Découverte dynamique du contexte
Les agents de codage transforment rapidement la manière dont les logiciels sont développés. Leur amélioration rapide provient à la fois de meilleurs modèles agentiques et d'une meilleure ingénierie du contexte pour les orienter.
L'infrastructure agent de Cursor, c'est-à-dire les instructions et les outils que nous fournissons au modèle, est optimisée individuellement pour chaque nouveau modèle de pointe que nous prenons en charge. Cependant, nous pouvons apporter des améliorations à l'ingénierie du contexte, par exemple dans la manière dont nous rassemblons le contexte et optimisons l'utilisation des jetons sur une longue trajectoire, qui s'appliquent à tous les modèles au sein de notre infrastructure.
À mesure que les modèles sont devenus meilleurs en tant qu'agents, nous avons obtenu de bons résultats en fournissant moins de détails au départ, ce qui permet à l'agent de récupérer lui-même un contexte pertinent plus facilement. Nous appelons ce schéma découverte dynamique du contexte, par opposition au contexte statique, qui est toujours inclus.
Fichiers pour la découverte dynamique du contexte
La découverte dynamique du contexte est bien plus économe en jetons, car seules les données nécessaires sont chargées dans la fenêtre de contexte. Elle peut également améliorer la qualité des réponses de l'agent en réduisant la quantité d'informations potentiellement déroutantes ou contradictoires dans la fenêtre de contexte.
Voici comment nous avons utilisé la découverte dynamique du contexte dans Cursor :
- Transformer de longues réponses d’outils en fichiers
- Référencer l’historique de conversation lors de la synthèse
- Prendre en charge le standard ouvert Agent Skills
- Charger efficacement uniquement les outils MCP nécessaires
- Considérer toutes les sessions de terminal intégrées comme des fichiers
1. Transformer les longues réponses d'outils en fichiers
Les appels d'outils peuvent augmenter considérablement la fenêtre de contexte en renvoyant une grande réponse JSON.
Pour les outils natifs de Cursor, comme l'édition de fichiers et la recherche dans la base de code, nous pouvons éviter le gonflement du contexte grâce à des définitions d'outils intelligentes et à des formats de réponse minimaux, mais les outils tiers (c'est-à-dire les commandes shell ou les appels MCP) ne bénéficient pas nativement du même traitement.
L'approche courante des agents de code consiste à tronquer les longues commandes shell ou les résultats MCP. Cela peut entraîner une perte de données, y compris des informations importantes que vous souhaitiez voir incluses dans le contexte. Dans Cursor, nous redirigeons plutôt la sortie vers un fichier et permettons à l'agent de le lire. L'agent appelle tail pour vérifier la fin, puis lit davantage s'il en a besoin.
Cela a permis de réduire les résumés inutiles lorsque l'on atteint les limites de contexte.
2. Référencer l’historique de chat pendant la synthèse
Lorsque la fenêtre de contexte du modèle arrive à saturation, Cursor déclenche une étape de synthèse pour donner à l’agent une nouvelle fenêtre de contexte contenant un résumé de son travail jusqu’ici.
Mais les connaissances de l’agent peuvent se dégrader après la synthèse, puisqu’il s’agit d’une compression avec perte du contexte. Il se peut que l’agent ait oublié des détails cruciaux concernant sa tâche. Dans Cursor, nous utilisons l’historique de chat comme fichiers pour améliorer la qualité de la synthèse.


Une fois la limite de la fenêtre de contexte atteinte, ou si l’utilisateur décide de lancer une synthèse manuellement, nous donnons à l’agent une référence au fichier d’historique. Si l’agent se rend compte qu’il a besoin de détails supplémentaires qui manquent au résumé, il peut parcourir l’historique pour les retrouver.
3. Prise en charge du standard ouvert Agent Skills
Cursor prend en charge Agent Skills, un standard ouvert pour étendre les agents de développement avec des capacités spécialisées. Comme pour les autres types de Rules, les Skills sont définis par des fichiers qui indiquent à l’agent comment exécuter une tâche spécifique à un domaine.
Les Skills incluent également un nom et une description qui peuvent être inclus en tant que « static context » dans le prompt système. L’agent peut ensuite effectuer une découverte de contexte dynamique pour sélectionner automatiquement les Skills pertinentes, en utilisant des outils comme grep et la recherche sémantique de Cursor.
Les Skills peuvent aussi regrouper des exécutables ou des scripts pertinents pour la tâche. Comme ce ne sont que des fichiers, l’agent peut facilement trouver ce qui est pertinent pour un Skill donné.
