Composer 2 の技術レポート

エージェント型ソフトウェア開発向けのコーディングモデルである Composer 2 の学習に関する技術レポートを、arXiv に投稿 しました。 このレポートでは、オープンなベースモデルである Kimi K2.5 に対する継続事前学習から大規模な強化学習まで、実際の Cursor 環境をできる限り忠実に再現することを重視した学習プロセス全体を取り上げています。
継続事前学習とRL
Composer 2 は、2段階で学習されます。まず、コードを重視したデータ構成による継続事前学習でベースモデルのコーディング知識を深め、その後、大規模な強化学習によってエンドツーエンドのエージェント性能を向上させます。事前学習の損失を下げると下流のRL性能も向上し、より優れたベース知識が安定してより優れたエージェントにつながることがわかりました。
Composer 2 のRL学習は、実運用モデルが使うのと同じツールやハーネスを用いた、現実に即した Cursor セッション内で行われます。対象とする課題分布は、開発者が Composer に依頼する内容の全体像を反映したものです。RL学習によって平均パフォーマンスと best-of-K パフォーマンスの両方が向上しており、これはモデルが既知の解法に集中しているだけでなく、新たな解法の経路を学習していることを示唆しています。
CursorBench による実環境での評価
コーディングモデルを構築するうえでの大きな課題のひとつは、公開ベンチマークでは開発者の実際の作業が反映されていないことが多い点です。タスクは過度に詳細化され、解法の幅は狭く、コードベースも小規模です。
私たちは、社内のエンジニアリングチームによる実際のコーディングセッションをもとに CursorBench を構築しました。ここには、プロンプトが短く曖昧で、多数のファイルにまたがる数百行規模の変更が必要になるタスクが含まれています。モデルを実際の課題に即したものに保つため、CursorBench は学習から評価まで一貫して活用しています。
パフォーマンス
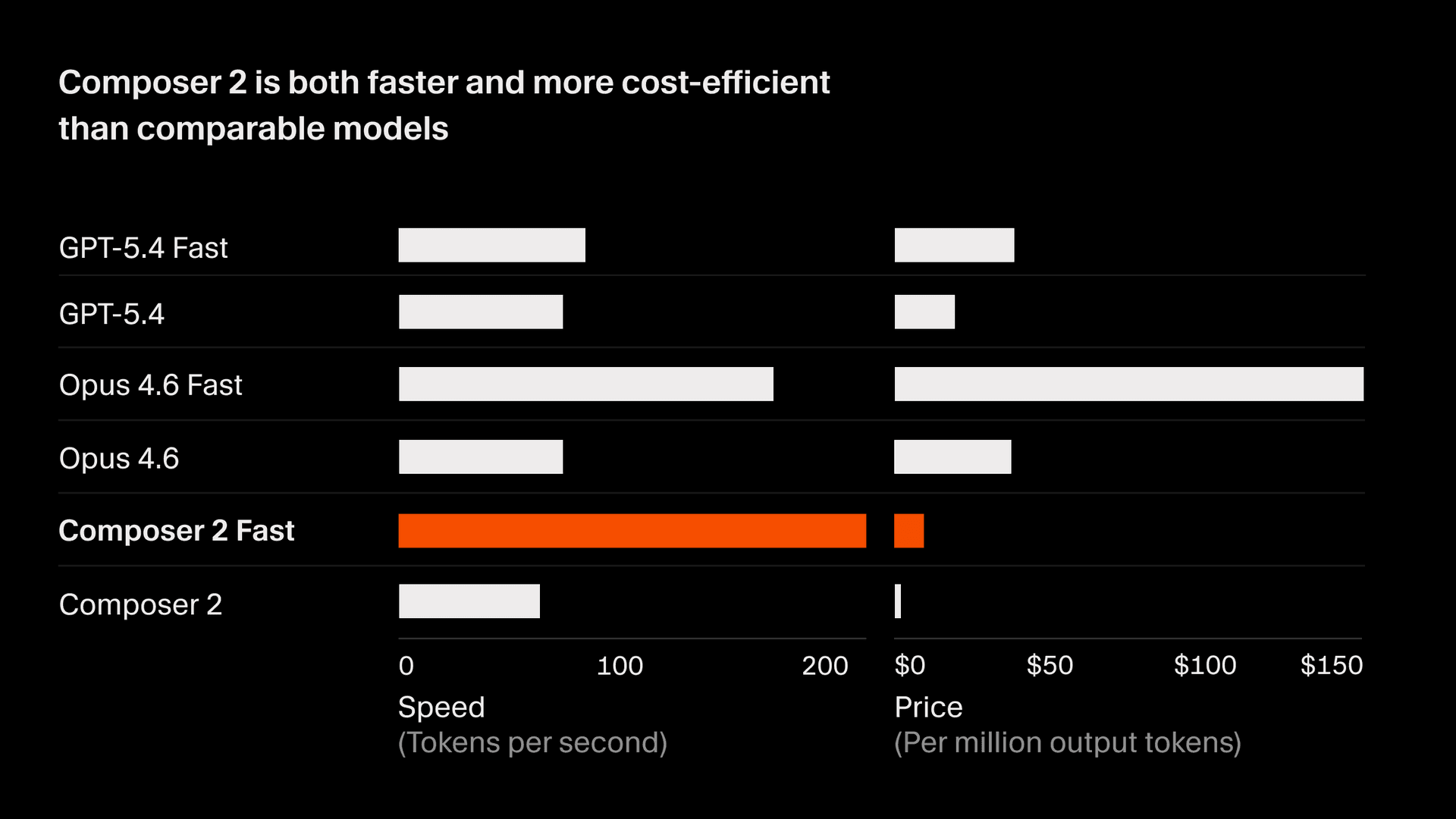
CursorBench では、Composer 2 は 61.3 を記録し、Composer 1.5 から 37% 改善しており、最先端のフロンティアモデルにも匹敵する水準です。公開ベンチマークでは、Composer 2 は SWE-bench Multilingual で 73.7、Terminal-Bench で 61.7 を記録しています。しかも、同クラスのモデルと比べて推論コストを大幅に抑えており、対話型の開発ワークフローにおいて、精度とコストの面でパレート最適なトレードオフを実現しています。



インフラストラクチャ
Composer 2 の学習には、大規模なインフラストラクチャ開発が必要でした。具体的には、Blackwell GPU 上で MoE を効率的に学習させるためのカスタム低精度カーネル、複数地域にまたがる完全非同期の RL パイプライン、そして数十万ものサンドボックス化されたコーディング環境を実行するための社内計算プラットフォーム Anyrun です。レポートでは、重みの同期、耐障害性、環境の再現性に対する私たちのアプローチを含め、スタック全体を取り上げています。
このレポートではさらに、学習レシピに関するアブレーション、エージェントの挙動形成に対する私たちのアプローチ、評価スイートのデザインなどについても詳しく説明しています。
Kimi K2.5、Ray、ThunderKittens、PyTorch、そして幅広いオープンソースコミュニティを支えるチームの皆様に感謝します。あわせて、協業とパートナーシップに感謝を込めて、Fireworks と Colfax にもお礼を申し上げます。
技術レポート全文はこちらをご覧ください。