使用影子工作区进行迭代
有一种注定失败的做法:把几个相关文件粘贴进一个 Google Doc,把链接发给你最喜欢的、但对你的代码库一无所知的 p60 软件工程师,然后让他在那个文档里完整且正确地实现你的下一个 PR。
让一个 AI 做同样的事,它也会——毫不意外地——失败。
但如果你给他们远程访问你的开发环境的权限,让他们可以看到 lint、跳转到定义、运行代码,那你确实可以指望他们多少能帮上点忙。
我们认为,让 AI 为你写更多代码的关键之一,是让它能够在你的开发环境中进行迭代。但如果天真地让 AI 在你的文件夹里随意操作,结果只会是一片混乱:想象一下,你刚写好一个需要大量推理的函数,就被 AI 覆盖掉了;或者你正要运行程序,却发现 AI 插入了无法编译的代码。要真正有用,AI 的迭代必须在后台进行,而不会影响你的编码体验。
为此,我们在 Cursor 中实现了我们称之为 影子工作区 (shadow workspace) 的机制。在这篇博客文章中,我会先概述我们的设计标准,然后介绍目前在 Cursor 中已经存在的实现方式 (一个隐藏的 Electron 窗口) ,以及我们未来希望将它发展到的形态 (一个内核级文件夹代理) 。

设计标准
我们希望 shadow workspace(影子工作区)能达到以下目标:
-
LSP 可用性:AI 应该能看到自己改动产生的 lint 提示,能够跳转到定义,更广义地说,能够与 language server protocol(语言服务器协议,LSP)的各个部分进行交互。
-
可运行性:AI 应该能够运行自己的代码并查看输出结果。
我们一开始重点关注的是 LSP 可用性。
这些目标需要在满足以下要求的前提下实现:
-
独立性:用户的编码体验必须不受影响。
-
隐私:用户的代码应该是安全的(例如全部保存在本地)。
-
并发性:多个 AI 应该能够并行地完成各自的工作。
-
通用性:它应该适用于所有语言和所有工作区配置。
-
可维护性:实现时应尽量减少代码量,并让相关代码尽可能易于隔离。
-
速度:任何地方都不应该出现长达一分钟的延迟,并且需要有足够的吞吐量来支撑数百个 AI 分支实例。
这些要求在很大程度上反映了为十多万用户构建代码编辑器的现实情况。我们非常不希望对任何人的编码体验产生负面影响。
实现 LSP 可用性
在底层语言模型固定不变的前提下,让 AI 为其编辑结果获取 lint,是提升代码生成效果最有影响力的方法之一。lint 不仅可以帮助把 90% 可工作的代码提升到 100% 完全可用的代码,还在上下文受限的场景中非常有用——当 AI 需要在第一次尝试时对要调用的方法或服务做出有根据的猜测时,lint 能发挥巨大作用。lint 还能帮助识别那些 AI 需要请求更多信息的地方。

要实现 LSP 可用性,其实比实现可运行性简单得多,因为几乎所有语言服务器都可以在尚未写入文件系统的文件上运行(而且正如我们稍后会看到的,一旦引入文件系统,事情会变得困难不少)。所以我们先从这里开始!本着第五项需求“可维护性”的原则,我们首先尝试了最简单可行的方案。
看似简单但行不通的方案
Cursor 是从 VS Code fork 而来,这意味着我们已经可以非常方便地使用语言服务器。在 VS Code 中,每个打开的文件都由一个 TextModel 对象表示,它在内存中存储该文件的当前状态。语言服务器是从这些 TextModel 对象中读取内容,而不是从磁盘读取,这也是为什么它们可以在你输入的同时就提供补全和代码检查(而不是只在你保存时才运行)。
假设某个 AI 对文件 lib.ts 进行了编辑。我们显然不能直接修改与 lib.ts 对应的现有 TextModel 对象,因为用户此时也可能正在编辑这个文件。尽管如此,一个听上去相当合理的想法是:创建这个 TextModel 对象的副本,把这个副本与磁盘上的任何真实文件“解绑”,然后让 AI 在这个对象上进行编辑并从中获取代码检查结果。下面这 6 行代码就可以实现这一点。
