Itérer avec des espaces de travail fantômes
Voici une recette pour l’échec : collez quelques fichiers pertinents dans un Google Doc, envoyez le lien à votre ingénieur logiciel p60 préféré qui ne connaît rien à votre codebase, et demandez‑lui d’implémenter entièrement et correctement votre prochain PR dans le document.
Demandez à une IA de faire la même chose et elle échouera elle aussi, sans surprise.
Maintenant, donnez‑leur plutôt un accès distant à votre environnement de développement, avec la capacité de voir les lints, d’aller aux définitions et d’exécuter du code, et vous pouvez commencer à espérer qu’ils puissent être un tant soit peu utiles.
Nous pensons que l’une des choses qui permettront aux IA d’écrire une plus grande partie de votre code est la capacité d’itérer dans votre environnement de développement. Mais laisser naïvement les IA se promener librement dans votre dossier conduit au chaos : imaginez avoir écrit une fonction demandant un raisonnement poussé pour qu’une IA la réécrive, ou essayer d’exécuter votre programme pour qu’une IA y insère du code qui ne compile pas. Pour être réellement utile, l’itération de l’IA doit se produire en arrière‑plan, sans affecter votre expérience de codage.
Pour y parvenir, nous avons implémenté ce que nous appelons l’espace de travail fantôme dans Cursor. Dans cet article, je vais d’abord présenter nos critères de conception, puis décrire l’implémentation actuellement présente dans Cursor au moment où j’écris ces lignes (une fenêtre Electron cachée) et la direction que nous souhaitons prendre à l’avenir (un proxy de dossier au niveau du noyau).

Critères de conception
Nous voulons que l’espace de travail fantôme atteigne les objectifs suivants :
-
Utilisabilité du LSP : les IA doivent voir les lints issus de leurs modifications, pouvoir accéder aux définitions et, plus généralement, être en mesure d’interagir avec toutes les parties du language server protocol (LSP).
-
Exécutabilité : les IA doivent pouvoir exécuter leur code et voir le résultat.
Nous nous concentrons d’abord sur l’utilisabilité du LSP.
Les objectifs doivent être atteints tout en respectant les exigences suivantes :
-
Indépendance : l’expérience de développement de l’utilisateur ne doit pas être affectée.
-
Confidentialité : le code de l’utilisateur doit être en sécurité (par exemple, en restant entièrement local).
-
Concurrence : plusieurs IA doivent pouvoir effectuer leur travail en parallèle.
-
Universalité : cela doit fonctionner pour tous les langages et toutes les configurations d’espace de travail.
-
Maintenabilité : cela doit être écrit avec le moins de code possible et de la manière la plus isolée possible.
-
Rapidité : il ne doit y avoir aucun délai de plusieurs minutes, et il doit y avoir suffisamment de débit pour gérer des centaines de branches d’IA.
Beaucoup de ces points reflètent la réalité de créer un éditeur de code pour plus de cent mille utilisateurs. Nous voulons vraiment éviter de nuire à l’expérience de développement de qui que ce soit.
Atteindre l’utilisabilité LSP
Permettre aux IA d’obtenir des lints pour leurs modifications est l’un des moyens les plus efficaces d’améliorer les performances de génération de code tout en gardant le modèle de langage sous-jacent constant. Non seulement les lints permettent de passer de 90 % de code fonctionnel à 100 % de code fonctionnel, mais ils sont aussi très utiles dans les situations où le contexte est limité, lorsque l’IA doit faire une hypothèse éclairée sur la méthode ou le service à appeler dès le premier essai. Les lints peuvent aider à identifier les endroits où l’IA doit demander plus d’informations.

L’utilisabilité LSP est aussi plus simple que l’exécutabilité, car presque tous les language servers peuvent opérer sur des fichiers qui ne sont pas enregistrés sur le système de fichiers (et comme nous le verrons plus tard, impliquer le système de fichiers rend les choses nettement plus difficiles). Commençons donc par là ! Dans l’esprit de notre cinquième exigence, la maintenabilité, nous avons d’abord essayé les solutions les plus simples possible.