4. Charger efficacement uniquement les outils MCP nécessaires
MCP est utile pour accéder à des ressources sécurisées protégées par OAuth. Il peut s’agir de journaux de production, de fichiers de design externes ou de contexte et de documentation internes pour une entreprise.
Certains serveurs MCP incluent de nombreux outils, souvent avec de longues descriptions, ce qui peut considérablement gonfler la fenêtre de contexte. La plupart de ces outils ne sont jamais utilisés, même s’ils sont toujours inclus dans le prompt. Ce problème s’aggrave si vous utilisez plusieurs serveurs MCP.
Il n’est pas réaliste de s’attendre à ce que chaque serveur MCP soit optimisé pour cela. Nous pensons que c’est la responsabilité des agents de code de réduire l’usage du contexte. Dans Cursor, nous prenons en charge la découverte dynamique du contexte pour MCP en synchronisant les descriptions d’outils dans un dossier.1
L’agent ne reçoit désormais qu’une petite portion de contexte statique, incluant les noms des outils, ce qui l’incite à rechercher les outils lorsque la tâche l’exige. Dans un test A/B, nous avons constaté que, pour les exécutions qui appelaient un outil MCP, cette stratégie réduisait le nombre total de tokens utilisés par l’agent de 46,9 % (statistiquement significatif, avec une forte variance selon le nombre de MCP installés).
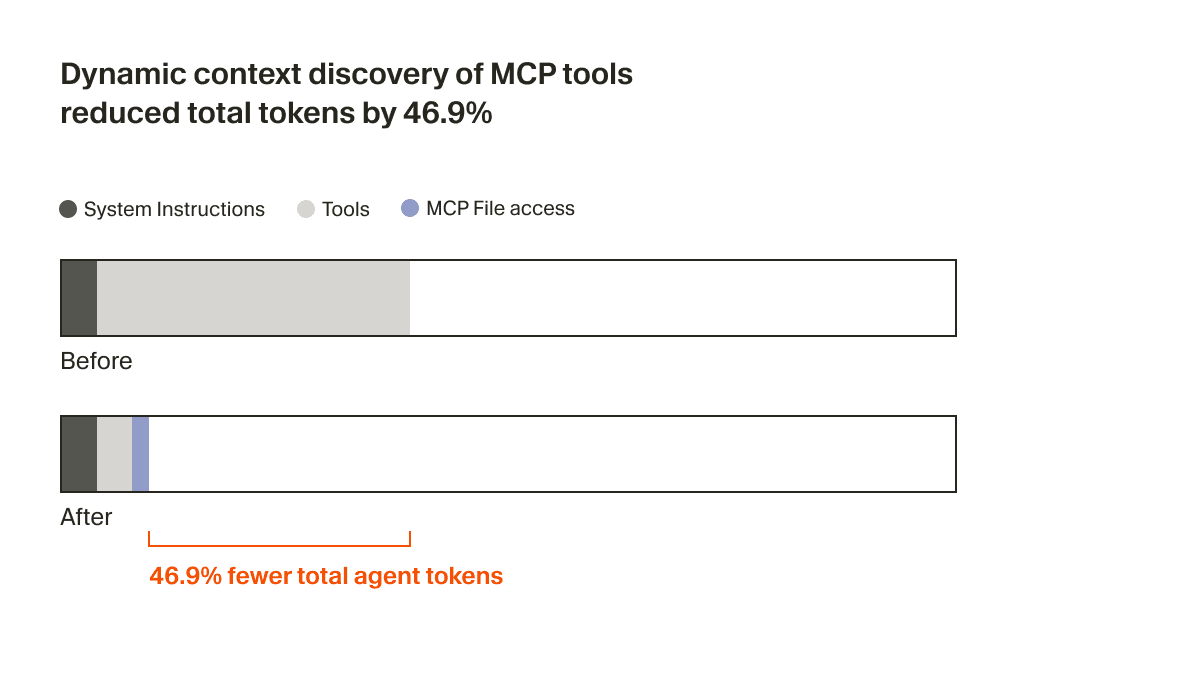
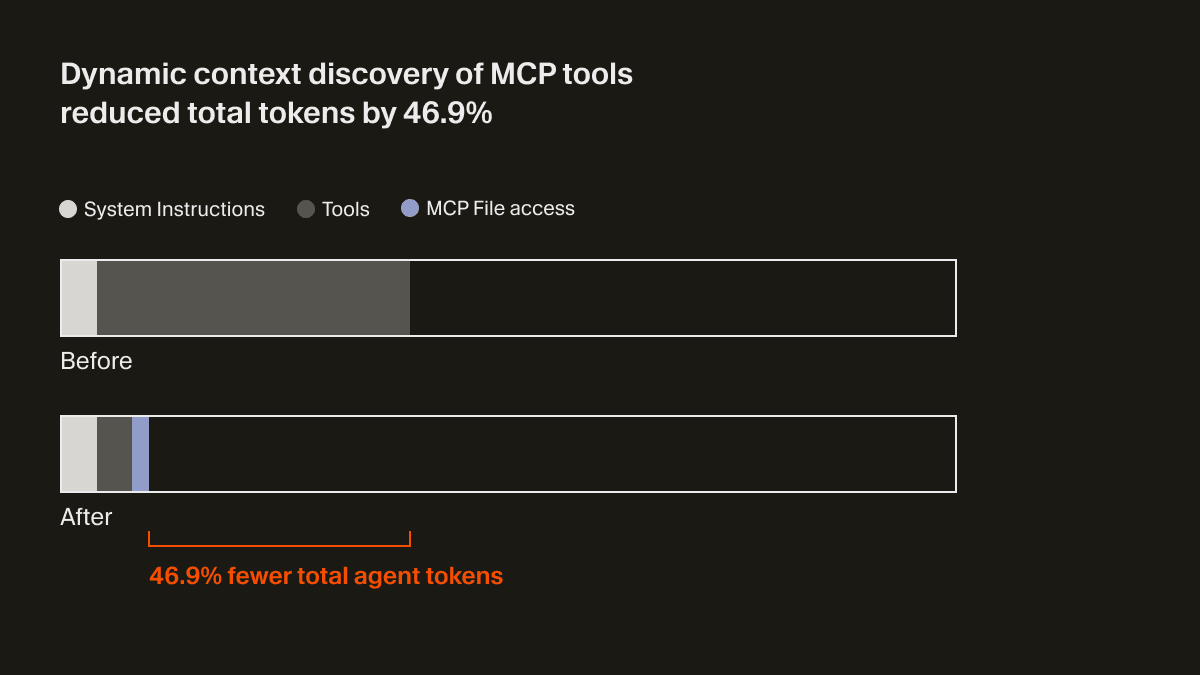
Cette approche basée sur les fichiers permet également de communiquer à l’agent l’état des outils MCP. Par exemple, auparavant, si un serveur MCP nécessitait une nouvelle authentification, l’agent oubliait complètement ces outils, laissant l’utilisateur perplexe. Désormais, il peut effectivement indiquer à l’utilisateur, de manière proactive, qu’il doit se réauthentifier.
5. Traiter toutes les sessions de terminal intégré comme des fichiers
Plutôt que d'avoir à copier/coller la sortie d'une session de terminal dans l'entrée de l’Agent, Cursor synchronise désormais les sorties du terminal intégré avec le système de fichiers local.