async getLintsForChange(origFile: ITextModel, edit: ISingleEditOperation) {
// 创建内存中的 TextModel 副本并对其应用 AI 编辑
const newModel = this.modelService.createModel(origFile.getValue(), null);
newModel.applyEdits([edit]);
// 等待 2 秒,让语言服务器处理新的 TextModel 对象
await new Promise((resolve) => setTimeout(resolve, 2000));
// 从标记服务读取 lint 结果,该服务会根据语言内部路由到相应的扩展
const lints = this.markerService.read({ resource: newModel.uri });
newModel.dispose();
return lints;
}这个方案在可维护性方面无疑是出色的。在通用性上也很优秀,因为大多数人已经为自己的项目安装并配置好了合适的特定语言扩展。并发性和隐私性也可以轻松满足。
问题出在独立性。虽然复制一个 TextModel 意味着我们没有直接修改用户正在编辑的文件,但我们仍然会把这个复制文件的存在告诉语言服务器,也就是用户自己正在使用的那同一个语言服务器。这会带来各种问题:跳转到引用的结果里会包含我们的复制文件;像 Go 这种默认以多文件为作用域的命名空间的语言,会对复制文件和用户正在编辑的原始文件中所有函数的重复声明发出警告;而像 Rust 这种只有在文件被显式导入之后才会被包含进来的语言,则完全不会给出任何错误。类似的问题很可能还有很多。
这些问题听起来也许不大,但独立性对我们来说绝对是至关重要的。如果我们哪怕只是在很小的程度上影响了正常的代码编辑体验,无论我们的 AI 功能有多强,人们(包括我自己)都不会去用 Cursor。
我们也考虑过另外一些最终行不通的想法:在 VS Code 体系之外单独拉起我们自己的 tsc、gopls 或 rust-analyzer 实例;复制一份运行所有 VS Code 扩展的 extension host 进程,这样就可以分别运行两份每种语言服务器扩展;以及 fork 所有流行的语言服务器以支持同一个文件的多个不同版本,然后把这些扩展打包进 Cursor 中。
当前的 shadow workspace 实现
我们最终把 shadow workspace 实现成了一个隐藏窗口:每当某个 AI 想要查看自己写的代码对应的 lint 时,我们就为当前工作区启动一个隐藏窗口,然后在那个窗口中执行编辑操作,再把 lint 结果回传。我们会在不同请求之间重用这个隐藏窗口。这样在(几乎*)完全满足所有要求的同时(星号部分稍后解释),我们也获得了(几乎*)完整的 LSP 可用性。
图 4 展示了一个简化的架构示意图。
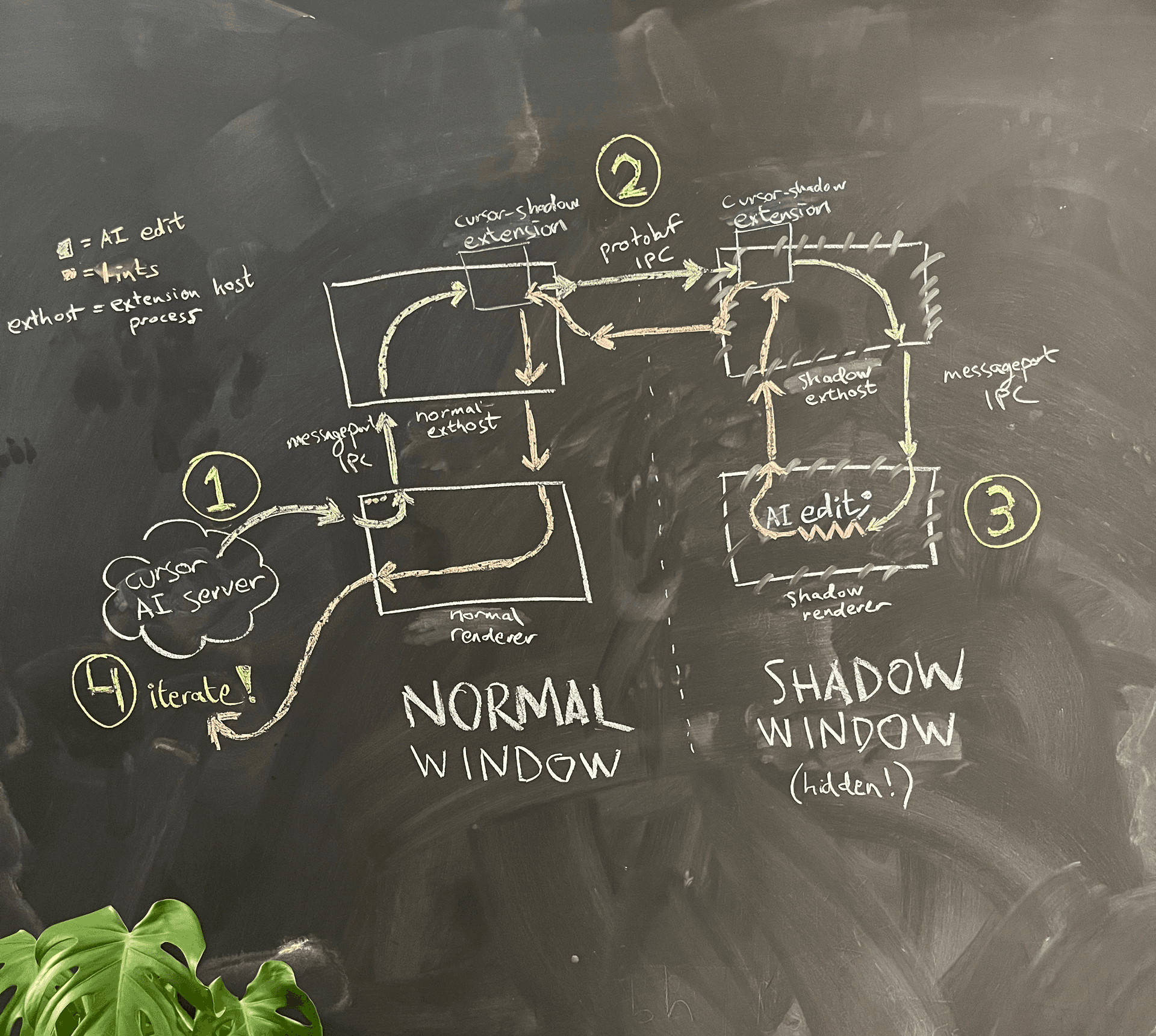
AI 运行在普通窗口的 renderer 进程中。当它想要查看自己写的代码对应的 lint 时,renderer 进程会请求 main 进程在同一文件夹下启动一个隐藏的 shadow 窗口。