Les solutions simples qui ne fonctionnent pas
Le fait que Cursor soit un fork de VS Code signifie que nous avons déjà un accès très simple aux language servers. Dans VS Code, chaque fichier ouvert est représenté par un objet TextModel, qui stocke l’état actuel du fichier en mémoire. Les language servers lisent à partir de ces objets TextModel plutôt qu’à partir du disque, ce qui leur permet de vous proposer des complétions et des lints au fur et à mesure que vous tapez (et pas seulement lorsque vous enregistrez).
Supposons qu’une IA effectue une modification dans le fichier lib.ts. Nous ne pouvons évidemment pas modifier l’objet TextModel existant correspondant à lib.ts, car l’utilisateur peut être en train de l’éditer en même temps. Néanmoins, une idée qui semble raisonnable est de créer une copie de l’objet TextModel, de détacher cette copie de tout fichier réel sur le disque, et de laisser l’IA modifier cet objet et y exécuter des lints. Cela pourrait être réalisé avec les 6 lignes de code suivantes.
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// créer le TextModel copié en mémoire et lui appliquer la modification de l'IA
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// attendre 2 secondes pour permettre aux serveurs de langage de traiter le nouvel objet TextModel
await new Promise((resolve) => setTimeout(resolve, 2000));
// lire les lints depuis le service de marqueurs, qui redirige en interne vers la bonne extension selon le langage
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}Cette solution est clairement excellente en termes de maintenabilité. Elle est également très bonne en termes d’universalité, car la plupart des utilisateurs auront déjà installé et configuré les bonnes extensions spécifiques à leur langage pour leur projet. La concurrence et la confidentialité sont trivialement satisfaites.
Le problème, c’est l’indépendance. Même si créer une copie de TextModel signifie que nous ne modifions pas directement le fichier que l’utilisateur est en train d’éditer, nous informons malgré tout le serveur de langage, le même serveur de langage que celui utilisé par l’utilisateur, de l’existence de notre fichier copié. Cela pose des problèmes : les résultats de « go-to-references » incluront notre fichier copié, les langages comme Go, qui ont un espace de noms par défaut multi‑fichiers, se plaindront de déclarations dupliquées pour toutes les fonctions à la fois dans le fichier copié et dans le fichier original que l’utilisateur est peut‑être en train d’éditer, et les langages comme Rust, où les fichiers ne sont inclus que s’ils sont explicitement importés ailleurs, ne vous donneront aucune erreur du tout. Il est probable qu’il existe encore beaucoup d’autres problèmes de ce genre.
Vous pourriez penser que ces problèmes semblent mineurs, mais l’indépendance est absolument critique pour nous. Si nous dégradons ne serait‑ce que légèrement l’expérience normale d’édition de code, la qualité de nos fonctionnalités d’IA n’aura aucune importance — les gens, moi y compris, n’utiliseraient tout simplement pas Cursor.
Nous avons également envisagé quelques autres idées qui se sont finalement révélées vouées à l’échec : lancer nos propres instances de tsc, gopls ou rust-analyzer en dehors de l’infrastructure de VS Code, dupliquer le processus d’hébergement des extensions où toutes les extensions VS Code sont exécutées afin de pouvoir lancer deux copies de chaque extension de serveur de langage, et forker tous les serveurs de langage populaires pour prendre en charge plusieurs versions différentes de fichiers, puis intégrer ces extensions dans Cursor.
L’implémentation actuelle du shadow workspace
Nous avons fini par implémenter le shadow workspace comme une fenêtre cachée : chaque fois qu’une IA veut voir les lints pour le code qu’elle a écrit, nous lançons une fenêtre cachée pour l’espace de travail actuel, puis nous effectuons la modification dans cette fenêtre à la place, en renvoyant ensuite les lints. Nous réutilisons la fenêtre cachée entre les requêtes. Cela nous donne une utilisabilité LSP (presque*) complète tout en satisfaisant (presque*) entièrement toutes les exigences. Les astérisques sont traités plus loin.
Un diagramme d’architecture simplifié est présenté à la figure 4.
