상당히 더 어려워집니다). 그러니 여기서부터 시작해 봅시다! 다섯 번째 요구사항인 유지보수성에 따라, 우리는 먼저 가능한 한 가장 단순한 해결책부터 시도했습니다.
통하지 않는 단순한 해결책들
Cursor는 VS Code를 포크한 것이기 때문에, 이미 언어 서버를 아주 쉽게 사용할 수 있습니다. VS Code에서는 열린 각 파일이 메모리에서 파일의 현재 상태를 저장하는 TextModel 객체로 표현됩니다. 언어 서버는 디스크가 아니라 이 TextModel 객체들에서 직접 읽어들이기 때문에, (파일을 저장할 때만이 아니라) 타이핑을 하는 동안에도 자동 완성과 린트 피드백을 제공할 수 있습니다.
AI가 lib.ts 파일에 수정을 가한다고 가정해 봅시다. 사용자가 동시에 이 파일을 편집하고 있을 수 있기 때문에, lib.ts에 대응하는 기존 TextModel 객체를 수정할 수는 없습니다. 그럼에도 그럴듯해 보이는 아이디어는 TextModel 객체의 사본을 만들고, 그 사본을 디스크 상의 어떤 실제 파일과도 연결되지 않게 분리한 다음, AI가 그 객체를 편집하고 그 객체에서 린트 결과를 받게 하는 것입니다. 이는 아래 6줄짜리 코드로 구현할 수 있습니다.
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// 복사된 인메모리 TextModel을 생성하고 AI 편집 내용을 적용합니다
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// 언어 서버가 새 TextModel 객체를 처리할 수 있도록 2초 대기합니다
await new Promise((resolve) => setTimeout(resolve, 2000));
// 마커 서비스에서 lint를 읽습니다. 마커 서비스는 내부적으로 언어에 따라 적절한 확장으로 라우팅합니다
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}이 방법은 유지 보수성 면에서 분명히 탁월합니다. 또한 대부분의 사용자가 이미 자신의 프로젝트에 맞는 올바른 언어별 확장 기능을 설치하고 설정해 두었기 때문에, 보편성 측면에서도 훌륭합니다. 동시성과 프라이버시는 아주 쉽게 만족됩니다.
문제는 독립성입니다. 복사본 TextModel을 만드는 것은 사용자가 편집 중인 파일을 직접 수정하지는 않는다는 뜻이지만, 여전히 사용자가 쓰고 있는 바로 그 언어 서버에게 우리가 복사한 파일의 존재를 알려 줍니다. 이로 인해 문제가 발생합니다. go-to-references 결과에 우리의 복사본 파일이 포함되고, 기본적으로 여러 파일에 걸친 기본 네임스페이스 스코프를 사용하는 Go 같은 언어에서는 복사본 파일과 사용자가 편집 중일 수 있는 원본 파일의 모든 함수에 대해 중복 선언 오류를 내보내며, Rust처럼 다른 곳에서 명시적으로 import된 경우에만 파일을 포함하는 언어의 경우에는 어떤 오류도 주지 않습니다. 이와 비슷한 문제가 분명히 더 많이 존재할 것입니다.
이 문제들이 사소해 보일 수도 있지만, 독립성은 우리에게 절대적으로 중요합니다. 일반적인 코드 편집 경험이 아주 조금이라도 나빠진다면, AI 기능이 아무리 좋아도 소용이 없습니다 — 저를 포함한 사용자들은 Cursor를 그냥 쓰지 않을 것입니다.
우리는 결국 실패로 끝난 몇 가지 다른 아이디어들도 검토했습니다. VS Code 인프라 바깥에서 자체적인 tsc나 gopls 또는 rust-analyzer 인스턴스를 띄우는 것, 모든 VS Code 확장 기능이 실행되는 extension host 프로세스를 복제해 각 언어 서버 확장 기능을 두 개씩 돌리는 것, 그리고 인기 있는 모든 언어 서버를 포크해 파일의 여러 버전을 지원하도록 만든 뒤 그러한 확장 기능들을 Cursor에 번들링하는 것 등이었습니다.