由于 Electron 的沙箱机制,这两个 renderer 进程无法直接互相通信。我们考虑过的一种方案,是重用 VS Code 为 renderer 进程和 extension host 进程之间通信所实现的那套精心设计的 message port 创建逻辑,用它在普通窗口和 shadow 窗口之间建立我们自己的 message port IPC。出于对可维护性的担忧,我们选择了一个“小 hack”:重用现有的从 renderer 进程到 extension host 的 message port IPC,再在 extension host 与 extension host 之间通过一条独立的 IPC 连接通信。在这里,我们顺带塞进了一个体验改进:我们现在可以使用 gRPC 和我们非常喜欢的 buf 来通信,而不是 VS Code 自定义且有些脆弱的 JSON 序列化逻辑。
这个方案在可维护性上几乎是“自带优势”的,因为新增的代码与其他代码相互独立,而用于隐藏窗口的核心代码只有一行(在 Electron 中打开窗口时,只需要传一个 show: false 参数就能把它隐藏)。在通用性和隐私性方面,它也可以轻松满足要求。
幸运的是,“独立性”也同样满足!这个新窗口与用户完全解耦,因此 AI 可以在其中随意进行任何它想要的修改,并获取对应的 lint。用户完全不会察觉到这些操作的存在。
对 shadow 窗口的一个顾虑是:这个新窗口会非常直接地带来大约 2 倍的内存占用。我们通过限制允许在 shadow 窗口中运行的扩展、在 15 分钟无活动后自动杀掉该窗口,并且将其设计为“需要用户主动启用”的方式,来减轻这一影响。不过,这在并发方面仍然是个挑战:我们无法为每个 AI 都简单地启动一个新的 shadow 窗口。幸运的是,这里可以利用 AI 和人类之间一个关键的区别:AI 可以被暂停任意长时间而毫无察觉。具体来说,如果你有两个 AI,A 和 B,分别提出编辑序列 A1 接着 A2,以及 B1 接着 B2,你完全可以把这些编辑交错执行。shadow 窗口首先把整个文件夹状态重置到 A1,获取 lint 并返回给 A;然后再把整个文件夹状态重置到 B1,获取 lint 并返回给 B;之后再对 A2 和 B2 如法炮制。某种意义上,AI 在这点上更像是计算机进程(CPU 也以类似的方式在它们之间交错切换,而它们毫无“知觉”),而不是人类(人类有内在的时间感)。
把这些都组合在一起,我们得到了一套简单的 Protobuf API,供我们的后台 AI 用来细化自己的编辑,而完全不会影响用户体验。
前面承诺要解释的星号:某些语言服务器在报告 lint 结果之前,需要先把代码写入磁盘。最典型的例子是 rust-analyzer 语言服务器,它只是运行项目级别的 cargo check 来获取 lint 结果,并未与 VS Code 的虚拟文件系统集成(参见 这个 issue 作为参考)。因此,shadow workspace 目前尚不支持对 Rust 的 LSP 支持,除非用户使用的是已弃用的 RLS 扩展。
实现可运行性
可运行性是事情开始变得既有趣又复杂的地方。我们目前专注于为 Cursor 打造短时间尺度的 AI——比如在你使用函数的同时,在后台为你实现这些函数,而不是一次性生成整套 PR——因此我们暂时还没有实现可运行性。不过,思考如何实现它依然很有意思。
运行代码需要先把代码保存到文件系统中。很多项目还会产生基于磁盘的副作用(比如构建缓存和日志文件)。因此,我们不能再在与用户相同的文件夹中启动 shadow window。要让所有项目都具备完美的可运行性,我们还需要网络层面的隔离,但目前我们先专注于实现磁盘隔离。
最简单的思路:cp -r
最简单的思路是把用户的文件夹递归复制到一个 /tmp 目录中,然后在那里面应用 AI 的编辑、保存文件并在那里运行代码。对于下一次由另一个 AI 发起的编辑,我们会先执行一次 rm -rf,然后再进行一次新的 cp -r 调用,以确保影子工作区与用户的工作区保持同步。