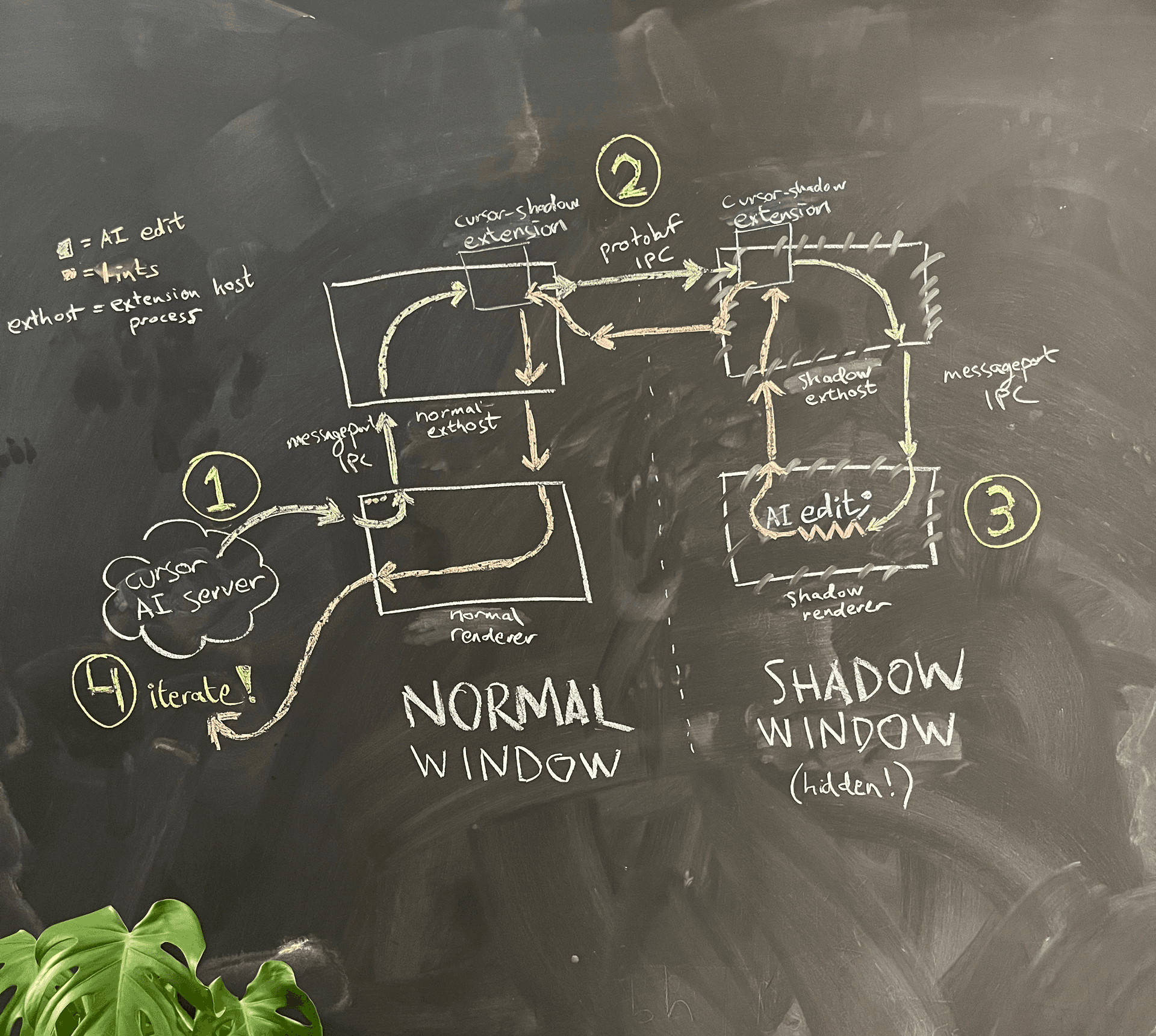
L’IA s’exécute dans le process renderer de la fenêtre normale. Quand elle veut voir les lints pour le code qu’elle a écrit, le process renderer demande au process principal de lancer une fenêtre shadow cachée dans le même dossier.