현재 섀도우 워크스페이스 구현
우리는 결국 섀도우 워크스페이스를 숨겨진 창으로 구현했습니다. AI가 자신이 작성한 코드에 대한 린트를 보고 싶어 할 때마다, 현재 워크스페이스에 대해 숨겨진 창을 하나 생성하고, 그 창에서 대신 수정을 수행한 뒤 린트를 다시 보고합니다. 이 숨겨진 창은 요청 간에 재사용합니다. 이렇게 하면 모든 요구 사항을 (거의*) 완전히 만족시키면서 (거의*) 완전한 LSP 사용성을 얻을 수 있습니다. *표시는 뒤에서 설명합니다.
그림 4는 단순화된 아키텍처 다이어그램을 보여줍니다.
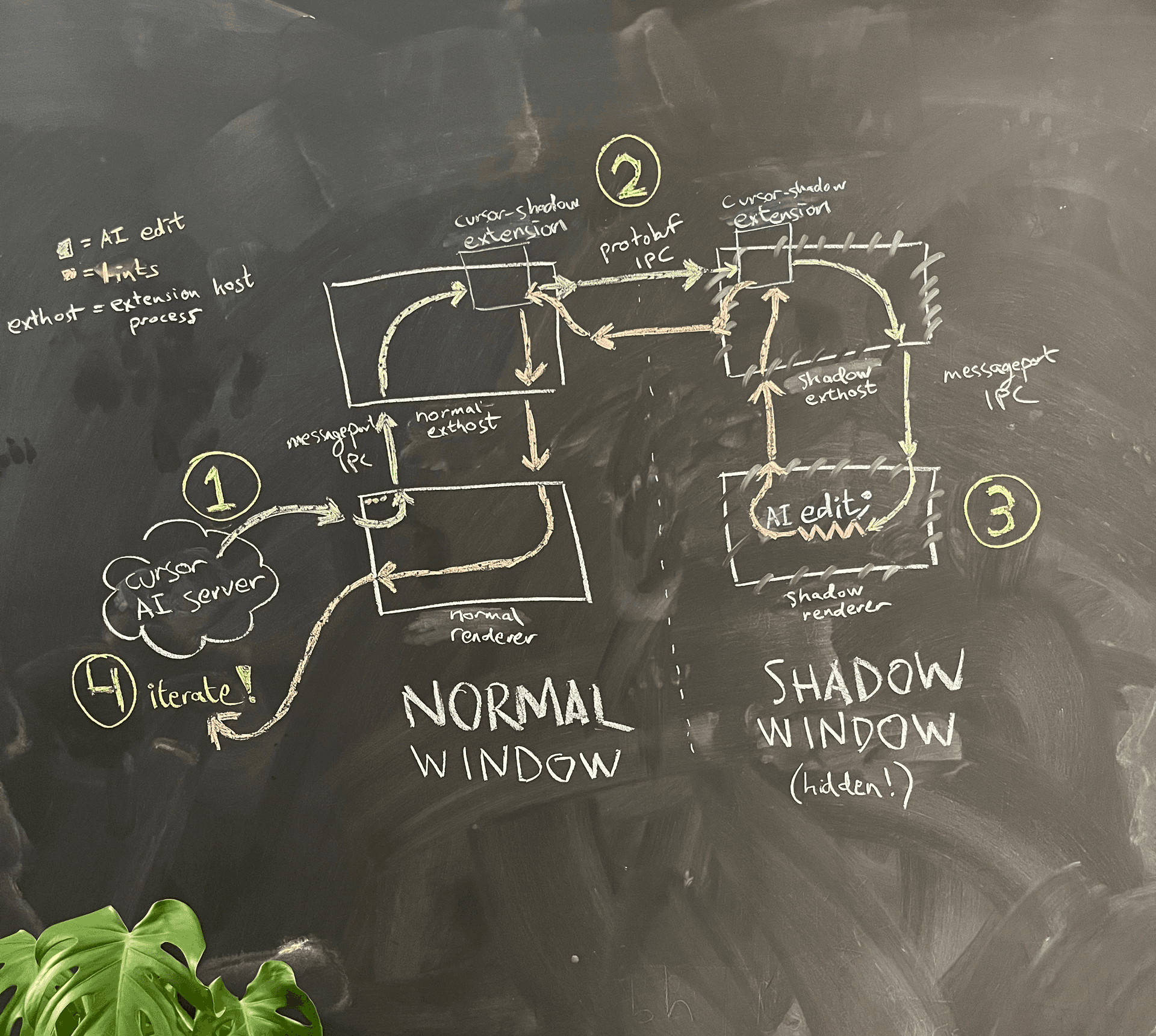
AI는 일반 창의 렌더러 프로세스에서 실행됩니다. 자신이 작성한 코드에 대한 린트를 보고 싶을 때, 렌더러 프로세스는 메인 프로세스에 동일한 폴더에 숨겨진 섀도우 창을 생성해 달라고 요청합니다.