问题在于速度:cp -r 非常慢。需要记住的是,为了能够运行一个项目,我们不仅需要复制源代码,还需要复制所有与构建相关的辅助文件。具体来说,我们需要复制 JavaScript 项目中的 node_modules、Python 项目中的 venv,以及 Rust 项目中的 target。即使是中等规模的项目,这些通常也是非常庞大的文件夹,这也就基本宣告了这种朴素的 cp -r 方法行不通。
符号链接、硬链接、写时复制
复制和创建大型文件夹结构不一定要特别慢!一个现成的例子是 bun,它在将已缓存的依赖安装到 node_modules 时,经常能在不到一秒内完成。在 Linux 上它使用硬链接,这很快,因为没有实际的数据移动。在 macOS 上,它使用的是 clonefile 系统调用,这是一个相对较新的接口,可以对文件或文件夹执行写时复制。
遗憾的是,对于我们中等规模的 monorepo,即使用一次 cp -c 的 clonefile 也要 45 秒才能完成。这太慢了,无法在每次 shadow 工作区请求之前都运行。硬链接风险较大,因为你在 shadow 文件夹中运行的任何东西,都可能意外修改原始仓库中的真实文件。符号链接也有类似问题,而且还有一个额外问题:它们对上层并不是透明的,这意味着往往需要额外配置(例如 Node.js 的 --preserve-symlinks 标志)。
我们可以想象,如果配合某种巧妙的记录机制来避免在每次请求前都重新复制文件夹,那么 clonefile(甚至普通的 cp -r)也有可能可行。为了保证正确性,我们需要监控用户文件夹自上次完整拷贝以来的所有文件更改,以及已拷贝文件夹中的所有文件更改,并在每次请求之前撤销后者并重放前者。每当任一侧的变更历史多到难以追踪时,我们就可以做一次新的完整拷贝并重置状态。这可能可行,但感觉很容易出错、非常脆弱,而且说实话,为了实现一个听起来如此简单的目标,这种方案显得有点丑陋。
我们真正想要的:内核级文件夹代理
我们真正想要的其实很简单:我们希望有一个影子文件夹 A′,在所有使用常规文件系统 API 的应用看来,与用户的文件夹 A 完全相同;同时还能快速配置一小组覆盖文件,这些文件的内容则从内存中读取。我们也希望对文件夹 A′ 的任何写入都被写入到内存中的覆盖存储中,而不是写入磁盘。简而言之,我们想要一个带有可配置覆盖项的代理文件夹,并且我们完全可以接受将这张覆盖表完全保存在内存中。接下来,我们就可以在这个代理文件夹内启动我们的影子窗口,从而实现真正的磁盘级隔离。
关键在于,我们需要对这种文件夹代理提供内核级支持,这样任意正在运行的代码都可以继续不加修改地调用 read 和 write 系统调用。一种做法是创建一个内核扩展 13,将其注册为内核虚拟文件系统中该影子文件夹的后端,并实现上述这些简单行为。
在 Linux 上,我们可以改在用户态完成这一点,利用 FUSE(“Filesystem in Userspace”)。FUSE 是一个内核模块,大多数 Linux 发行版默认已经包含,它会将文件系统调用转发到一个用户态进程。这使得实现文件夹代理变得更加简单。下面是一个文件夹代理的玩具实现,使用 C++ 展示。
首先,我们引入用户态的 FUSE 库,它负责与 FUSE 内核模块通信。同时,我们还定义目标文件夹(用户的文件夹)以及覆盖项的内存映射。
#define FUSE_USE_VERSION 31
#include <fuse3/fuse.h>
// 其他 include 文件...
using namespace std;
// 不希望修改的代理目标文件夹
string target_folder = "/path/to/target/folder";
// 要应用的内存覆盖映射
unordered_map<string, vector<char>> overrides;然后,我们定义一个自定义的 read 函数,先检查 overrides 中是否包含该路径;如果没有,就从目标目录读取。