À cause du sandboxing d’Electron, les deux processes renderer ne peuvent pas communiquer directement entre eux. L’une des options envisagées était de réutiliser la logique soigneuse de création de message port que VS Code a implémentée pour permettre au process renderer de communiquer avec le process extension host, et de l’utiliser pour créer notre propre IPC via message port entre la fenêtre normale et la fenêtre shadow. Inquiets de la charge de maintenance, nous avons opté pour un hack : nous réutilisons l’IPC existant via message port entre le process renderer et l’extension host, puis nous communiquons d’extension host à extension host en utilisant une connexion IPC indépendante. Nous en avons aussi profité pour glisser une amélioration de confort : nous pouvions maintenant utiliser gRPC et buf (que nous adorons) pour communiquer, au lieu de la logique de sérialisation JSON personnalisée et quelque peu fragile de VS Code.
Cette configuration est d’emblée assez facile à maintenir, puisque le code ajouté est indépendant du reste, et que le code central requis pour cacher la fenêtre se résume à une seule ligne (lors de l’ouverture d’une fenêtre dans Electron, on peut fournir un paramètre show: false pour la cacher). Elle satisfait trivialement l’universalité et la confidentialité.
Heureusement, l’indépendance est également satisfaite ! La nouvelle fenêtre est complètement indépendante de l’utilisateur, donc les IA peuvent librement effectuer toutes les modifications qu’elles souhaitent et obtenir les lints correspondants. L’utilisateur ne remarquera rien.
Il y a toutefois un problème avec la fenêtre shadow : la nouvelle fenêtre entraîne naïvement un doublement de l’utilisation de la mémoire. Nous réduisons l’impact en limitant les extensions autorisées à s’exécuter dans la fenêtre shadow, en la supprimant automatiquement après 15 minutes d’inactivité, et en veillant à ce qu’elle soit activée en option (opt-in). Cela reste néanmoins un défi pour la concurrence : nous ne pouvons pas simplement lancer une nouvelle fenêtre shadow pour chaque IA. Heureusement, nous pouvons ici tirer parti d’un des principaux facteurs distinctifs entre les IA et les humains : les IA peuvent être mises en pause pendant une durée indéfinie sans même s’en rendre compte. En particulier, si vous avez deux IA, A et B, proposant respectivement les modifications A1 puis A2 et B1 puis B2, vous pouvez intercaler ces modifications. La fenêtre shadow réinitialise d’abord l’état de tout le dossier à A1, obtient les lints et les renvoie à A. Puis elle réinitialise l’état de tout le dossier à B1, obtient les lints et les renvoie à B. Et ainsi de suite avec A2 et B2. En ce sens, les IA ressemblent davantage à des processus informatiques (qui sont eux aussi entrelacés de cette manière par le CPU sans s’en apercevoir) qu’à des humains (qui ont un sens intrinsèque du temps).
En combinant tout cela, nous obtenons une API Protobuf simple que nos IA en arrière-plan peuvent utiliser pour affiner leurs modifications, sans affecter l’utilisateur d’aucune façon.
Les astérisques annoncés : certains serveurs de langage s’appuient sur le fait que le code soit enregistré sur le disque avant de signaler les lints. L’exemple principal est le serveur de langage rust-analyzer, qui exécute simplement un cargo check au niveau du projet pour obtenir les lints, et ne s’intègre pas avec le système de fichiers virtuel de VS Code (voir ce ticket pour référence). Ainsi, l’espace de travail fantôme ne prend pas encore en charge une utilisation LSP satisfaisante pour Rust, à moins que l’utilisateur n’utilise l’extension obsolète RLS.
Rendre le code exécutable
L’exécutabilité est le point où les choses deviennent à la fois intéressantes et complexes. Nous nous concentrons actuellement sur des IA à court terme pour Cursor — par exemple, implémenter des fonctions pour vous en tâche de fond pendant que vous les utilisez, plutôt que de prendre en charge des PR complètes — ; nous n’avons donc pas encore mis en œuvre cette exécutabilité. Néanmoins, réfléchir à la manière de l’atteindre reste intéressant.
Exécuter du code nécessite de l’enregistrer au préalable sur le système de fichiers. De nombreux projets auront également des effets secondaires sur le disque (pensez aux caches de build et aux fichiers de log). Par conséquent, nous ne pouvons plus lancer la fenêtre fantôme dans le même dossier que l’utilisateur. Pour une exécutabilité parfaite de tous les projets, nous avons aussi besoin d’une isolation au niveau du réseau, mais pour l’instant nous nous concentrons sur l’obtention d’une isolation au niveau du disque.