Electron 샌드박싱 때문에 두 렌더러 프로세스는 서로 직접 통신할 수 없습니다. 우리가 고려했던 한 가지 옵션은, VS Code가 렌더러 프로세스와 extension host 프로세스 간 통신을 위해 구현해 둔 정교한 메시지 포트 생성 로직을 재사용하여, 일반 창과 섀도우 창 사이에 우리만의 메시지 포트 IPC를 만드는 것이었습니다. 하지만 유지 보수 부담이 걱정되어, 우리는 일종의 해킹을 택했습니다. 렌더러 프로세스에서 extension host로 가는 기존 메시지 포트 IPC를 재사용하고, extension host 간에는 별도의 IPC 연결을 사용해 통신합니다. 여기서 우리는 사용성 개선도 하나 슬쩍 넣었습니다. VS Code의 다소 취약한 커스텀 JSON 직렬화 로직 대신, 우리가 좋아하는 gRPC와 buf를 사용해 통신할 수 있게 된 것입니다.
이 구성은 추가된 코드가 다른 코드와 독립적이고, 창을 숨기기 위해 필요한 핵심 코드가 단 한 줄뿐이기 때문에, 자연스럽게 유지 보수성이 꽤 높은 구조가 됩니다(Electron에서 창을 열 때 show: false 파라미터를 전달하면 창을 숨길 수 있습니다). 보편성과 프라이버시는 아주 간단히 만족됩니다.
다행히 독립성도 충족됩니다! 새 창은 사용자와 완전히 독립적이므로, AI는 원하는 변경을 마음껏 수행하고 그에 대한 린트를 받아볼 수 있습니다. 사용자는 아무것도 눈치채지 못합니다.
섀도우 창에는 한 가지 우려가 있습니다. 새 창이 단순하게 메모리 사용량을 2배로 증가시킨다는 점입니다. 우리는 섀도우 창에서 실행될 수 있는 확장 기능을 제한하고, 비활성 상태가 15분 지속되면 자동으로 종료하며, 이 기능이 opt-in 방식이 되도록 해서 영향을 줄이고 있습니다. 그럼에도 불구하고, 이는 동시성 측면에서 도전 과제를 제기합니다. 각 AI마다 새로운 섀도우 창을 무작정 생성할 수는 없습니다. 다행히 여기서는 AI와 인간 사이의 핵심적인 차이점 중 하나를 활용할 수 있습니다. AI는 알아차리지도 못한 채 무기한 일시 정지가 가능합니다. 특히, 두 개의 AI A와 B가 각각 A1, A2와 B1, B2 순서로 수정을 제안한다고 할 때, 우리는 이 수정들을 교차로 섞어 적용할 수 있습니다. 섀도우 창은 먼저 전체 폴더 상태를 A1로 리셋하고, 린트를 얻은 뒤 A에게 반환합니다. 그다음 전체 폴더 상태를 B1으로 리셋하고, 린트를 얻어 B에게 반환합니다. 그리고 같은 방식으로 A2, B2에 대해 계속 진행합니다. 이런 의미에서 AI는 인간보다는 컴퓨터 프로세스에 더 가깝습니다(컴퓨터 프로세스도 CPU에 의해 이런 식으로 교차 실행되지만 이를 인지하지 못합니다). 인간은 고유한 시간 감각을 갖고 있기 때문입니다.