Cela permet de poser facilement la question « Pourquoi ma commande a-t-elle échoué ? » et permet à l’Agent de comprendre à quoi vous faites référence. Comme l'historique du terminal peut être long, l’Agent peut utiliser grep uniquement sur les sorties pertinentes, ce qui est utile pour les journaux d'un processus long, comme un serveur.
Cela reflète ce que voient les agents de développement en ligne de commande, avec les précédentes sorties du shell dans le contexte, mais récupérées dynamiquement plutôt qu'injectées statiquement.
Des abstractions simples
Il n'est pas certain que les fichiers seront l'interface finale pour les outils basés sur des LLM.
Mais à mesure que les agents de programmation s'améliorent rapidement, les fichiers se sont révélés être une brique de base à la fois simple et puissante, et un choix plus sûr qu'une abstraction supplémentaire qui ne peut pas entièrement anticiper l'avenir. Restez connectés, nous aurons beaucoup d'autres avancées passionnantes à partager dans ce domaine.
Ces améliorations seront déployées pour tous les utilisateurs dans les prochaines semaines. Les techniques décrites dans cet article de blog sont le fruit du travail de nombreux employés de Cursor, notamment Lukas Moller, Yash Gaitonde, Wilson Lin, Jason Ma, Devang Jhabakh et Jediah Katz. Si vous êtes intéressé par la résolution des tâches de programmation les plus difficiles et ambitieuses à l'aide de l'IA, nous serions ravis d'avoir de vos nouvelles. Contactez‑nous à l'adresse hiring@cursor.com.
- Nous avons envisagé une approche de recherche d'outils, mais cela aurait dispersé les outils dans un index plat. À la place, nous créons un dossier par serveur, en gardant les outils de chaque serveur regroupés de manière logique. Quand le modèle répertorie un dossier, il voit tous les outils de ce serveur ensemble et peut les comprendre comme une unité cohérente. Les fichiers permettent également des recherches plus puissantes. L'agent peut utiliser tous les paramètres de
rgou mêmejqpour filtrer les descriptions d'outils. ↩