L’idée la plus simple : cp -r
L’idée la plus simple consiste à copier récursivement le dossier de l’utilisateur vers un emplacement /tmp, puis à appliquer les modifications de l’IA, enregistrer les fichiers et exécuter le code à cet endroit. Pour la modification suivante par une autre IA, nous ferions un rm -rf suivi d’un nouvel appel à cp -r, afin de garantir que l’espace de travail miroir reste synchronisé avec l’espace de travail de l’utilisateur.
Le problème, c’est la vitesse : cp -r est vraiment lent. Il faut garder en tête que, pour pouvoir exécuter un projet, nous devons non seulement copier le code source, mais aussi tous les fichiers associés au build. Concrètement, nous devons copier les node_modules dans les projets JavaScript, le venv dans les projets Python et le target dans les projets Rust. Ce sont généralement d’énormes dossiers, même pour des projets de taille moyenne, ce qui met fin à l’approche naïve cp -r.
Liens symboliques, liens physiques, copie sur écriture
Copier et créer de grandes structures de dossiers n’a pas besoin d’être extrêmement lent ! Un bon exemple est bun, qui met souvent moins d’une seconde à installer des dépendances mises en cache dans node_modules. Sous Linux, ils utilisent des liens physiques, ce qui est rapide car il n’y a aucun déplacement réel de données. Sous macOS, ils utilisent l’appel système clonefile, une addition relativement récente qui effectue une copie sur écriture (copy-on-write) d’un fichier ou d’un dossier.
Malheureusement, pour notre monorepo de taille moyenne, même un clonefile cp -c met 45 secondes à se terminer. C’est beaucoup trop lent pour être exécuté avant chaque requête de shadow workspace. Les liens physiques sont risqués, parce que tout ce que vous exécutez dans le dossier shadow peut accidentellement modifier les vrais fichiers dans le dépôt original. Les liens symboliques posent un problème similaire, et ont en plus le défaut de ne pas être traités de manière transparente, ce qui signifie qu’ils nécessitent souvent une configuration supplémentaire (par exemple le flag --preserve-symlinks de Node.js).
On pourrait imaginer qu’un clonefile (ou même un simple cp -r) fonctionne s’il est couplé à un mécanisme de suivi astucieux pour éviter d’avoir à recopier le dossier avant chaque requête. Pour garantir la correction, nous devrions surveiller tous les changements de fichiers dans le dossier de l’utilisateur depuis la dernière copie complète, ainsi que tous les changements de fichiers dans le dossier copié, et, avant chaque requête, annuler les seconds et rejouer les premiers. Chaque fois que l’historique des changements d’un côté ou de l’autre devient trop gros pour être suivi, nous pourrions faire une nouvelle copie complète et réinitialiser l’état. Cela pourrait fonctionner, mais cela semble sujet aux bogues, fragile et, franchement, un peu bancal pour atteindre quelque chose qui paraît si simple.
Ce que nous voulons vraiment : un proxy de dossier au niveau du noyau
Ce que nous voulons vraiment est simple : nous voulons qu’un dossier fantôme A′ apparaisse identique au dossier A de l’utilisateur pour toutes les applications qui utilisent les API classiques du système de fichiers, avec la possibilité de configurer rapidement un petit ensemble de fichiers de remplacement dont le contenu est lu depuis la mémoire à la place. Nous voulons également que toute écriture dans le dossier A′ soit enregistrée dans le magasin de remplacements en mémoire plutôt que sur le disque. En résumé, nous voulons un dossier proxy avec des remplacements configurables, et nous sommes prêts à conserver entièrement en mémoire la table de remplacements. Nous pouvons ensuite lancer notre fenêtre fantôme à l’intérieur de ce dossier proxy et obtenir une indépendance parfaite par rapport au disque.
Point crucial : nous avons besoin d’une prise en charge au niveau du noyau pour ce proxy de dossier, afin que n’importe quel code en cours d’exécution puisse continuer à appeler les appels système read et write sans aucune modification. Une approche consiste à créer une extension de noyau 13 qui s’enregistre comme backend pour le dossier fantôme dans le système de fichiers virtuel du noyau, et implémente le comportement simple décrit ci‑dessus.