이 모든 것을 종합하면, 우리는 백그라운드 AI가 사용자에게 전혀 영향을 주지 않고 자신의 수정을 개선하는 데 사용할 수 있는 간단한 Protobuf API를 얻게 됩니다.
약속했던 별표 설명: 일부 언어 서버는 린트를 보고하기 전에 코드를 디스크에 저장해야만 합니다. 대표적인 예가 rust-analyzer 언어 서버인데, 이 서버는 VS Code 가상 파일 시스템과 통합되지 않고, 프로젝트 수준의 cargo check를 실행해 린트를 가져옵니다(참고용으로 이 이슈를 보세요). 따라서 사용자가 더 이상 권장되지 않는 RLS 확장을 사용하지 않는 한, 섀도우 워크스페이스에서는 아직 Rust에 대해 LSP를 제대로 활용할 수 없습니다.
실행 가능성 확보하기
실행 가능성을 확보하는 지점에서부터 일이 흥미로우면서도 복잡해집니다. 현재 Cursor에서는 짧은 시간 단위로 동작하는 AI에 집중하고 있습니다. 예를 들어 전체 PR을 한 번에 구현하기보다는, 여러분이 사용하는 동안 백그라운드에서 함수들을 구현해 주는 방식입니다. 그래서 아직 실행 가능성 자체는 구현하지 않았습니다. 그럼에도, 이를 어떻게 달성할 수 있을지 고민해 보는 일은 재미있습니다.
코드를 실행하려면 먼저 파일 시스템에 저장해야 합니다. 많은 프로젝트에는 디스크 기반 부수 효과(예: 빌드 캐시, 로그 파일)도 있습니다. 따라서 더 이상 사용자와 동일한 폴더에서 섀도우 창을 실행할 수는 없습니다. 모든 프로젝트에 대해 완전한 실행 가능성을 확보하려면 네트워크 수준의 격리도 필요하지만, 지금은 디스크 격리에 집중하겠습니다.
가장 단순한 아이디어: cp -r
가장 단순한 아이디어는 사용자의 폴더를 재귀적으로 /tmp 위치에 복사한 다음, 거기에 AI 수정을 적용하고 파일을 저장한 뒤 그곳에서 코드를 실행하는 것입니다. 이후 다른 AI가 다음 수정을 할 때는 rm -rf를 실행한 뒤 새로 cp -r을 호출해서 섀도우 워크스페이스가 사용자의 워크스페이스와 계속 동기화되도록 합니다.
문제는 속도입니다. cp -r은 정말 느립니다. 프로젝트를 실행 가능한 상태로 만들려면 소스 코드뿐 아니라 모든 빌드 관련 보조 파일도 복사해야 한다는 점을 기억해야 합니다. 구체적으로는 JavaScript 프로젝트에서는 node_modules, Python 프로젝트에서는 venv, Rust 프로젝트에서는 target을 복사해야 합니다. 이런 폴더들은 보통 중간 규모 프로젝트에서도 매우 크기 때문에, 이렇게 단순한 cp -r 방식은 사실상 한계에 부딪힙니다.
심링크, 하드링크, 카피온라이트
큰 폴더 구조를 복사하고 생성하는 작업이 꼭 아주 느릴 필요는 없습니다! 그 좋은 예가 bun인데, 캐시된 의존성을 node_modules에 설치하는 데 종종 1초 미만의 시간이 걸립니다. Linux에서는 실제 데이터 이동이 없기 때문에 빠른 하드링크를 사용합니다. macOS에서는 비교적 최근에 추가된 clonefile 시스템 콜을 사용하며, 이는 파일이나 폴더를 카피온라이트 방식으로 복사합니다.
안타깝게도, 우리 정도 규모의 중간 크기 모노레포의 경우, cp -c를 이용한 clonefile조차 완료하는 데 45초가 걸립니다. 이 속도로는 모든 섀도우 워크스페이스 요청 전에 실행하기엔 너무 느립니다. 하드링크는 섀도우 폴더에서 실행하는 어떤 것이든 실수로 원본 저장소의 실제 파일을 수정해 버릴 수 있어서 위험합니다. 심링크도 마찬가지고, 게다가 투명하게 처리되지 않는다는 추가적인 문제가 있어서, 종종 별도의 설정이 필요합니다(예: Node.js의 --preserve-symlinks 플래그).