int proxy_read(const char *path, char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 检查路径是否在覆盖表中
string path_str(path);
if (overrides.count(path_str)) {
const vector<char>& content = overrides[path_str];
// 如果在,返回覆盖内容
if (offset < content.size()) {
if (offset + size > content.size())
size = content.size() - offset;
memcpy(buf, content.data() + offset, size);
} else {
size = 0;
}
return size;
}
// 否则,从代理文件夹打开并读取文件
string fullpath = target_folder + path;
int fd = open(fullpath.c_str(), O_RDONLY);
if (fd == -1)
return -errno;
int res = pread(fd, buf, size, offset);
if (res == -1)
res = -errno;
close(fd);
return res;
}我们的自定义 write 函数只是简单地将内容写入 overrides 映射表中。
int proxy_write(const char *path, const char *buf, size_t size, off_t offset, struct fuse_file_info *fi)
{
// 始终写入覆盖映射表
string path_str(path);
vector<char>& content = overrides[path_str];
if (offset + size > content.size()) {
content.resize(offset + size);
}
memcpy(content.data() + offset, buf, size);
return size;
}最后,我们将自定义函数注册到 FUSE 中。
int main(int argc, char *argv[])
{
struct fuse_operations operations = {
.read = proxy_read,
.write = proxy_write,
};
return fuse_main(argc, argv, &operations, NULL);
}一个完整的实现需要覆盖整个 FUSE API,包括 readdir、getattr 和 lock,但这些函数会和上面那些非常相似。对于每一次新的 lint 请求,我们只需把 overrides map 重置为该特定 AI 的编辑即可,这个操作几乎可以瞬间完成。如果我们想确保不会出现内存暴涨,也可以把 overrides map 保存在磁盘上(需要做一些额外的管理工作)。
在对环境拥有完全控制权的情况下,我们更倾向于把这一机制实现为一个原生内核模块,以避免使用 FUSE 带来的额外用户态-内核态上下文切换开销。14
……但是:围墙花园
在 Linux 上,FUSE 文件夹代理工作得很好,但我们的多数用户使用的是 macOS 或 Windows,这两者都没有内置的 FUSE 实现。不幸的是,分发一个内核扩展也完全不现实:在搭载 Apple Silicon 的 Mac 上,用户安装内核扩展的唯一方式,是在按住特殊按键的同时重启电脑进入恢复模式,然后把安全性降级到“降低的安全性(Reduced Security)”。完全没法交付!