Sous Linux, nous pouvons faire cela au niveau utilisateur à la place, avec FUSE (« Filesystem in Userspace »). FUSE est un module du noyau déjà présent par défaut dans la plupart des distributions Linux, qui redirige les appels au système de fichiers vers un processus en espace utilisateur. Cela rend l’implémentation du dossier proxy encore plus simple. Une implémentation jouet du dossier proxy pourrait ressembler à ce qui suit, ici présentée en C++.
Tout d’abord, nous importons la bibliothèque FUSE en espace utilisateur, qui est responsable de la communication avec le module FUSE du noyau. Nous définissons également le dossier cible (le dossier de l’utilisateur) et la table en mémoire des remplacements.
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// autres inclusions...
using namespace std;
// le dossier proxifié que nous ne voulons pas modifier
string target_folder = "/path/to/target/folder";
// les substitutions en mémoire à appliquer
unordered_map<string, vector<char>> overrides;Ensuite, nous définissons une fonction personnalisée read pour vérifier si les overrides contiennent le chemin, et, si ce n’est pas le cas, lire simplement dans le dossier cible.
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// vérifier si le chemin est dans les substitutions
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// si c'est le cas, retourner le contenu de la substitution
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// sinon, ouvrir et lire le fichier depuis le dossier proxifié
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}Notre fonction personnalisée write se contente simplement d’écrire dans la table de remplacements.
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// toujours écrire dans les overrides
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}Enfin, nous enregistrons nos fonctions personnalisées dans FUSE.
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}Une implémentation réelle devrait prendre en charge l’intégralité de l’API FUSE, y compris readdir, getattr et lock, mais les fonctions seraient simplement très similaires à celles ci‑dessus. Pour chaque nouvelle requête de lint, nous pouvons simplement réinitialiser la map d’overrides pour ne contenir que les modifications de cette IA spécifique, ce qui est instantané. Si nous voulions nous prémunir contre une explosion de la consommation mémoire, nous pourrions aussi conserver la map d’overrides sur disque (avec un peu de travail de gestion supplémentaire).
Avec un contrôle parfait sur l’environnement, nous préférerions probablement implémenter cela comme un module noyau natif à la place, afin d’éviter le surcoût des changements de contexte supplémentaires entre l’espace utilisateur et le noyau introduits par FUSE. 14
…Mais : jardins clos
Sous Linux, le proxy de dossier FUSE fonctionne très bien, mais la plupart de nos utilisateurs utilisent macOS ou Windows, qui n’ont aucune implémentation FUSE intégrée. Malheureusement, livrer une extension de noyau est également hors de question : sur les Mac avec Apple Silicon, la seule façon pour un utilisateur d’installer une extension de noyau est de redémarrer l’ordinateur en maintenant une touche spéciale enfoncée pour entrer en mode de récupération, puis de rétrograder vers « Sécurité réduite ». Inlivrable !
Comme FUSE doit en partie s’exécuter dans le noyau, les implémentations FUSE tierces comme macFUSE souffrent du même problème : il est pratiquement impossible de les faire installer par les utilisateurs.
Il y a eu des tentatives pour contourner de façon créative cette restriction. Une approche consiste à prendre un système de fichiers en réseau que macOS prend en charge nativement (par exemple NFS ou SMB), et à placer une API FUSE en dessous. Il existe un serveur local open source, en guise de preuve de concept, avec une API de type FUSE construite au‑dessus de NFS, hébergé sur xetdata/nfsserve, et le projet propriétaire macOS-FUSE-t prend en charge des backends construits à la fois sur NFS et SMB.
Problème résolu ? Pas vraiment… Les systèmes de fichiers sont plus complexes que la simple lecture, écriture et énumération de fichiers ! Ici, Cargo se plaint parce que les versions antérieures de NFS, sur lesquelles est basée l’implémentation xetdata/nfsserve, ne prennent pas en charge le verrouillage de fichiers.