조금 더 똑똑한 변경 내역 관리 방식과 결합한다면 clonefile(또는 그냥 cp -r)도 매 요청마다 폴더 전체를 다시 복사하지 않고 활용할 수 있을 것이라고 상상해볼 수 있습니다. 정확성을 보장하려면, 마지막 전체 복사 이후 사용자 폴더에서 일어난 모든 파일 변경과 복사된 폴더에서 일어난 모든 파일 변경을 추적해야 하고, 각 요청 전에 후자를 되돌린 뒤 전자를 재적용해야 합니다. 어느 한쪽의 변경 이력이 너무 커져서 추적하기 어려워지면, 새로운 전체 복사를 한 번 더 수행하고 상태를 리셋할 수 있습니다. 이 방식도 동작은 하겠지만, 버그를 만들기 쉽고, 깨지기 쉬우며, 솔직히 말해 겉보기에는 아주 단순해 보이는 일을 위해 쓰기에는 꽤나 우아하지 못한 해결책처럼 느껴집니다.
우리가 진짜로 원하는 것: 커널 수준의 폴더 프록시
우리가 진짜로 원하는 것은 간단합니다. 일반 파일 시스템 API를 사용하는 모든 애플리케이션 입장에서, 그림자 폴더 A′가 사용자의 폴더 A와 완전히 동일하게 보이되, 그 안의 일부 파일을 빠르게 설정 가능한 “오버라이드 파일” 집합으로 지정해서, 해당 파일의 내용은 디스크가 아니라 메모리에서 읽히도록 하고 싶습니다. 또한 폴더 A′에 대한 모든 쓰기 작업은 디스크가 아니라 메모리 상의 오버라이드 저장소에 기록되기를 원합니다. 요약하면, 설정 가능한 오버라이드를 가진 프록시 폴더가 필요하고, 이 오버라이드 테이블은 전적으로 메모리에만 존재해도 괜찮습니다. 그러면 이 프록시 폴더 안에 우리의 그림자 창을 띄워서, 디스크 수준에서 완전한 독립성을 달성할 수 있습니다.
핵심은, 실행 중인 코드가 아무 변경 없이 계속해서 read 및 write 시스템 콜을 사용할 수 있도록, 폴더 프록시에 대해 커널 수준의 지원이 필요하다는 점입니다. 한 가지 방법은 커널의 가상 파일 시스템에서 그림자 폴더의 백엔드로 자신을 등록하는 커널 확장 13을 만들어, 위에서 설명한 단순한 동작을 구현하는 것입니다.
Linux에서는 대신 FUSE (“Filesystem in Userspace”)를 사용해 사용자 수준에서 이 작업을 수행할 수 있습니다. FUSE는 대부분의 Linux 배포판에 기본으로 포함되어 있는 커널 모듈로, 파일 시스템 호출을 사용자 수준 프로세스로 프록시합니다. 덕분에 폴더 프록시를 구현하는 작업이 훨씬 더 단순해집니다. C++로 구현한 폴더 프록시의 간단한 예시는 다음과 같을 수 있습니다.
먼저, FUSE 커널 모듈과 통신을 담당하는 사용자 수준 FUSE 라이브러리를 가져옵니다. 그리고 대상 폴더(사용자의 폴더)와, 오버라이드 정보를 담는 메모리 상의 맵을 정의합니다.
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// 기타 include...
using namespace std;
// 수정하지 않을 프록시 폴더
string target_folder = "/path/to/target/folder";
// 적용할 인메모리 오버라이드
unordered_map<string, vector<char>> overrides;그다음, overrides에 해당 경로가 포함되어 있는지 확인하는 커스텀 read 함수를 정의하고, 없다면 타깃 폴더에서 그대로 읽어 옵니다.