由于 FUSE 的一部分需要在内核中运行,像 macFUSE 这样的第三方 FUSE 实现,也遇到了同样几乎不可能指望用户去安装的问题。
人们曾尝试用一些有创意的方式绕过这一限制。一种做法是,先选用一个 macOS 原生支持的基于网络的文件系统(比如 NFS 或 SMB),然后在其之下放一层 FUSE API。有一个开源的本地服务器概念验证项目,基于 NFS 实现了一个类 FUSE API,托管在 xetdata/nfsserve;而闭源项目 macOS-FUSE-t 则支持基于 NFS 和 SMB 的后端。
问题解决了吗?并没有……文件系统远不止是读、写、列出文件这么简单!在这里,Cargo 报错是因为 xetdata/nfsserve 所基于的早期 NFS 版本不支持文件锁。

MacOS-FUSE-t 是基于 确实 支持文件锁的 NFSv4 构建的,但这个 GitHub 仓库里除了三个非源码文件(Attributions.txt、License.txt、README.md)什么都没有,而且是由一个用途可疑、仅此一用的用户名 macos-fuse-t 创建,除此之外再无更多信息。显然,我们不可能把来路不明的二进制文件发给用户……未关闭的 issue 还表明,这种基于 NFS/SMB 的方案存在更多根本性问题,大多与 Apple 的内核 Bug 有关。
那我们还剩下什么?要么是某种全新的创意方案,要么是再等 15 年……或者是政治!Apple 长达十年的逐步淘汰内核扩展的过程,促使他们开放了越来越多的用户态 API(例如 DriverKit),而他们对旧文件系统的内置支持最近也迁移到了用户态。他们开源的 MS-DOS 代码中,在这里引用了一个名为 FSKit 的私有框架,听起来非常有前景!感觉只要稍微做点“政治工作”,我们也许就能促使他们把 FSKit 最终定型并向外部开发者发布(或者他们已经在计划这么做?),到那时,我们或许也能找到一个解决 macOS 可运行性难题的方案。
未解決問題
如我們所見,讓 AI 在背景中反覆迭代程式碼這個看似簡單的問題,其實相當複雜。shadow workspace 是一個為期 1 週、由 1 人完成的專案,目標是實作一個方案,滿足我們當時「將 lints 顯示給 AI」的迫切需求。未來,我們打算擴展它,也一併解決可執行性(runnability)問題。以下是一些尚待解決的問題:
-
是否有其他方式能實作我們構想中的簡易 proxy 資料夾,而不需要建立 kernel extension 或使用 FUSE API?FUSE 嘗試解決的是一個更大的問題(任何類型的檔案系統),因此看起來有可能在 macOS 和 Windows 上存在某些較冷門的 API,可以滿足我們對資料夾 proxy 的需求,但又不適用於一般的 FUSE 實作。
-
在 Windows 上,proxy 資料夾的完整方案到底會是什麼樣子?像 WinFsp 這樣的東西可以直接拿來用嗎,還是會有安裝、效能或安全性方面的問題?我大部分時間都花在研究如何在 macOS 上做資料夾 proxy。
-
是否可能在 macOS 上使用 DriverKit,並模擬一個假的 USB 裝置來充當 proxy 資料夾?我覺得不太可能,但我還沒有仔細研究這個 API,還不足以有把握地說這是不可能的。
-
我們要如何達到網路層級的獨立性?一個具體的情境是:當 AI 想要除錯一個整合測試,而程式碼分散在三個 microservices 中時。有可能我們最後需要做一些更接近 VM 的東西,不過那樣會需要更多工作,才能確保整個環境設定與所有已安裝軟體的等價性。
-
有沒有辦法在使用者幾乎不需要進行任何設定的情況下,從使用者的本機 workspace 建立一個相同的遠端 workspace?在雲端,我們可以直接開箱使用 FUSE(或在有效能需求時,甚至用 kernel module),而不需要顧慮任何組織/政策層面的問題,同時也可以保證不額外佔用使用者的記憶體,並完全獨立。對於比較不在意隱私的使用者而言,這可能是個不錯的替代方案。一個初步的想法是:透過觀察系統,自動推斷出某種 docker container(也許可以結合撰寫腳本來偵測機器上正在執行的東西,再利用語言模型來產生 Dockerfile)。
如果你對上述任何一個問題有好的想法,請寄信到 arvid@cursor.com 告訴我。此外,如果你有興趣做這類工作,我們正在招募。