MacOS-FUSE-t est construit sur NFSv4 qui, lui, prend en charge le verrouillage de fichiers, mais le dépôt GitHub ne contient que trois fichiers qui ne sont pas du code source (Attributions.txt, License.txt, README.md), et a été créé par un compte GitHub au nom étrangement spécialisé macos-fuse-t, sans plus d’informations. De toute évidence, nous ne pouvons pas livrer des binaires venus de nulle part à nos utilisateurs… Les tickets ouverts indiquent également des problèmes plus fondamentaux avec l’approche basée sur NFS/SMB, principalement liés à des bugs du noyau d’Apple.
Que nous reste-t-il ? Soit une nouvelle approche créative, soit… de la politique ! Le long cheminement d’Apple, depuis plus d’une décennie, pour éliminer progressivement les extensions de noyau les a amenés à ouvrir de plus en plus d’API en espace utilisateur (comme DriverKit), et leur prise en charge intégrée d’anciens systèmes de fichiers a récemment été déplacée en espace utilisateur. Leur code MS-DOS open source fait référence à un framework privé appelé FSKit ici, ce qui semble très prometteur ! Il semble possible qu’avec un peu de politique, nous puissions les amener à finaliser et à publier FSKit pour les développeurs externes (ou peut-être le prévoient-ils déjà ?), auquel cas nous pourrions aussi avoir une solution au problème d’exécution sur macOS.
Questions ouvertes
Comme nous l’avons vu, le problème en apparence simple qui consiste à laisser des IA itérer sur le code en arrière-plan est en réalité assez complexe. Le shadow workspace a été un projet d’une semaine mené par une seule personne pour créer une implémentation répondant au besoin immédiat que nous avions d’afficher les lints à l’IA. À l’avenir, nous prévoyons de l’étendre pour résoudre aussi le problème d’exécutabilité. Quelques questions ouvertes :
-
Existe-t-il une autre façon de mettre en place le dossier proxy simple que nous imaginons, sans créer d’extension de noyau ni utiliser l’API FUSE ? FUSE essaie de résoudre un problème plus large (n’importe quel type de système de fichiers), et il semble donc plausible qu’il existe des API obscures sur macOS et Windows qui fonctionneraient pour notre dossier proxy, mais ne fonctionneraient pas pour une implémentation FUSE générale.
-
À quoi ressemble exactement la solution pour le dossier proxy sur Windows ? Est-ce que quelque chose comme WinFsp fonctionnerait tel quel, ou y a-t-il des problèmes d’installation, de performances ou de sécurité avec ça ? J’ai passé la majeure partie de mon temps à chercher comment mettre en place le dossier proxy sur macOS.
-
Il y a peut-être un moyen d’utiliser DriverKit sur macOS et de simuler un faux périphérique USB pour servir de dossier proxy ? J’en doute, mais je n’ai pas examiné l’API d’assez près pour pouvoir affirmer avec certitude que c’est impossible.
-
Comment pouvons-nous atteindre une indépendance au niveau réseau ? Une situation particulière à considérer est celle où l’IA veut déboguer un test d’intégration où le code est réparti entre trois microservices. Il est possible que nous devions faire quelque chose de plus proche d’une VM, même si cela demandera plus de travail pour garantir l’équivalence de tout l’environnement et de tous les logiciels installés.
-
Y a-t-il un moyen de créer un espace de travail distant identique à partir de l’espace de travail local de l’utilisateur, avec le moins de configuration possible de la part de l’utilisateur ? Dans le cloud, nous pourrions utiliser FUSE tel quel (ou même un module de noyau si souhaité pour des raisons de performance) sans avoir à gérer de considérations politiques, et nous pourrions aussi garantir l’absence de consommation mémoire supplémentaire pour l’utilisateur et une indépendance complète. Pour les utilisateurs qui se soucient moins de la confidentialité, cela pourrait être une bonne alternative. Une proto-idée serait une sorte de conteneur Docker déduit automatiquement en observant le système (peut-être en combinant l’écriture de scripts pour détecter ce qui tourne sur la machine et l’utilisation de modèles de langage pour écrire un Dockerfile).
Si vous avez de bonnes idées pour l’une de ces questions, veuillez m’envoyer un e-mail à arvid@cursor.com. De plus, si vous souhaitez travailler sur ce genre de sujets, nous recrutons.