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 경로가 오버라이드에 있는지 확인
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// 있다면, 오버라이드의 내용을 반환
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// 없다면, 프록시된 폴더에서 파일을 열고 읽기
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}우리의 커스텀 write 함수는 단순히 overrides 맵에 써 넣기만 합니다.
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 항상 오버라이드에 씁니다
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}마지막으로, 우리가 정의한 사용자 정의 함수들을 FUSE에 등록합니다.
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}실제 구현에서는 readdir, getattr, lock 등을 포함해 전체 FUSE API를 구현해야 하지만, 각 함수는 위에서 살펴본 것들과 매우 비슷하게 작성될 것입니다. 새로운 lint 요청이 들어올 때마다 해당 AI의 수정 사항만 남기도록 overrides 맵을 그 요청에 해당하는 내용으로만 리셋하면 되며, 이 작업은 즉시 끝납니다. 메모리 사용량 급증을 확실히 방지하고 싶다면, 약간의 추가 관리 작업을 통해 overrides 맵을 디스크에 저장해 둘 수도 있습니다.
환경을 완전히 통제할 수 있다면, FUSE로 인해 발생하는 추가적인 사용자-커널 컨텍스트 스위칭 오버헤드를 피하기 위해 이를 네이티브 커널 모듈로 구현하는 편이 더 바람직할 것입니다. 14
...하지만: 폐쇄적 생태계
Linux에서는 FUSE 폴더 프록시가 아주 잘 작동하지만, 대부분의 사용자는 macOS나 Windows를 쓰고 있고, 둘 다 내장된 FUSE 구현이 없습니다. 불행히도 커널 확장을 함께 배포하는 것 역시 불가능합니다. Apple Silicon이 탑재된 Mac에서는 사용자가 커널 확장을 설치하려면 특수 키를 누른 상태로 컴퓨터를 재부팅해 복구 모드에 진입한 다음, “보안 수준 낮춤(Reduced Security)”으로 설정을 낮춰야 합니다. 이건 사실상 배포 불가 조건입니다!
FUSE는 일부가 커널 내부에서 실행되어야 하기 때문에, macFUSE 같은 서드파티 FUSE 구현도 똑같이 “사용자에게 설치를 시킬 수가 없는” 문제를 겪습니다.
이 제한을 우회하기 위해 여러 가지 창의적인 시도가 있었습니다. 한 가지 접근은 macOS가 기본적으로 지원하는 네트워크 기반 파일 시스템(예: NFS 또는 SMB)를 사용하고, 그 아래에 FUSE API를 까는 방식입니다. NFS 위에 FUSE 유사 API를 올린 오픈 소스 PoC 로컬 서버는 xetdata/nfsserve에 호스팅되어 있고, 클로즈드 소스 프로젝트인 macOS-FUSE-t는 NFS와 SMB 둘 다를 기반으로 한 백엔드를 지원합니다.
문제가 해결됐냐고요? 전혀요... 파일 시스템은 파일을 읽고, 쓰고, 나열하는 것보다 훨씬 더 복잡합니다! 여기서는 xetdata/nfsserve 구현이 기반으로 삼고 있는 예전 버전의 NFS가 파일 잠금(file locking)을 지원하지 않기 때문에 Cargo가 실패하고 있습니다.

macOS-FUSE-t는 파일 잠금을 지원하는 NFSv4 위에 구축되어 있지만, GitHub 저장소에는 소스 코드가 아닌 세 개의 파일(Attributions.txt, License.txt, README.md)만 들어 있고, 추가 정보가 전혀 없는 macos-fuse-t라는 수상할 정도로 단일 목적의 GitHub 계정이 만들었습니다. 이런 임의의 바이너리를 사용자에게 배포할 수는 없겠죠... 오픈 이슈들을 보면 Apple 커널 버그와 관련된, NFS/SMB 기반 접근법의 더 근본적인 문제들도 드러납니다.
그럼 우리에게 남은 건 무엇일까요? 완전히 새로운 창의적 접근, 15 또는... 정치입니다! Apple은 수년 동안 커널 확장을 단계적으로 폐지해 오면서 DriverKit 같은 더 많은 사용자 수준 API를 개방해 왔고, 기존 파일 시스템에 대한 내장 지원도 최근에는 user-land로 전환되었습니다. 그들의 오픈 소스 MS-DOS 코드에는 FSKit이라는 비공개 프레임워크가 여기에 참조되어 있고, 꽤 유망해 보입니다! 약간의 정치적인(?) 설득이 더해지면 Apple이 FSKit을 외부 개발자에게 최종 공개·배포하도록 만들 수 있을 것 같은 느낌이 듭니다(아니면 이미 그렇게 할 계획인지도 모르죠). 그렇게 된다면 macOS에서도 실행 가능성 문제를 해결할 수 있는 해법이 될 수 있습니다.
남아 있는 질문들
지금까지 살펴본 것처럼, 겉보기에 단순해 보이는 “AI가 백그라운드에서 코드를 반복적으로 수정하게 하는” 문제는 실제로는 꽤 복잡합니다. shadow workspace는 AI에게 lint 결과를 보여 줘야 한다는 즉각적인 필요를 해결하기 위해, 1주일 동안 1명이 구현한 프로젝트였습니다. 앞으로는 이를 확장해서 실행 가능성(runnability) 문제까지 해결하려고 합니다. 아직 열려 있는 질문들은 다음과 같습니다:
-
우리가 생각하고 있는 단순한 프록시 폴더를 kernel extension을 만들거나 FUSE API를 사용하지 않고 구현할 다른 방법이 있을까요? FUSE는 (어떤 종류의 파일 시스템이든) 다루려는 더 큰 문제를 해결하려 하기 때문에, 일반적인 FUSE 구현에는 맞지 않지만 우리 프록시 폴더에는 맞을 수도 있는, macOS나 Windows의 잘 알려지지 않은 API들이 있을 법하다는 느낌이 듭니다.
-
Windows에서 프록시 폴더에 대한 구체적인 그림은 어떻게 될까요? WinFsp 같은 것을 그냥 쓰면 될까요, 아니면 설치나 성능, 보안 측면에서 문제가 있을까요? 저는 대부분의 시간을 macOS에서 폴더 프록시를 어떻게 구현할지 조사하는 데 썼습니다.
-
macOS에서 DriverKit을 사용해 가짜 USB 장치를 시뮬레이션하고, 이를 프록시 폴더처럼 동작하도록 만들 방법이 있을까요? 아마 어렵겠지만, API를 충분히 자세히 살펴보지 않아 완전히 불가능하다고 자신 있게 말할 수준은 아닙니다.
-
네트워크 수준의 독립성을 어떻게 달성할 수 있을까요? 특히 고려해야 할 상황 하나는, AI가 세 개의 마이크로서비스로 나뉘어 있는 코드를 대상으로 통합 테스트를 디버깅하고자 할 때입니다. 전체 환경 설정과 설치된 모든 소프트웨어에 대해 동등성을 보장해야 하므로, 더 많은 작업이 필요하겠지만 VM에 더 가까운 접근법이 필요할 수도 있습니다.
-
사용자의 로컬 workspace에서, 사용자에게 최대한 적은 설정만 요구하면서 동일한 remote workspace를 만드는 방법이 있을까요? 클라우드에서는 별다른 제약 없이 FUSE를 바로 쓸 수 있고(또는 성능상의 이유로 원한다면 kernel module도 사용할 수 있으며), 조직 내 “정치(politics)” 문제도 없을 것이고, 사용자 측에서 추가 메모리를 사용하지 않으면서 완전한 독립성도 보장할 수 있습니다. 프라이버시에 덜 민감한 사용자에게는 좋은 대안이 될 수 있습니다. 초기 아이디어로는, 시스템을 관찰해 어떤 것이 돌아가고 있는지 스크립트로 탐지하고, 언어 모델을 이용해 Dockerfile을 생성하는 방식으로 자동 추론된 docker container를 만드는 방법이 있습니다.
이 질문들에 대해 좋은 아이디어가 있다면 arvid@cursor.com으로 이메일을 보내 주세요. 또한, 이런 작업에 관심이 있다면 we’re hiring.